110 slides extracted.
Slide 1 — 0:04 (watch)
 | I'm Ben Eggers, and I work at OpenAI. First, can I have a volunteer from the front row? |
Slide 2 — 0:10 (watch)
 | What's your name? I get nervous when I speak, so if I'm talking too fast, please guide me. Thank you. |
Slide 3 — 0:20 (watch)
 | I'm Ben Eggers, and I work at OpenAI. Today, I will explain how nothing has changed about software development. |
Slide 4 — 0:28 (watch)
 | It's the same as it has always been. |
Slide 5 — 0:38 (watch)
 | Nothing has changed. First, let's take a poll. Please raise your hand if you have used an LLM to develop software. |
Slide 6 — 0:52 (watch)
 | How many people here feel that, a few months ago, we experienced a qualitative leap in model intelligence? How many would trust an LLM to develop all of their software? Let's discuss. |
Slide 7 — 1:04 (watch)
 | I have a personal question. How many of you are using MacBook Pros that can't connect to Wi-Fi after putting them to sleep and then reopening them? I've been struggling with that issue. Great. I'm Ben. |
Slide 8 — 1:14 (watch)
 | This is a picture of me speaking at Bug Bash last year. Behind me is a childhood photo that I used during my presentation last year. |
Slide 9 — 1:26 (watch)
 | I work on infrastructure at OpenAI. I was once the eighth highest seven-day trailing token user at OpenAI, with a spike large enough to get rate limited. I also have some hobbies. If you're interested in long-distance hiking, jazz, living abroad, or therapy, let's talk. |
Slide 10 — 1:44 (watch)
 | Before I begin this talk, I want to thank these individuals. If any of them apply to work with you, I encourage you to hire them immediately. They have significantly influenced my thinking on the ideas presented in this talk and have made me a better engineer. These individuals are some of my engineering heroes, most of whom work at OpenAI. I wouldn't feel right giving this talk without acknowledging them and expressing my appreciation for their contributions. |
Slide 11 — 2:14 (watch)
 | Someone very wise once told me that the trick to giving a good talk is to first tell the audience what you’re going to tell them, then tell them, and finally tell them what you told them. So, here’s what I’m going to tell you: all of the hard parts of building software are still present and remain challenging. They are the same as they have always been. We will discuss this in two parts. First, I assert that writing code is actually the hard part of software development, but not for the reasons you might think. |
Slide 12 — 2:26 (watch)
 | In part two, we will discuss how agents shift the work and influence your thinking about it, but they do not eliminate the need for that work. |
Slide 13 — 2:32 (watch)
 | All the challenging aspects of software engineering remain unchanged. |
Slide 14 — 2:44 (watch)
 | I added this after Will's wonderful opening keynote this morning. He mentioned a 50-50 split between writing code and testing. I propose that it's more accurately represented as 40% thinking, 10% writing code, and 50% testing. This illustrates the direction of my argument. |
Slide 15 — 2:54 (watch)
 | I also want to provide a disclaimer. |
Slide 16 — 2:58 (watch)
 | I am referring to deep and narrow systems, which have a reasonably limited API surface area but significant implementation complexity. This includes databases, file systems, and infrastructure. |
Slide 17 — 3:14 (watch)
 | We are not discussing web portals and applications that typically have a broader feature surface. In these cases, each feature does not have as many deep implications for the architecture of the rest of the system. |
Slide 18 — 3:22 (watch)
 | I wouldn't say this is untrue for broad, high surface area systems. However, I have much less experience working on them, so I don't feel qualified to comment extensively. |
Slide 19 — 3:30 (watch)
 | I believe I am somewhat qualified to discuss the left type of systems, so that will be our focus today. |
Slide 20 — 3:36 (watch)
 | Many of you who attended Bug Bash last year may recall that I really enjoy games. Last year, the game was Guess the Impact. This year, the game is Guess What the Agent Gave Me. |
Slide 21 — 3:48 (watch)
 | I will describe a system and share the prompt I used for the agent. Then, you will guess the outcome. |
Slide 22 — 3:56 (watch)
 | Let's practice. |
Slide 23 — 4:02 (watch)
 | I wanted to create a Rust drop-in replacement for Python's RE module. Regular expressions present significant implementation complexity, and there is a clear correctness oracle in the Python RE module. It seems feasible to achieve better performance. |
Slide 24 — 4:18 (watch)
 | Python's RE module is primarily written in Python. This presents an interesting problem to explore in the context of autonomous software engineering. |
Slide 25 — 4:26 (watch)
 | I built a harness with an essentially empty repository that operated on a while loop. |
Slide 26 — 4:38 (watch)
 | Every four or five iterations, the system would instantiate a Codex instance and set a goal, such as picking something up and moving closer to it. Additionally, every fifth or sixth iteration, an orchestrator agent could modify the agent harness. The while loop was straightforward; it simply called the Python file that the orchestrator agent could manipulate. |
Slide 27 — 4:52 (watch)
 | So my question is, what do you think happened here? A Rust wrapper for Python would be even better than what I have. Do we have any other guesses? |
Slide 28 — 5:12 (watch)
 | One million lines. While that number is low, it is morally correct. There are many markdown documents, and that is correct as well. |
Slide 29 — 5:26 (watch)
 | The first thing I noticed after a few weeks was that it had created manifests, each containing hundreds of thousands of lines of JSON. These were essentially test cases, highly specific in nature, indicating that certain elements should match and tagged with numerous keywords and features. The result was overwhelming and poorly organized. |
Slide 30 — 5:50 (watch)
 | I SSH'd in and decided to experiment with autonomous software engineering instead of directly instructing the agent to modify the code. I attempted to change the harness by specifying not to use JSON. As a result, it converted all the file types to Python and implemented a manifest equals function. This repository is available on GitHub for review. Additionally, it generated a single 24,000-line Rust crate. |
Slide 31 — 6:18 (watch)
 | You might think that's a lot, but when you look at the file percentages, it becomes clearer. It created reports that were initially in JSON format but then converted to PY. One notable report is 6.47 megabytes in size. We ended up with these large JSON files containing numerous test cases, which were likely tested. The output included reports detailing the results of every single test. |
Slide 32 — 6:36 (watch)
 | This isn't exactly what I envisioned. I still believe this idea has potential, but I haven't had the time to pursue it further. That concludes our game section. We have a couple more of these coming up. |
Slide 33 — 6:44 (watch)
 | Part one. |
Slide 34 — 6:46 (watch)
 | Writing code has always been where the most challenging aspects arise. |
Slide 35 — 6:52 (watch)
 | My claim is that the bottleneck was never typing, which I believe is an uncontroversial assertion. If you're in this room, you likely type at least 60, probably 80, or even 100 words per minute. When you calculate the number of lines of code produced per day, it's clear that typing is not the bottleneck. |
Slide 36 — 7:10 (watch)
 | Code is relatively inexpensive, even at typing speed. I assert that code has historically been relatively cheap as well. |
Slide 37 — 7:26 (watch)
 | My rule of thumb for a productive day or week was shipping a couple thousand lines of code, which translates to about 400 or 500 lines per day, assuming I had six hours of deep focus time. However, the challenge lies not in the typing itself but in the design discovery, integration, and correctness processes that accompany writing those 2,000 or 400 lines of code. I assert that these aspects remain the hard part of software engineering. |
Slide 38 — 7:50 (watch)
 | This slide features a sci-fi book cover style image of someone writing code. Writing code used to require deep thought about the intended outcome. In today's environment, where you can quickly generate prompts like "make it better" or "make no mistakes," we are not reflecting as critically on our objectives. The process of coding used to force us to discover the shape of the problem. |
Slide 39 — 8:14 (watch)
 | We've all experienced the frustration of struggling with a piece of code, only to suddenly realize that a component should be located elsewhere or that our database indices are incorrect. If you're in this room, you've likely been writing code with LLMs and have had that "aha" moment when you recognize that the shape of the problem differs from your initial understanding. |
Slide 40 — 8:28 (watch)
 | It also forced us to turn those boundaries into contracts. In an era where you can easily rewrite your entire API contract, that is no longer the case, though it certainly used to be. Perhaps most importantly, and this is often under-discussed, you notice the unusual issues before anyone else. Will, in his talk this morning, claimed that humans have always been unreliable and that AI agents are not necessarily less reliable. I agree with this; while AI is improving, it seems that there was something qualitatively significant about the fact that a human thoughtfully considered every single line of code. Now, it feels like we are in an era where, because a human is not deeply analyzing every line of code, we have lost a critically load-bearing aspect of quality assurance for our software. |
Slide 41 — 9:12 (watch)
 | Humans played a crucial role in assessing whether something was correct, understanding the shape of the problem, and defining the API contracts. Writing the code itself was often the least interesting part of the process. |
Slide 42 — 9:26 (watch)
 | When writing an algorithm, such as an inverted index, the act of coding itself is not necessarily boring. However, if we frame coding in these terms, filling in the code often becomes the least interesting part. It's akin to setting up all the boxes and then simply coloring them in. |
Slide 43 — 9:38 (watch)
 | The slowness was indeed load-bearing. I asked our new image model to provide an illustration of slowness being load-bearing, and this is the result I received. |
Slide 44 — 9:50 (watch)
 | When you constantly use these interfaces, you become acutely aware of their shortcomings. As you wire paths end-to-end, you notice the missing cases. You might realize that two cases are actually the same, or that you should handle a specific error case. This requires careful consideration of all possible scenarios, whereas an LLM is more likely to make mistakes. |
Slide 45 — 10:04 (watch)
 | When writing your queries, it's crucial to consider how you structure your indices and how your scans operate, especially for those interested in databases. |
Slide 46 — 10:22 (watch)
 | The key point is that you need to think critically about your actions, especially regarding testing. When writing tests, we have all learned the common wisdom to focus on your interfaces rather than the implementation. You should consider the interface and the potential edge cases. This approach to testing remains effective, but when a human conducts it, you can be very deliberate about your intent. |
Slide 47 — 11:00 (watch)
 | I claim that there used to be a natural equilibrium where the speed of writing code matched our ability to reason about it. Generally, people would not create code they didn't understand, or if they did, it was much more limited than it is today. |
Slide 48 — 11:14 (watch)
 | I truly believe that during the golden era of human software engineering, code production was slow enough that we thought more critically about it, resulting in better outcomes. Today, the term "slop" is commonly used, and there's a reason for that: humans generally produce less slop, though not none. I recognize the skepticism, but I want to challenge the notion that software engineering has become stochastic due to LLMs. |
Slide 49 — 11:58 (watch)
 | Software engineering has always been stochastic. If you've ever managed a project with three interns or a team of new graduates, you understand this reality. The output can vary significantly; you might receive 100 lines of code or 2,000, and their quality can be unpredictable. This isn't a criticism of inexperienced software engineers; it's simply a fact. You can never outsource work and expect it to match the quality of what you envisioned. The results will not align perfectly with your expectations when you delegate tasks. |
Slide 50 — 12:26 (watch)
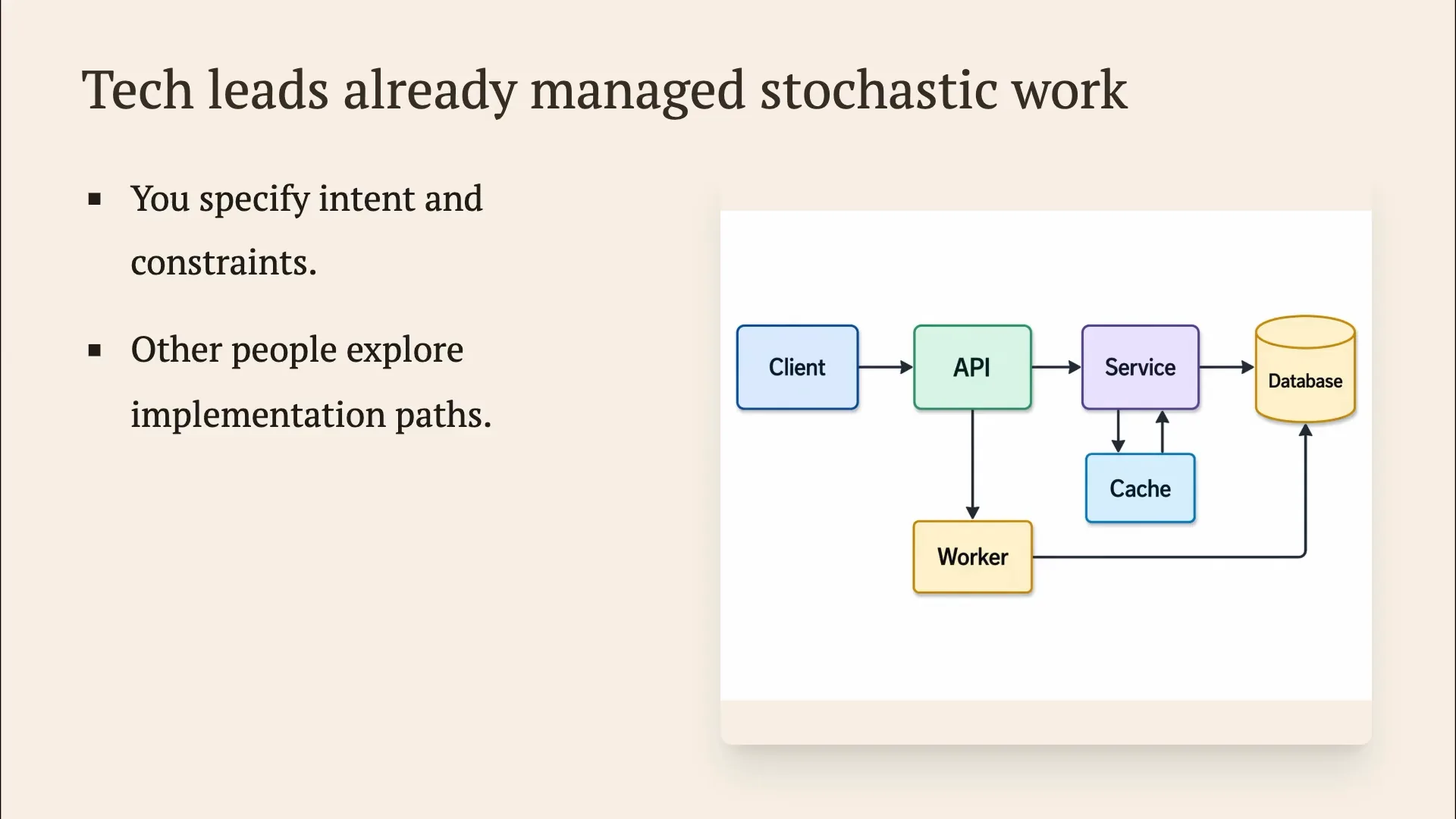 | As a tech lead, you specify the constraints and overall architecture of the system. You often don't need to fill in every detail, as long as the interfaces are implemented, you have confidence in your tests, and the system functions correctly. While code reviews are important, you don't need to understand every line of code or service, provided you have team members who do and you trust the overall architecture. Your focus can be on data storage, service communication, and ensuring that interfaces are correct with good type definitions. This allows you to believe that your system operates as intended, although this may not hold true for particularly complex systems. |
Slide 51 — 13:14 (watch)
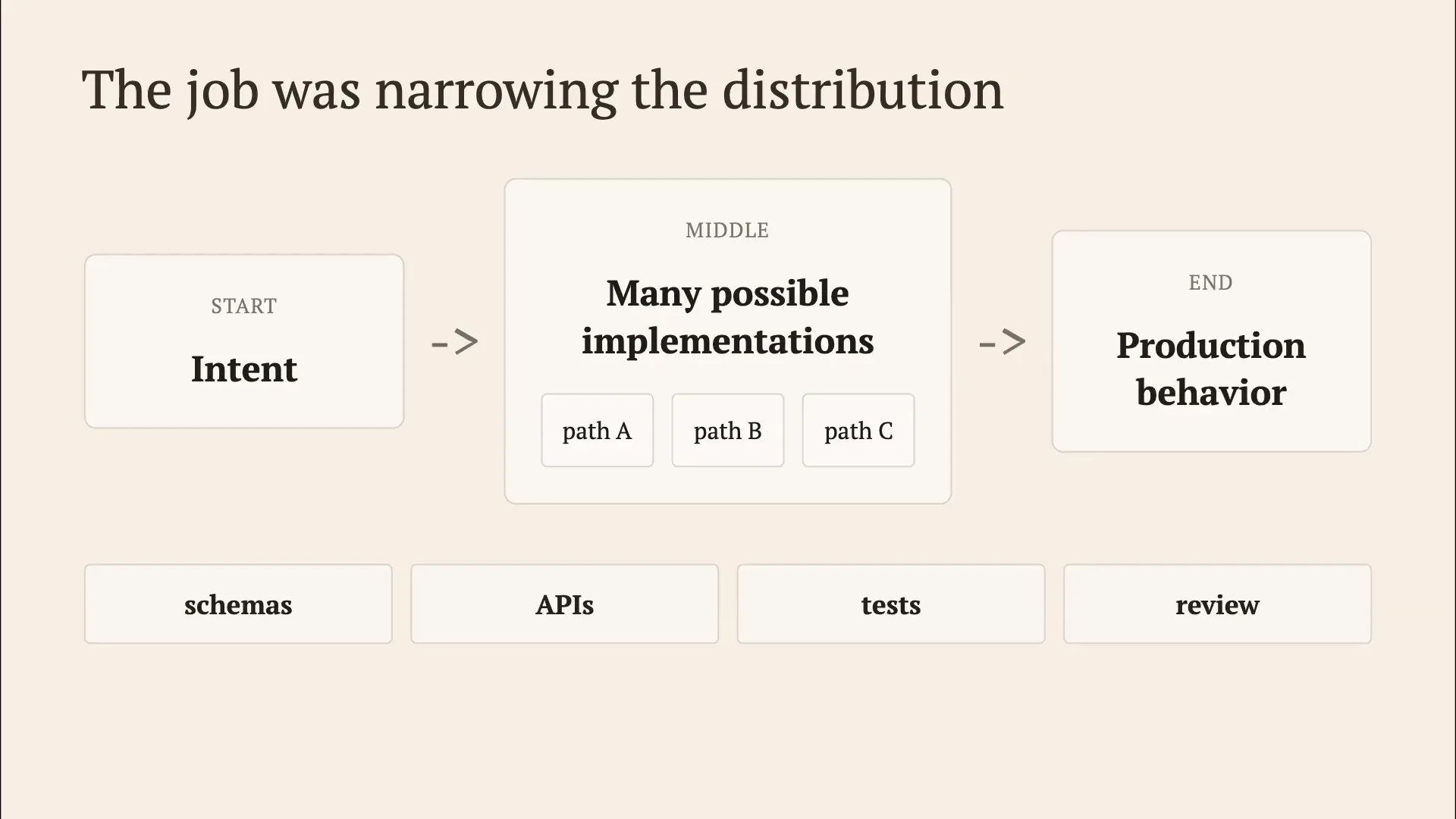 | We've encountered numerous database issues, and many of us have experienced frustrating database bugs. I argue that this reflects a stylized version of what a tech lead did during the golden era of software engineering. The primary responsibility was to narrow the distribution of possibilities. You would begin with your intent, evaluate various implementations, and select one. To refine this process, the focus was on schemas, APIs, tests, and reviews, rather than on the code within a single module. |
Slide 52 — 13:22 (watch)
 | In summary, the old coding loop enforced design thinking. |
Slide 53 — 13:34 (watch)
 | Slowness acted as a critical rate limiter, and we have always been engaged in stochastic software engineering. While not every individual may have practiced this approach, software engineering at a large scale has fundamentally been a stochastic process. Now, let's play another game. |
Slide 54 — 13:58 (watch)
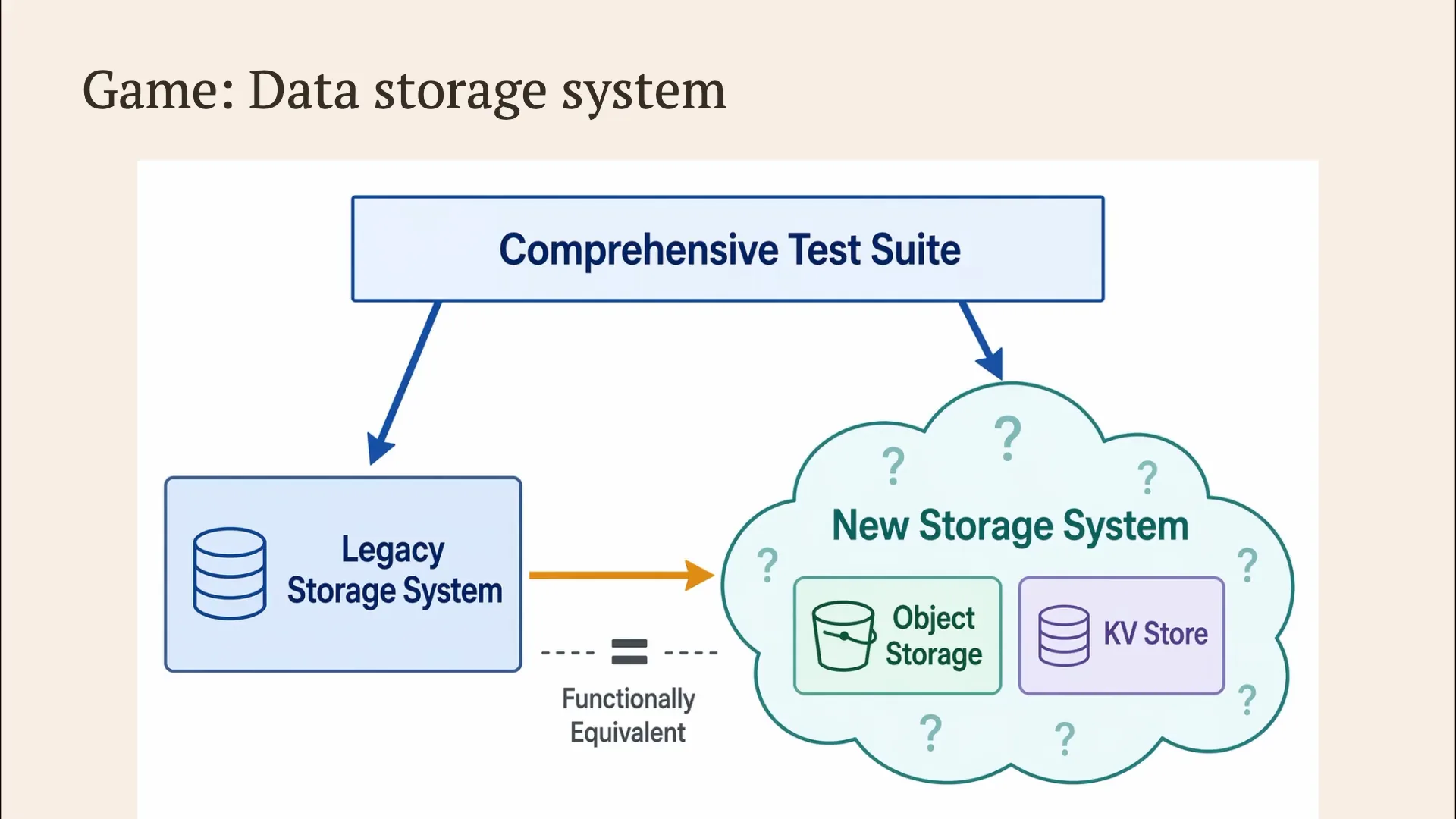 | We have a comprehensive test suite and a legacy storage system that we find unsatisfactory due to its poor performance. We decided to build a better version using modern primitives, specifically object storage and a key-value store provided by OpenAI. We set up the comprehensive test suite and ran it against the legacy storage system, which passed. Then, we implemented an agent to optimize the system. |
Slide 55 — 14:16 (watch)
 | The design of the harness is not particularly noteworthy. We implemented an agent hill climb to get everything functioning, and after a few weeks, it was operational. My question is, what do you think we achieved? Did it interact with the old storage system? |
Slide 56 — 14:50 (watch)
 | No, it was a better sandbox than that, although it would be amusing if it were just a large S3 bucket. We actually had one key and one value. It worked fine on my machine. Did it perform better? Locally, it performed adequately, but when we deployed it, we were puzzled by its behavior. This is particularly amusing because this type of bug is one that a human would almost never create. |
Slide 57 — 15:08 (watch)
 | Humans do all sorts of unpredictable things, but this bug is difficult to envision as something a human would create. When you want to insert a collection of keys and values into a key-value store, this is not the typical implementation approach you would choose. |
Slide 58 — 15:16 (watch)
 | I haven't had time to review the logs of the harness runs, but I suspect that the issue arose from a performance hack implemented due to the small data scale. Subsequent iterations likely failed to address it, leading to the assumption that it was acceptable as is. |
Slide 59 — 15:38 (watch)
 | I'm not going to address it because that has happened frequently in my experience. Part two: agents facilitate the work, but they do not eliminate it. You may have noticed that models cross the usefulness threshold. |
Slide 60 — 15:44 (watch)
 | In comparing GPT-4.1 to GPT-4.6, GPT-4.1 performs significantly worse across all benchmarks. |
Slide 61 — 15:54 (watch)
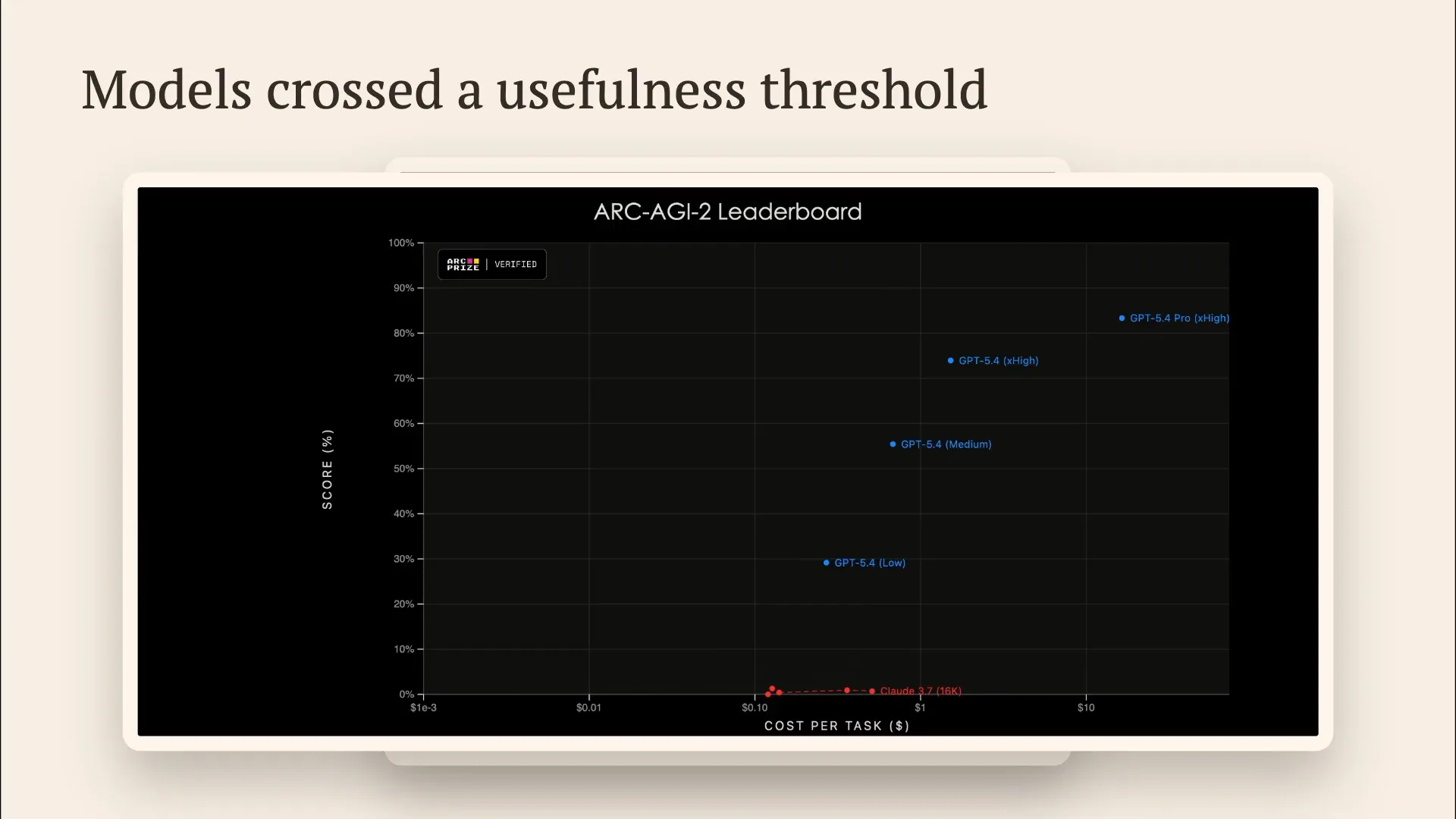 | There is also a qualitative difference between GPT-3.7 and GPT-5.4, which is another unfair comparison. Previous generations of models struggled with RKGI2, while current generations can handle it effectively. |
Slide 62 — 16:12 (watch)
 | We have model generations that were trained on the training set, but I can't shake the feeling that these models have crossed a qualitative threshold of usefulness. They inspire more trust and demonstrate improved performance. This shift has led to discussions about agentic engineering and the intelligence explosion. |
Slide 63 — 16:22 (watch)
 | I feel that a model is often better at my job than I am, and this change occurred about three months ago. |
Slide 64 — 16:42 (watch)
 | I still maintain that models write better code when you do the lead work. You need to define what success looks like. For instance, provide a comprehensive test suite and outline the shape of the solution. You can't simply instruct it to build something and expect improvements. Additionally, you must determine in advance how you will assess whether the change was effective; guessing is not sufficient. |
Slide 65 — 16:54 (watch)
 | These are the same principles that humans need to build good software, which supports my claim that software engineering has not changed. I consider these factors when mentoring an intern, writing notes for myself, or when I sit down to work. |
Slide 66 — 17:10 (watch)
 | I need to consider what the desired outcome looks like and how to achieve it effectively. The first step is to make decisions with intent. |
Slide 67 — 17:14 (watch)
 | You define the desired behavior changes, specify what must remain functional, and identify the trade-offs you are willing to accept. |
Slide 68 — 17:26 (watch)
 | For example, avoid placing all keys and values in a singleton within the key-value store. Instead, utilize the key-value store effectively. There is potential for a separate talk on this topic, as prompts can resemble mathematical expressions. Ultimately, you need to be extremely specific and detailed in your prompts, distinguishing between terms like "for any," "for all," and "choose one such that." |
Slide 69 — 17:50 (watch)
 | These details are significant in implementation. As we interact with code and computers more through prose, prompts are likely to become increasingly mathematical across the industry. While I believe there is an interesting discussion to be had on this topic, it is not the focus of this presentation. |
Slide 70 — 18:02 (watch)
 | Design is perhaps the most important slide in this entire deck, as it reflects what I have learned about developing with agents. |
Slide 71 — 18:10 (watch)
 | I write all of my schemas by hand. For a very simple schema, I might use an agent, but I have spent a week struggling with a 300-line Prisma schema because it needs to be precise. I do not let the agent handle it; I write my APIs and interfaces by hand for the same reasons. |
Slide 72 — 18:20 (watch)
 | I also have coworkers who write all of their tests by hand, which I find surprising. That aspect of software engineering can be quite challenging. |
Slide 73 — 18:32 (watch)
 | However, I know people who swear by writing tests by hand. |
Slide 74 — 18:36 (watch)
 | There is an interesting argument to be made that unit testing is becoming obsolete. We've observed AI-generated unit tests that assert unusual values and provide little meaningful information. |
Slide 75 — 18:46 (watch)
 | If you are writing unit tests yourself, they can be useful because you, as the human, ensure their correctness. However, simply instructing the AI to add more tests is generally not helpful. This topic could warrant its own discussion, but it is not the focus of this talk. |
Slide 76 — 19:02 (watch)
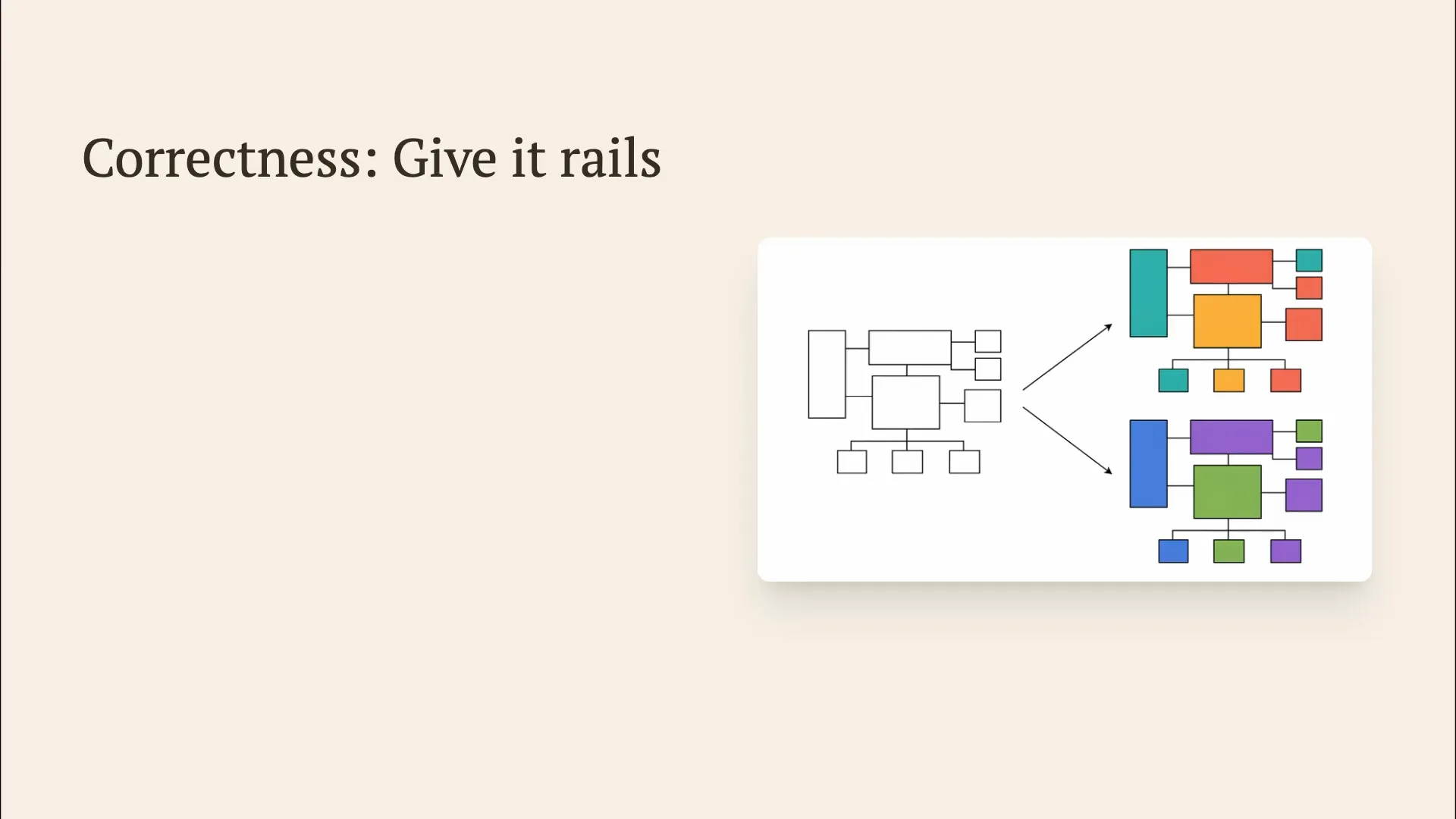 | Correctness is essential. You need to provide guidance, such as a system diagram that outlines your requirements. The specifics, like the color of the boxes or the programming language used, are not my concern. What matters is that the implementation details are correct, as they have generally been less interesting. |
Slide 77 — 19:16 (watch)
 | If you have a provable correctness harness, the aesthetics of the code become less important. You specify which data models are immutable and provide a comprehensive test harness. |
Slide 78 — 19:28 (watch)
 | Always implement tests in a different context. This is an important technique. When you ask an AI to write some code and then request unit tests for it, the AI retains the context of the code it just generated. The most effective workflow I've found is to separate these tasks: first, write your interfaces and a set of tests, then instruct the AI not to modify the tests while making the code functional. |
Slide 79 — 19:46 (watch)
 | The only AI-driven, test-driven development approach that I find effective for unit tests is to separate the interfaces and write extensive tests, then focus on making the code functional without altering the tests. |
Slide 80 — 19:50 (watch)
 | In summary, here is a checklist for managing your army of AI agents. |
Slide 81 — 20:02 (watch)
 | Clearly define the desired behavior change in prose and mathematics. Implement your schemas and interfaces manually or with an agent, which are generally not large relative to the system. Create tests for the change, and then allow an agent to fill in the gaps. This process resembles managing your sleepy Monday 8 AM self. |
Slide 82 — 20:20 (watch)
 | That brings us to our final game, Contrafact. I built a practice journal for tracking jazz practice. |
Slide 83 — 20:28 (watch)
 | The details of the app are not particularly specific, but the key point is that it is an application rather than a deep system. This is a relatively shallow system with many screens. |
Slide 84 — 20:44 (watch)
 | I developed my storage models, feature views, and domain model patterns from scratch. I established all the core code-based structures and patterns to ensure they were complete and comprehensive. Then, I would identify a feature I wanted, implement it, and verify that it worked. I repeated this process multiple times, and eventually, I wondered why I had accumulated 30,000 lines of code. My question is, what do you think those 30,000 lines of code were doing? Fortunately, there was no markdown involved this time. Did you say time management? |
Slide 85 — 21:40 (watch)
 | That's an interesting guess. There was some problematic clock functionality, but it wasn't significant. Duplicated date formatting is the closest guess, so we'll give it to you. I requested a practice session that included some etudes and tunes, focusing on the domain model layer. This layer represents the in-memory abstractions for how we manage and manipulate data, not the storage layer. However, what I received was a poorly designed UUID soft lookup layer. Every entity had a UUID, and each one stored multiple UUIDs. This led to UUID lookups in the repository layer, and if the wrong type was returned, the entire application would crash. |
Slide 86 — 21:56 (watch)
 | During a late-night coding session, I discovered that a change had inadvertently added UUIDs to my data models. While they were correctly linked at the data model layer, the addition of these UUIDs created issues. If the UUIDs became out of sync, the consequences were unclear. |
Slide 87 — 22:12 (watch)
 | I completely unraveled the situation because it was severely flawed. It's crucial to pay attention to your data models. |
Slide 88 — 22:20 (watch)
 | I outlined my main points and then elaborated on them. |
Slide 89 — 22:24 (watch)
 | Writing code used to require significant design thinking that occurred implicitly. |
Slide 90 — 22:32 (watch)
 | Agentic coding requires us to be more explicit. It does not reduce the need for deep thinking. Now, everyone must take on the responsibilities of a tech lead; congratulations, you are now a tech lead. The fundamental process remains unchanged. |
Slide 91 — 22:44 (watch)
 | Software engineering fundamentally remains unchanged. We prioritize correctness and how we demonstrate that correctness is a fundamentally stochastic process, though it has become faster in some respects. |
Slide 92 — 22:52 (watch)
 | Code has become inexpensive, but ensuring correctness remains a challenge. |
Slide 93 — 22:54 (watch)
 | Thank you. |
Slide 94 — 23:24 (watch)
 | I ran a bit over time, but I believe I still have a few minutes for any thoughts, feelings, or questions. |
Slide 95 — 23:38 (watch)
 | I have not observed any programmatic enforcement regarding restrictions on modifying schemas or other components, and I have also seen this approach fail at the prompt level. |
Slide 96 — 23:46 (watch)
 | I would love to see a product, open-source library, or VS Code extension that allows you to specify which files the model can or cannot access. I believe this type of guardrail will likely emerge soon. |
Slide 97 — 24:04 (watch)
 | As an inexperienced engineer, how can I progress to a tech lead role where I handle significantly fewer tasks typically assigned to junior engineers? That's a good question. |
Slide 98 — 24:16 (watch)
 | That is one of the key questions in the industry right now. |
Slide 99 — 24:24 (watch)
 | Tech lead work, as I described, is qualitatively different from implementation work, which involves writing code and integrating a service once a good API contract is established. I believe you can start practicing tech lead responsibilities directly. |
Slide 100 — 24:34 (watch)
 | You can start by defining what you want to build. |
Slide 101 — 24:40 (watch)
 | What does my database look like, and what are the core entities I care about? |
Slide 102 — 24:46 (watch)
 | Understanding your entire system will be a challenging process initially, as it requires a comprehensive grasp of each component. However, I believe this skill can be developed without spending years painstakingly building each part on others' projects. With the right approach, you can learn to navigate the system effectively. |
Slide 103 — 25:08 (watch)
 | I believe people can learn how to do this directly. I have a quick question: even if a pattern is abstracted, do you quantify how familiar it is to a model before asking it a question? |
Slide 104 — 25:16 (watch)
 | For example, when dealing with something novel, you focus more on the architecture surrounding it, whereas with something relatively standard, you do less. |
Slide 105 — 25:20 (watch)
 | That's a good question. |
Slide 106 — 25:24 (watch)
 | There are many things I don't know about in the software world. |
Slide 107 — 25:30 (watch)
 | Many patterns and practices exist in areas I have not explored. |
Slide 108 — 25:44 (watch)
 | In my experience, when I ask today's models to outline core patterns based on what I know, about 80% of their responses are reasonable and sound, while roughly 20% may not make much sense. |
Slide 109 — 25:52 (watch)
 | There is a sort of Gelman amnesia effect when I build a website or undertake a project where I lack extensive experience. The models often suggest reasonable patterns, but as I explore further, I realize that some of these patterns significantly hinder my development and complicate my work. |
Slide 110 — 26:10 (watch)
 | I generally make a strong effort to establish all of the core patterns myself and understand their rationale, even if a model is generating the content. Thank you. |