34 slides extracted.
Slide 1 — 0:08 (watch)
 | Thank you for attending my talk. |
Slide 2 — 0:22 (watch)
 | My name is Adrian Bertagnoli, and I am a founding engineer at Callosum. Today, I will discuss scaling the next paradigm of heterogeneous intelligence. |
Slide 3 — 0:32 (watch)
 | I will begin by explaining why heterogeneity is important, the specific aspects that facilitate the scaling of AI, how it is currently applied in practice, and how we can leverage it in the future to scale the next paradigm of intelligence. |
Slide 4 — 0:46 (watch)
 | To provide an intuition about heterogeneous intelligence, I will first explain the current prevailing paradigm of homogeneous intelligence. |
Slide 5 — 1:04 (watch)
 | Homogeneous intelligence in AI primarily refers to scaling single models across a fleet of identical chips. |
Slide 6 — 1:36 (watch)
 | This era has been largely shaped by the discovery of neural scaling laws, which indicate that more data and more parameters lead to better models. However, this principle is primarily applicable in the training domain, becoming less relevant as we transition to the inference domain. We are already witnessing a shift toward heterogeneity in our current systems. Architecturally, mixtures of experts are replacing large, dense models. At the workflow layer, single LLM calls are being supplanted by multi-agent systems. Finally, on the hardware level, single chips are being replaced by pre-fill decode disaggregated systems. |
Slide 7 — 2:12 (watch)
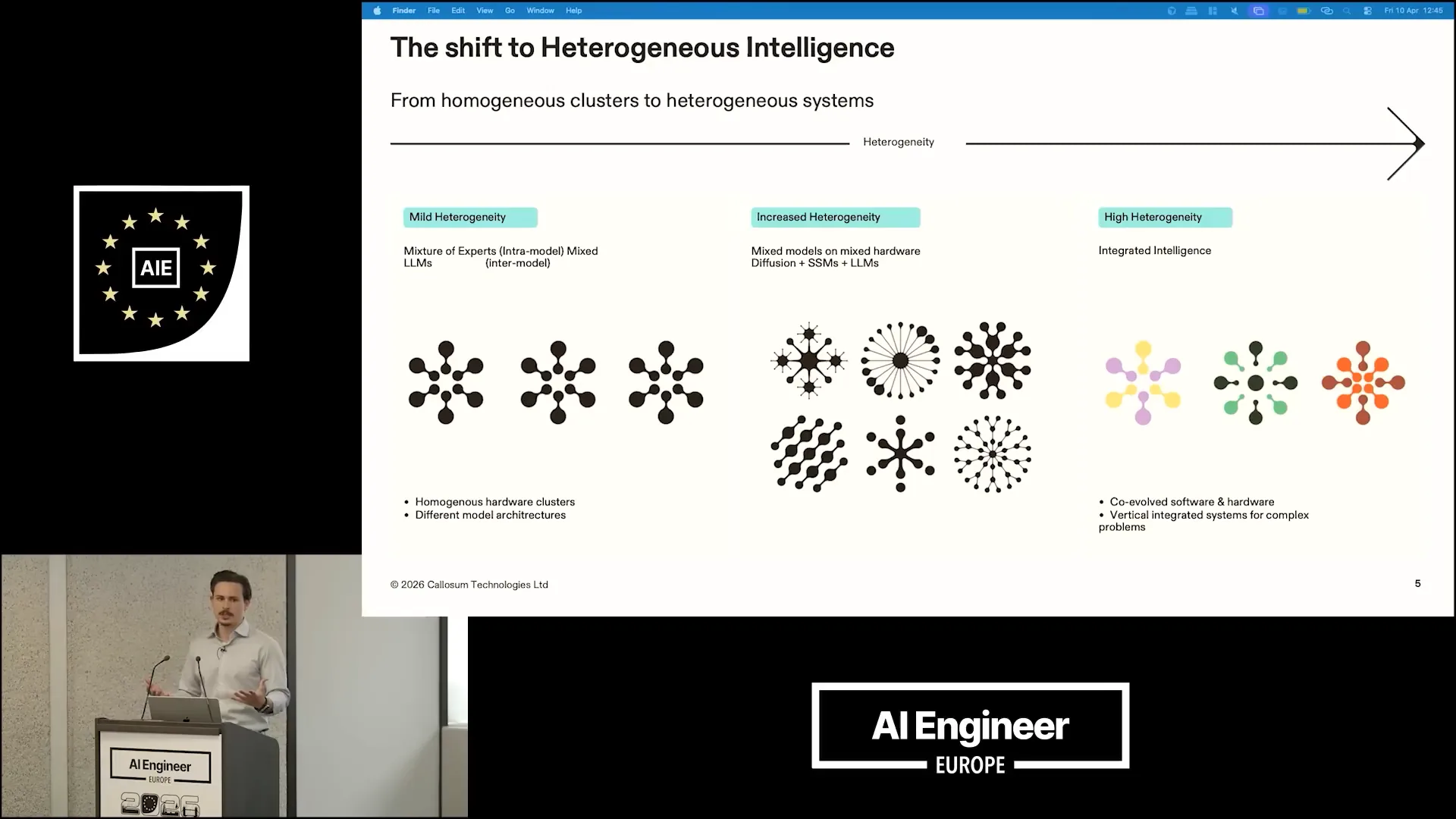 | Given that we are currently experiencing mild heterogeneity, how can we envision a greater level of heterogeneity? What will that look like? Initially, we are in a state of mild heterogeneity. |
Slide 8 — 2:52 (watch)
 | Currently, everything operates primarily on homogeneous clusters, though we do see some variety in the prompts. In multi-agent systems, we may utilize different LLMs for various subagents, and we also employ a mixture of experts. As we increase heterogeneity, we could start using different chips for different models, placing distinct LLMs on separate GPUs. These models may interact with one another, incorporating a range of state-based models and diffusion models, all optimized for the best available hardware. The final stage of this heterogeneous paradigm emerges when we achieve co-evolution among systems, hardware, and software, leading to a unified, vertically integrated approach to intelligence and hardware. |
Slide 9 — 3:52 (watch)
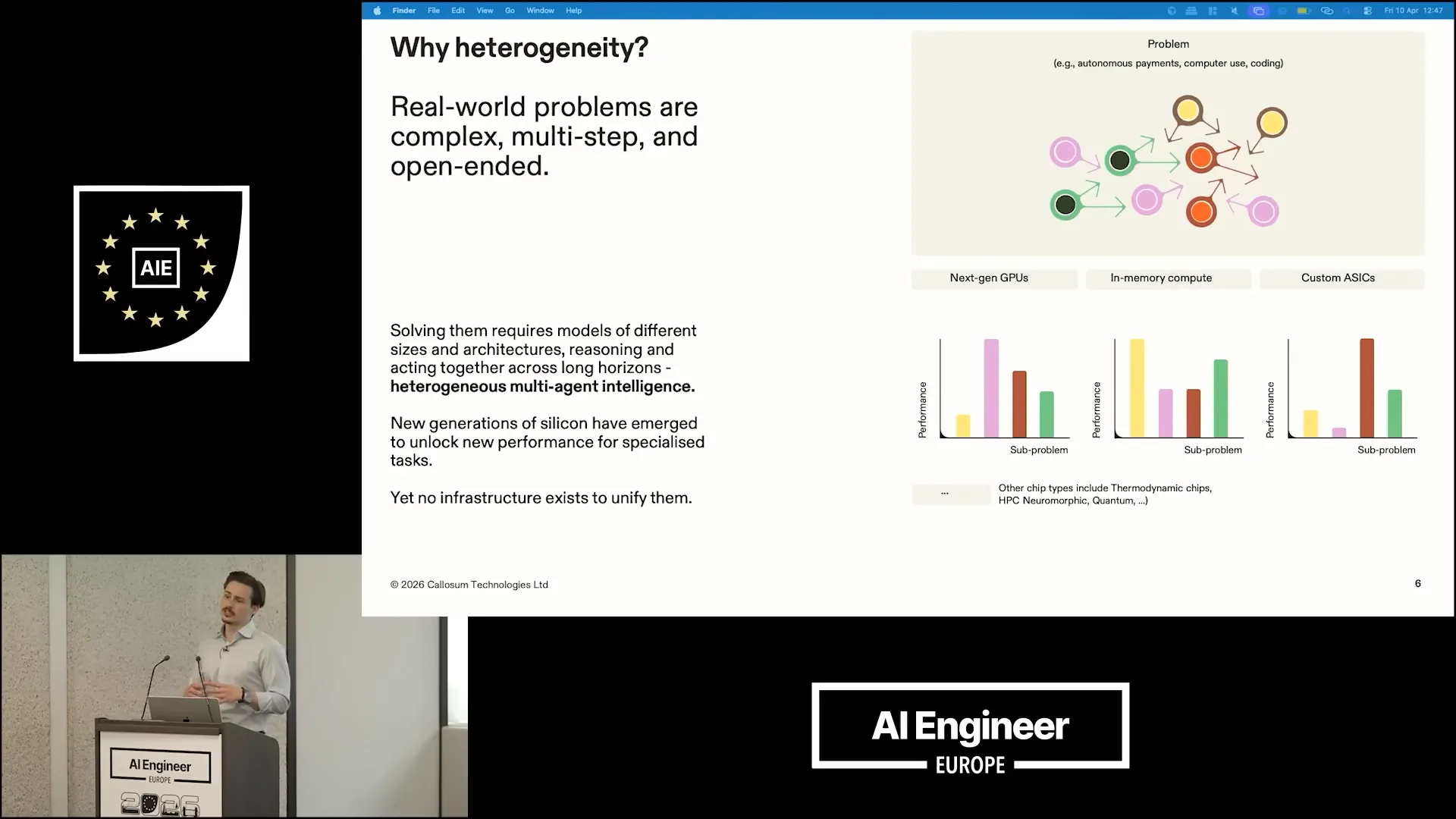 | Heterogeneity is beneficial because real-world problems are complex, multi-step, and open-ended. These problems decompose into sub-problems that require vastly different types of intelligence. Scaling a singular type of intelligence to address these issues is inefficient and suboptimal. To solve them, we need models of various architectures and sizes working together over extended periods, which we refer to as multi-agent heterogeneous intelligence. Additionally, new generations of silicon are emerging in the market, but there is currently no interface that allows this new hardware to be unified and effectively enhance the existing compute stack. |
Slide 10 — 4:52 (watch)
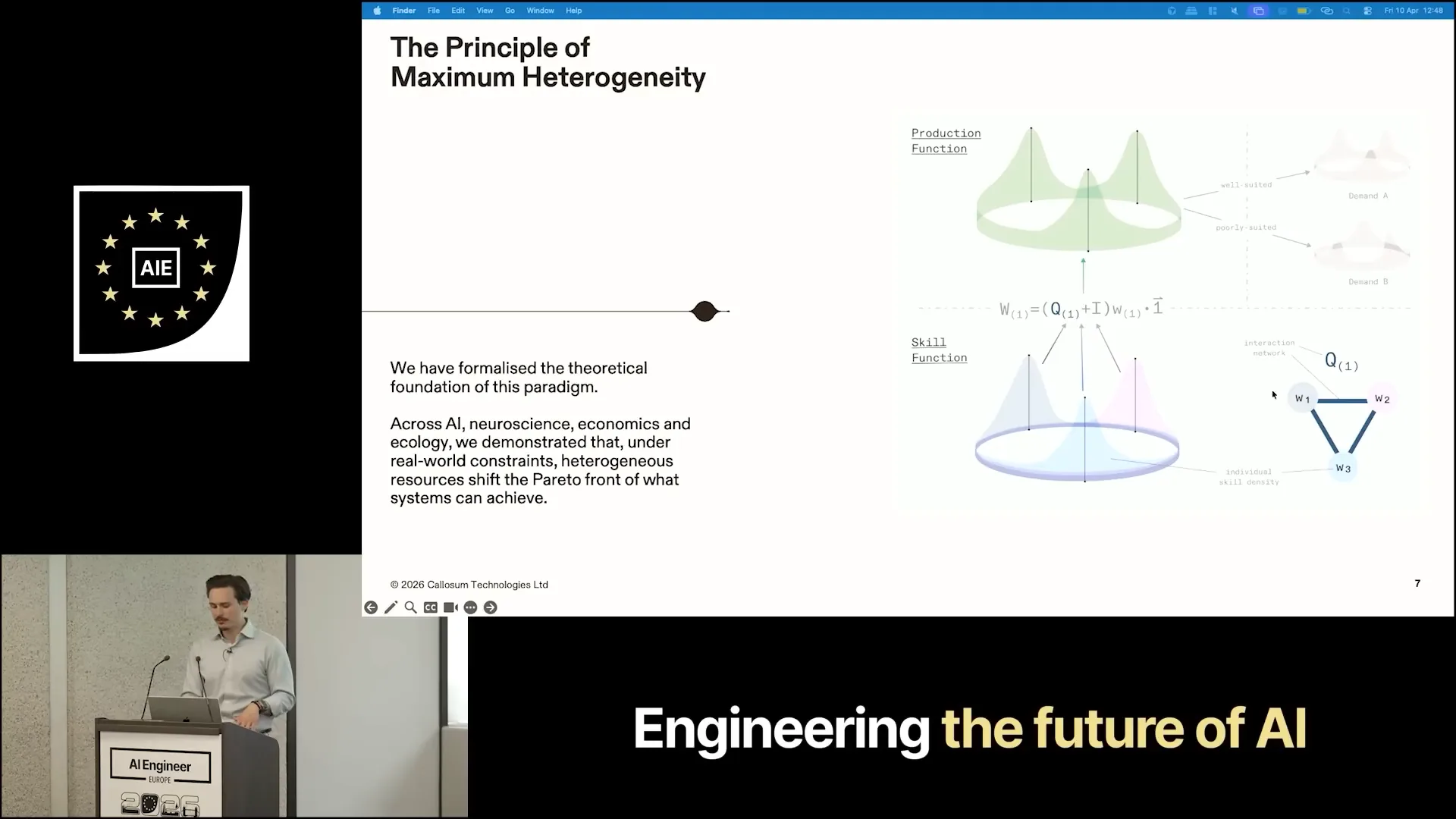 | We aim to change this situation. The benefits of heterogeneity are not just a belief; we have formalized and mathematically proven them. The figure on the left illustrates the principle of maximum heterogeneity, showcasing heterogeneous agents where color represents a distribution over a skill space. When these agents communicate, as indicated by a ring topology, they can create what we refer to as a production function. This production function can effectively meet the demands of one problem while being ill-suited for another. For example, we have a production function that is well-suited for demand A but not for demand B. In a homogeneous approach, you would only be able to scale one peak, or in the optimal case, you would rely solely on generalists with the broadest possible skill set to match the demand function. |
Slide 11 — 5:40 (watch)
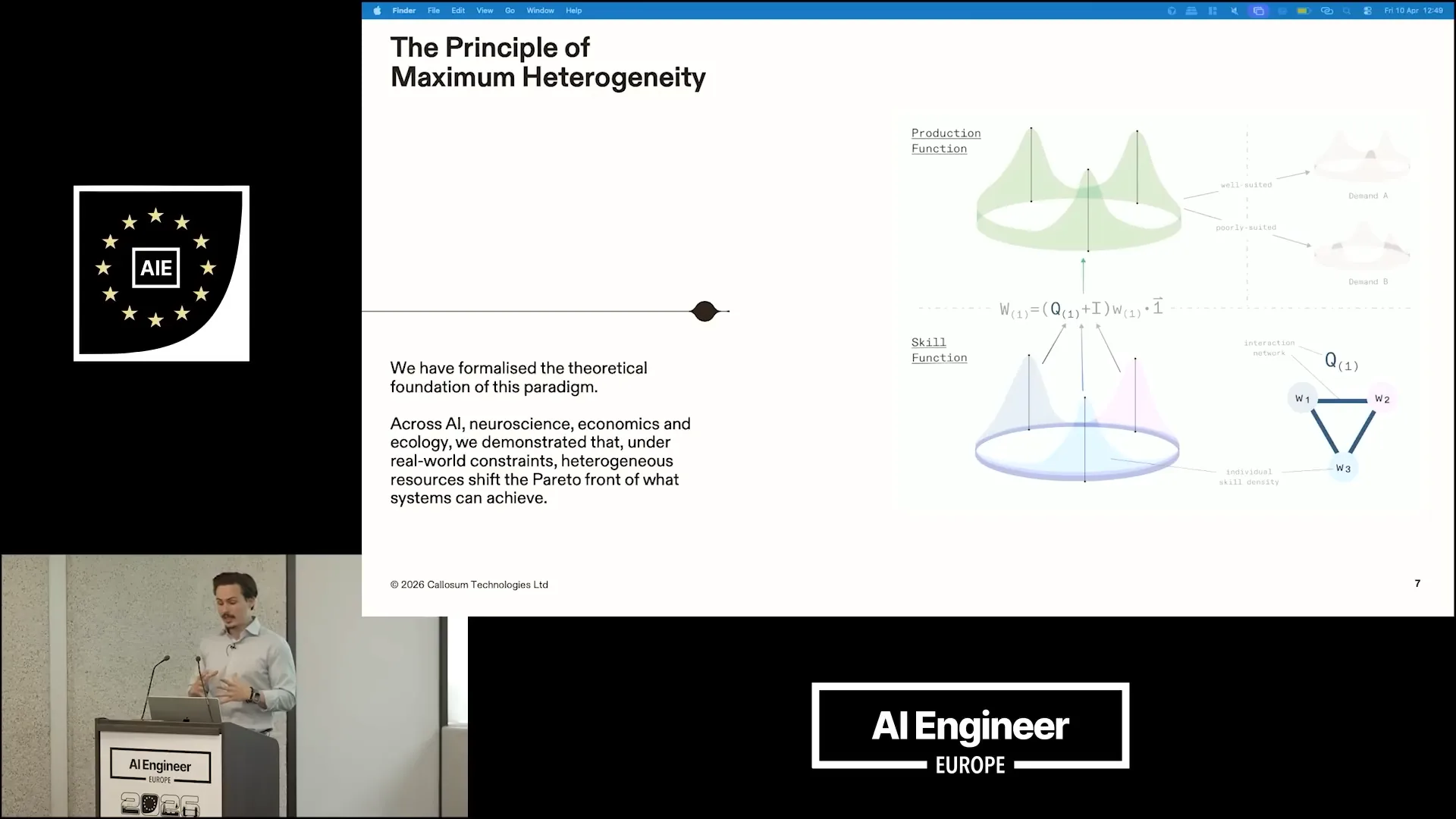 | Ultimately, a very short cylinder does not adequately meet the production function. We formalized this observation and found that across various domains, including neuroscience, economics, and ecology, these trends persist. Under reasonable constraints, heterogeneous systems consistently outperform homogeneous ones. |
Slide 12 — 6:08 (watch)
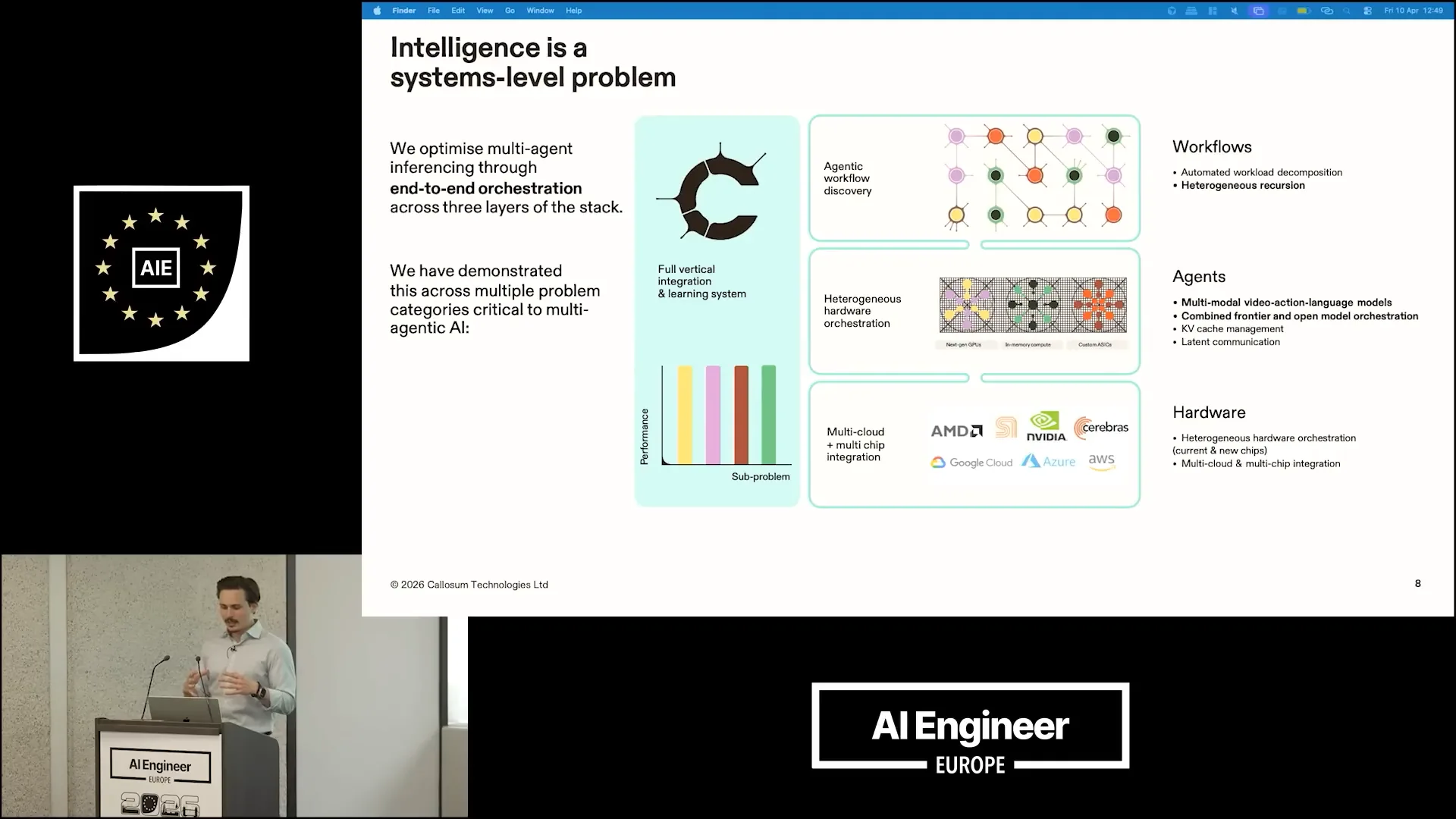 | To apply this in practice, we focus on optimizing multi-agent systems at three different stages of the workflow. First, we select different hardware based on the computational demands of the agents. Then, we consider how the agents interact and the workflows they construct. |
Slide 13 — 6:38 (watch)
 | We have demonstrated multiple benefits of this type of orchestration. I want to highlight a couple of them: first, in the workflow, we have a concept we refer to as heterogeneous recursion. Second, in the agent layer, I will discuss multi-modal video action language models. |
Slide 14 — 7:08 (watch)
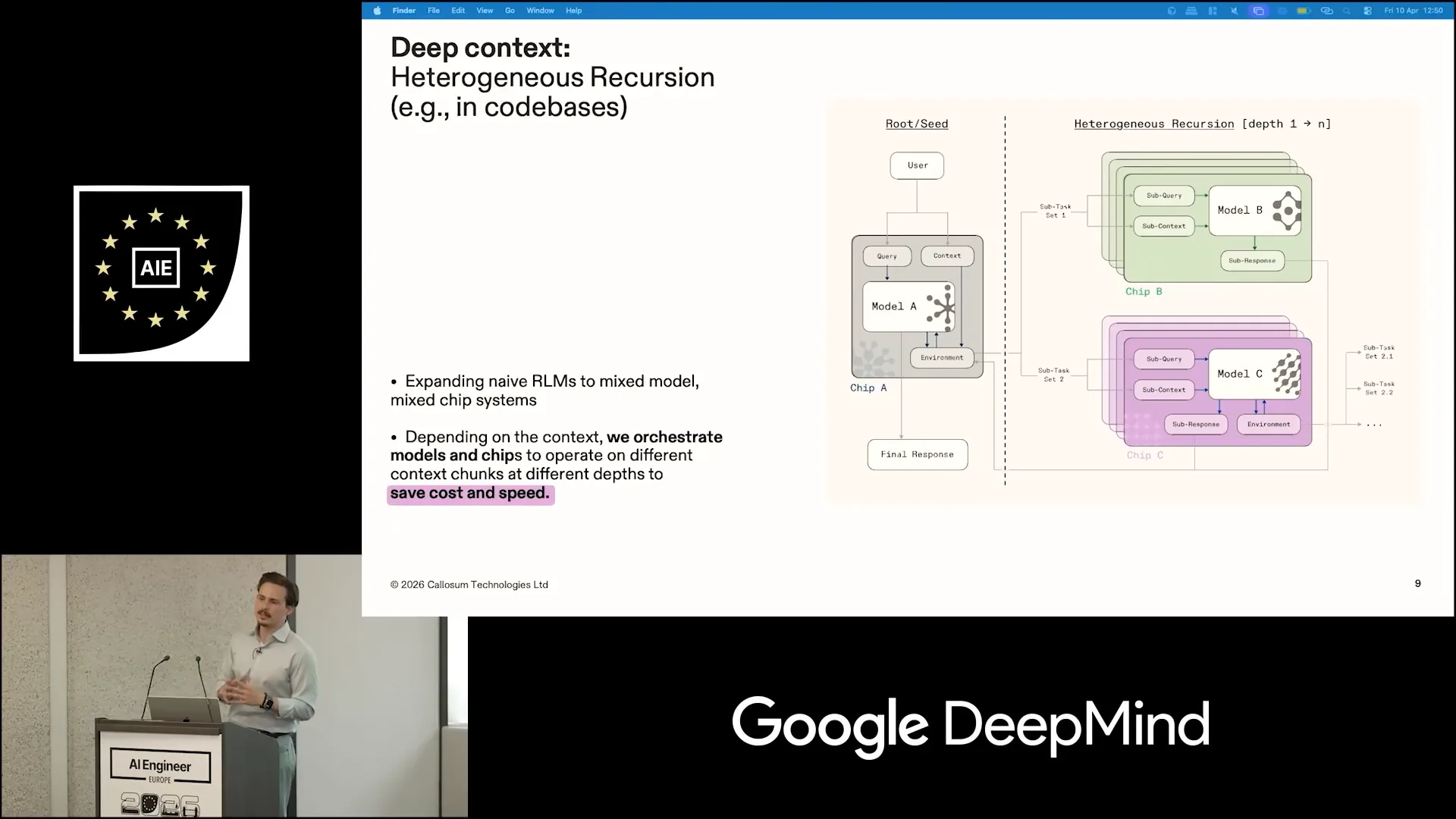
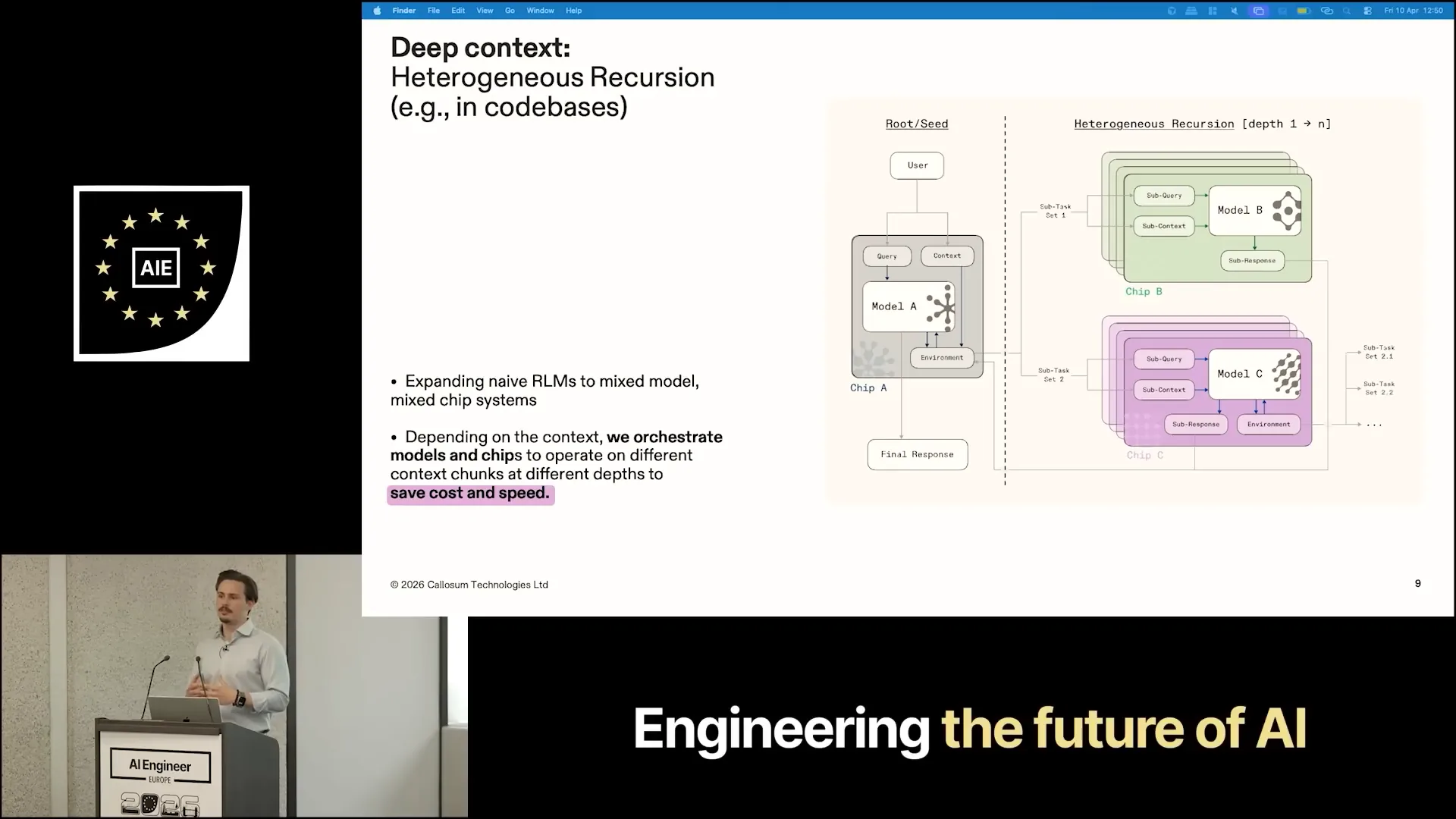 | Heterogeneous recursion refers to recursive language models. For those unfamiliar, a recursive language model is a seminal concept introduced in a paper from MIT last October. The research demonstrated that even when occupying only a small percentage of the context window, significant context shifts can occur depending on the information complexity required from the prompt. |
Slide 15 — 7:30 (watch)
 | If you're performing a needle-in-a-haystack task, the information requirement remains constant, regardless of the size of the prompt. |
Slide 16 — 7:44 (watch)
 | Adding up the rows, where you have rows and columns, results in O(N) complexity. As the prompt increases, the informational requirement grows linearly. Therefore, with a constant information requirement, the system scales effectively. |
Slide 17 — 8:00 (watch)
 | You can utilize the full context window to obtain a good answer. However, when the complexity increases to linear or quadratic, performance degrades to about 30 to 60%. Recursive language models address this issue by treating the context as an environment instead of incorporating everything into the prompt. |
Slide 18 — 8:44 (watch)
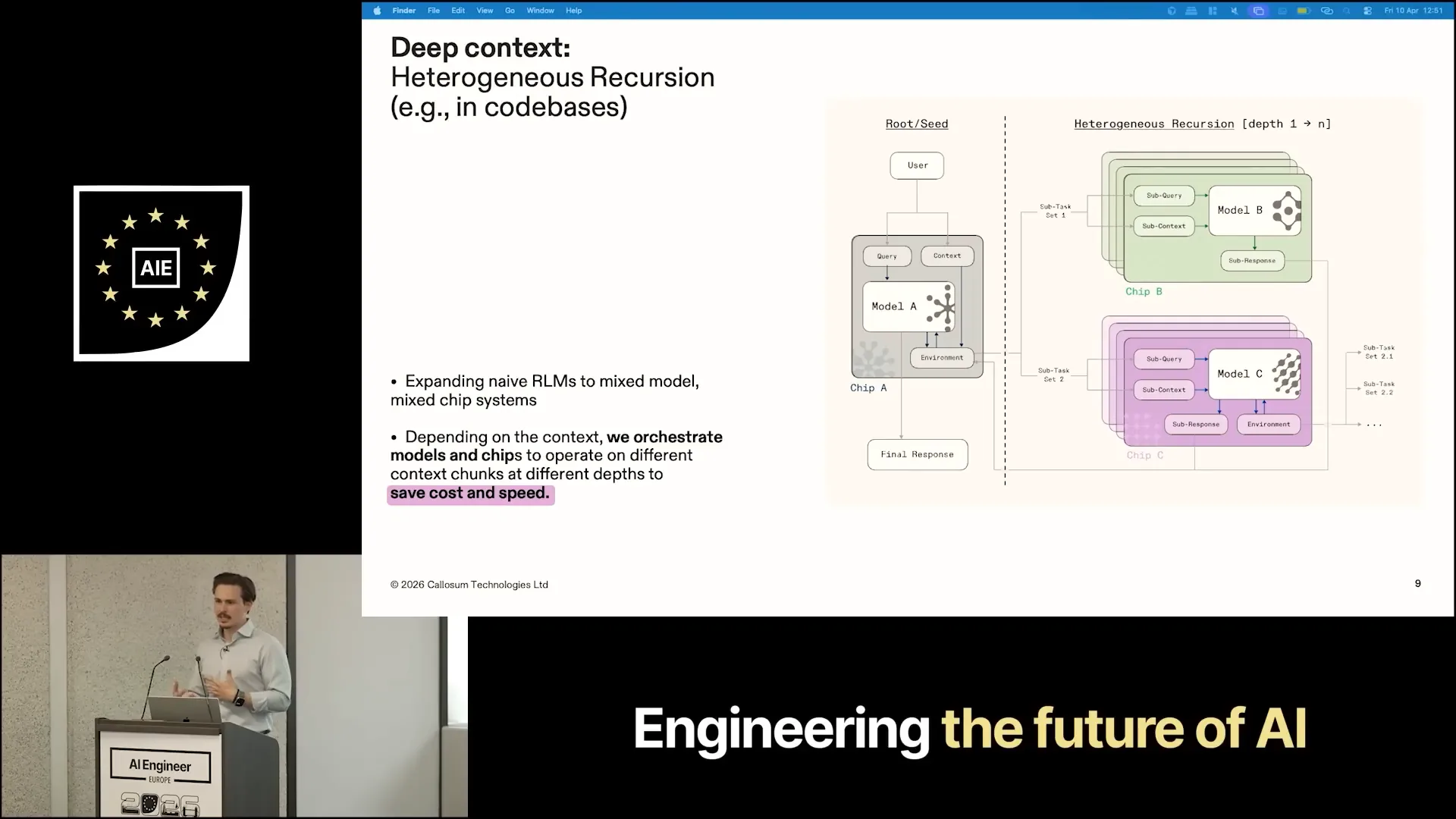
 | In practice, you present the context in a file, allowing the coding agent to interact with it programmatically through the Python REPL. This involves performing keyword searches and other techniques to extract subcontexts. The extracted subcontext is then passed to an identical recursive agent, which can either answer the question or spawn another recursive agent. This is the basis for recursive language models. We extended this concept by mapping the generated subcontext to different chips and models, rather than using a single model on a single chip. This approach emulates performance while being significantly cheaper and faster. |
Slide 19 — 9:12 (watch)
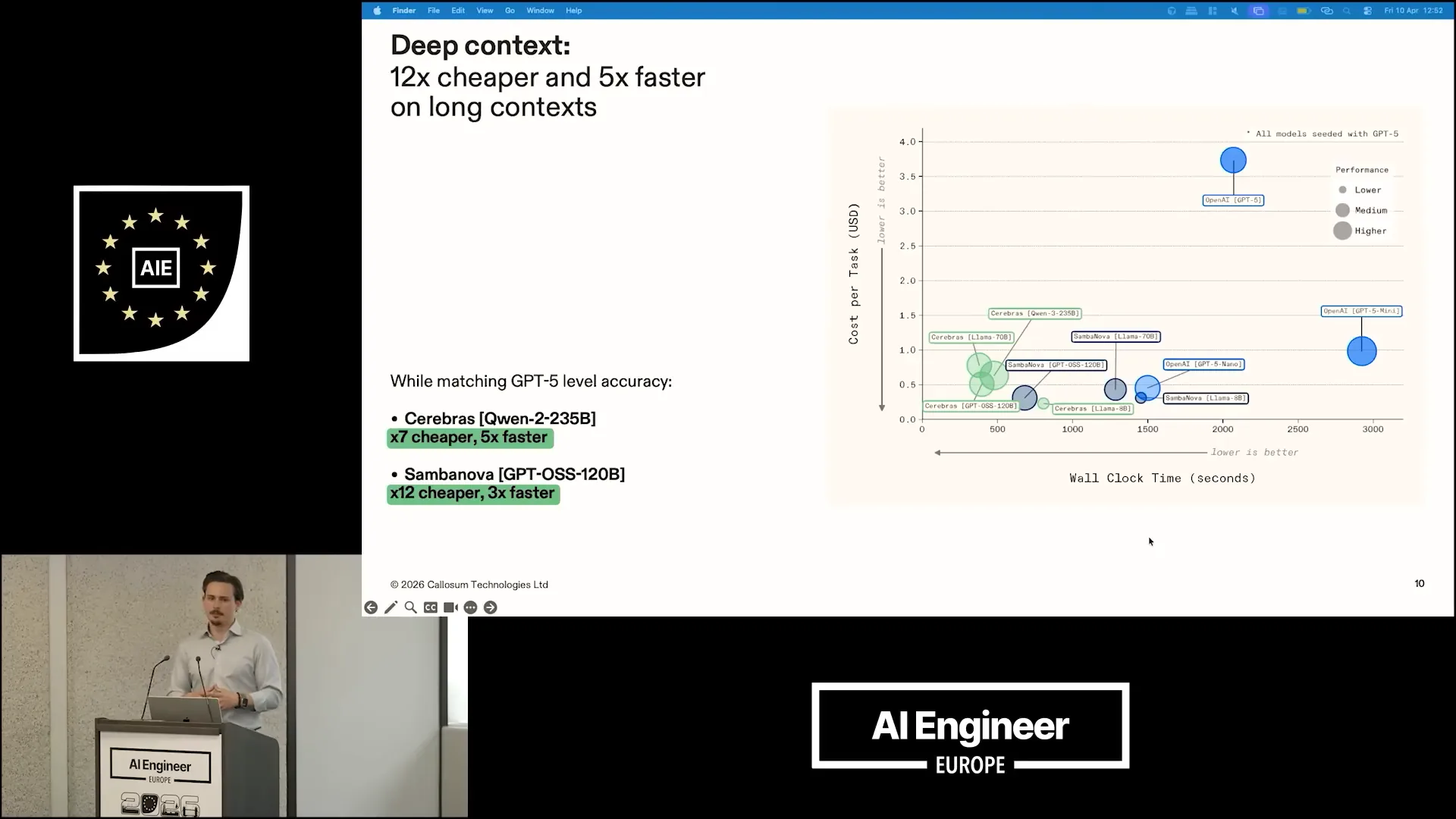 | Here are the results on the Oolong benchmark, which is the benchmark referenced in the paper. |
Slide 20 — 9:50 (watch)
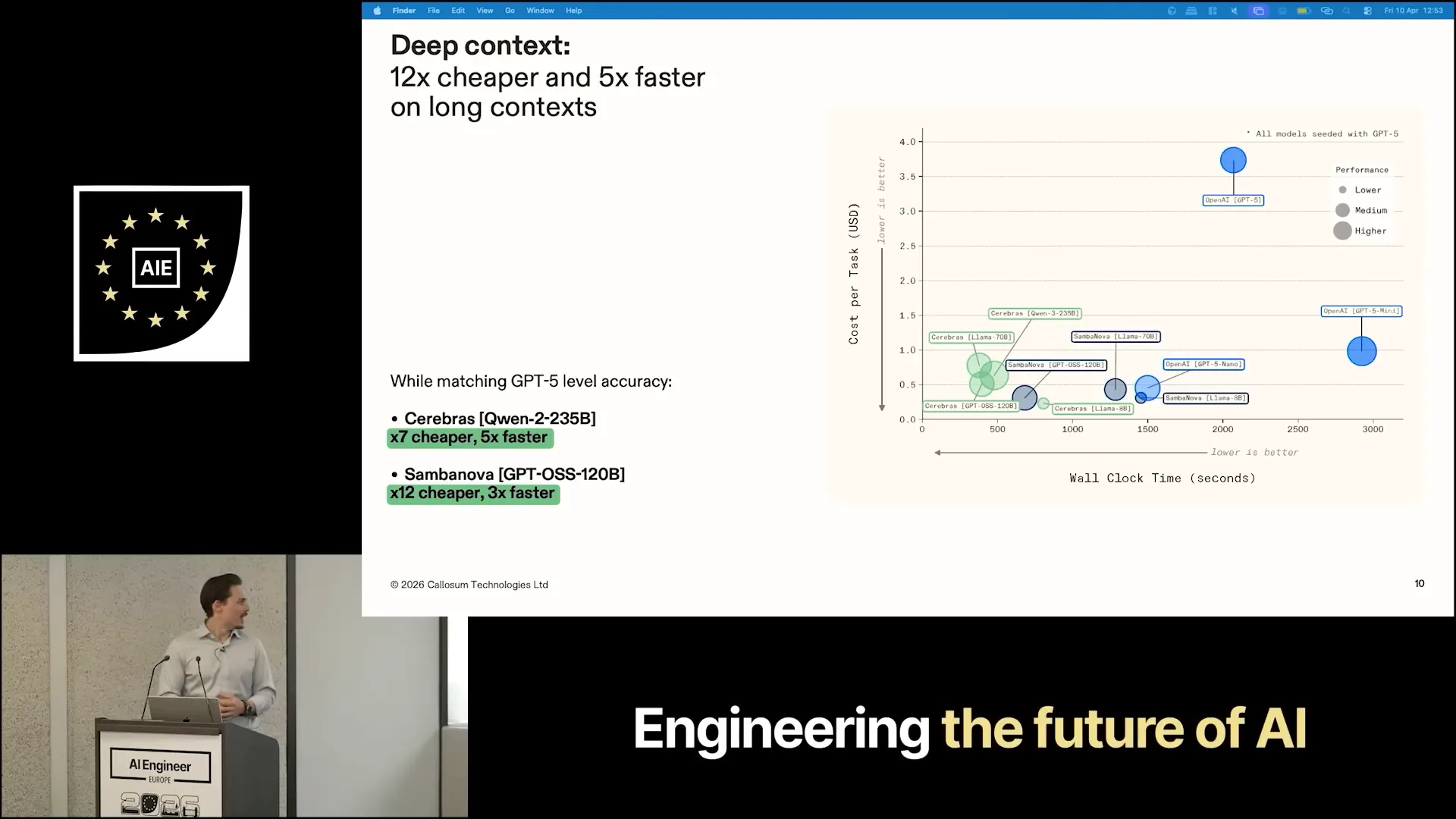 | GPT-5 and GPT-5.2, the most recent versions, take approximately 2,000 seconds to complete the Oolong benchmark, costing around $3.75 per task. In contrast, our system on Cerebras is seven times cheaper and five times faster, allowing for significant savings in both time and cost. With SambaNova, we achieve even greater efficiency, being 12 times cheaper and three times faster, though this comes at the expense of some latency. These architectural decisions demonstrate that substantial cost reductions can be achieved without solely relying on hardware, while still emulating the intelligence of frontier models. |
Slide 21 — 10:28 (watch)
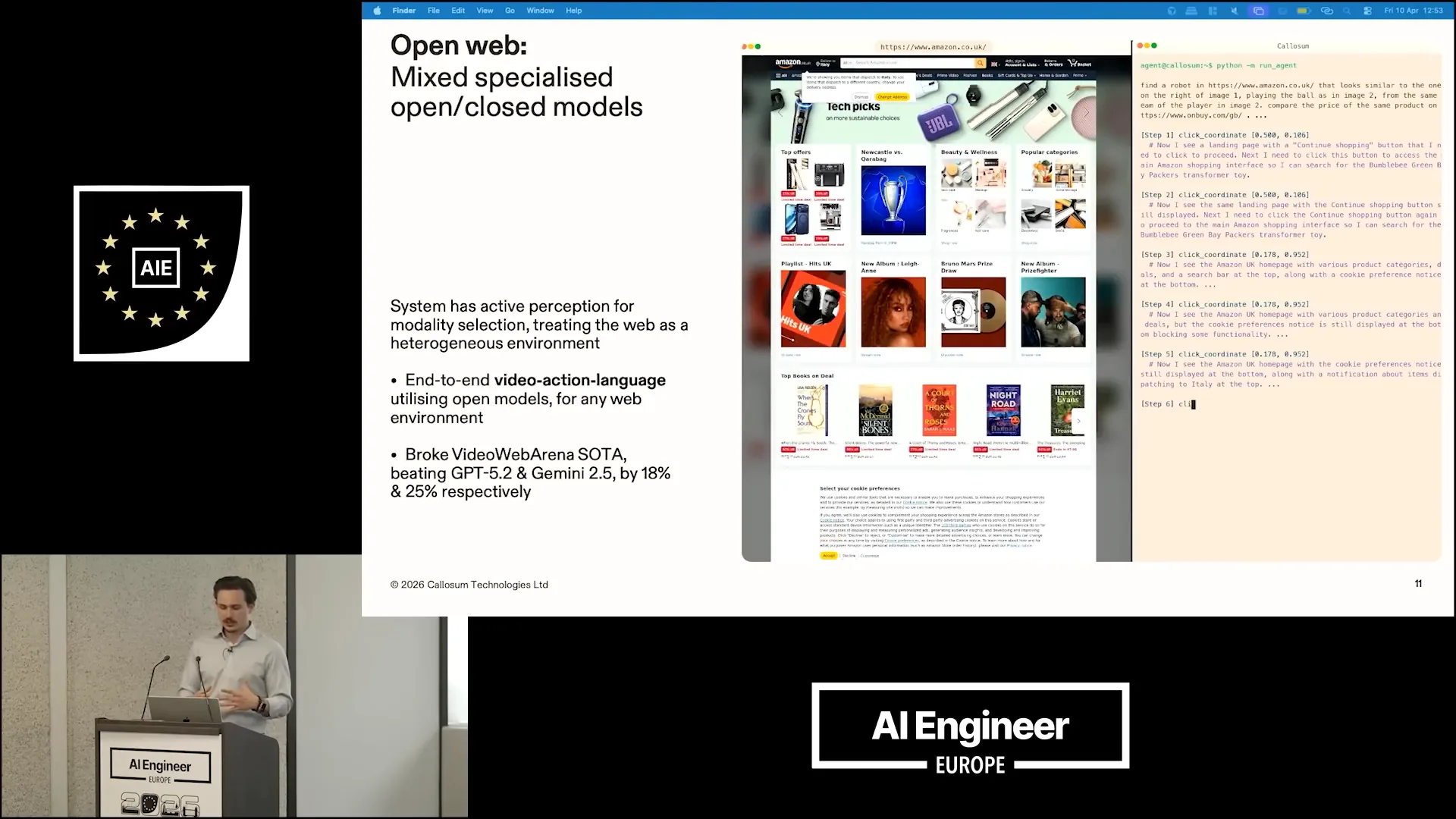 | The next problem we wanted to address is visual web navigation. |
Slide 22 — 10:36 (watch)
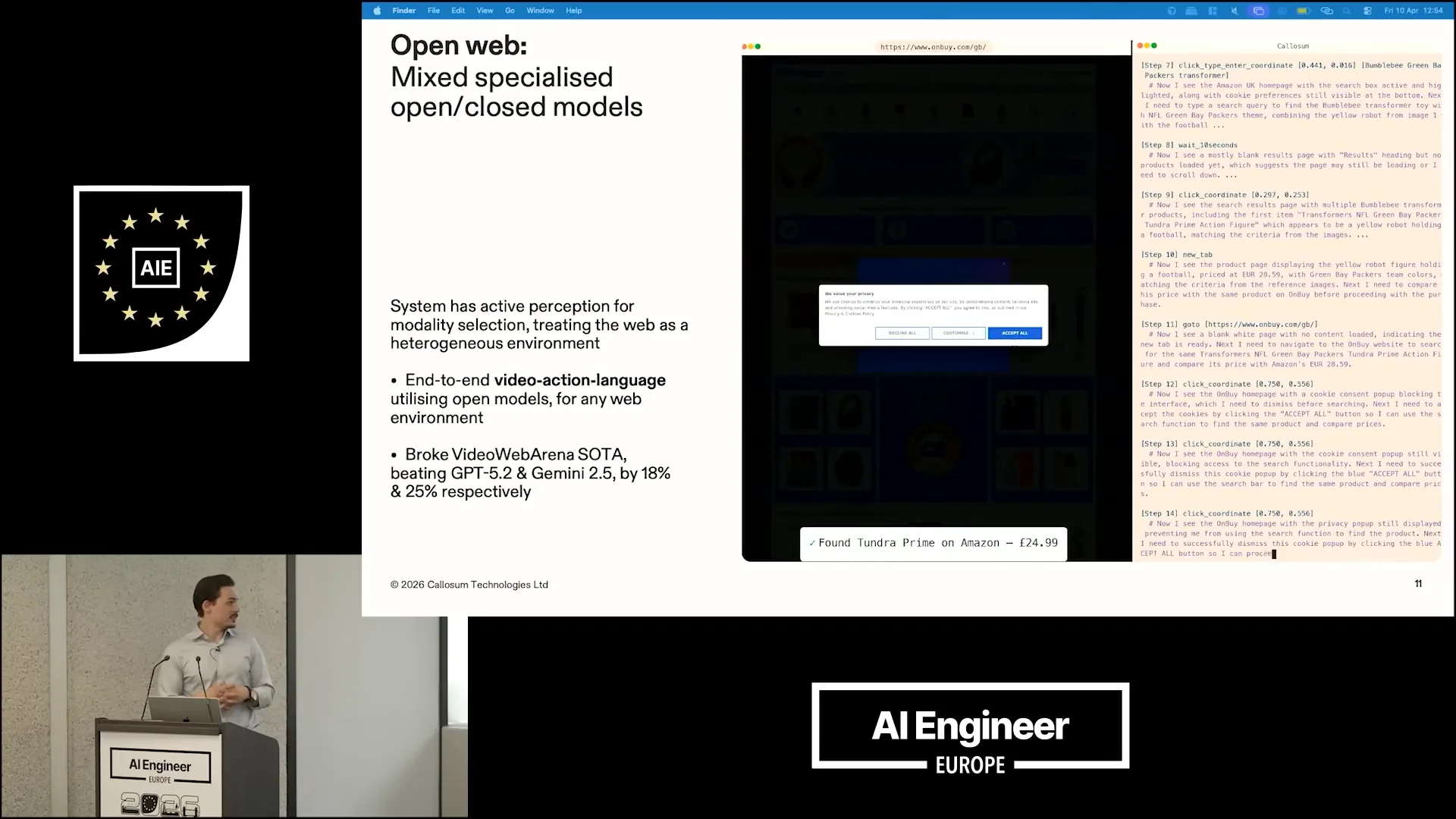 | We utilized a combination of open and closed video action language models, achieving a performance improvement over the state-of-the-art in video web navigation. Specifically, we surpassed GPT-5.2 and Gemini 2.5 by 18% and 25%, respectively. |
Slide 23 — 10:50 (watch)
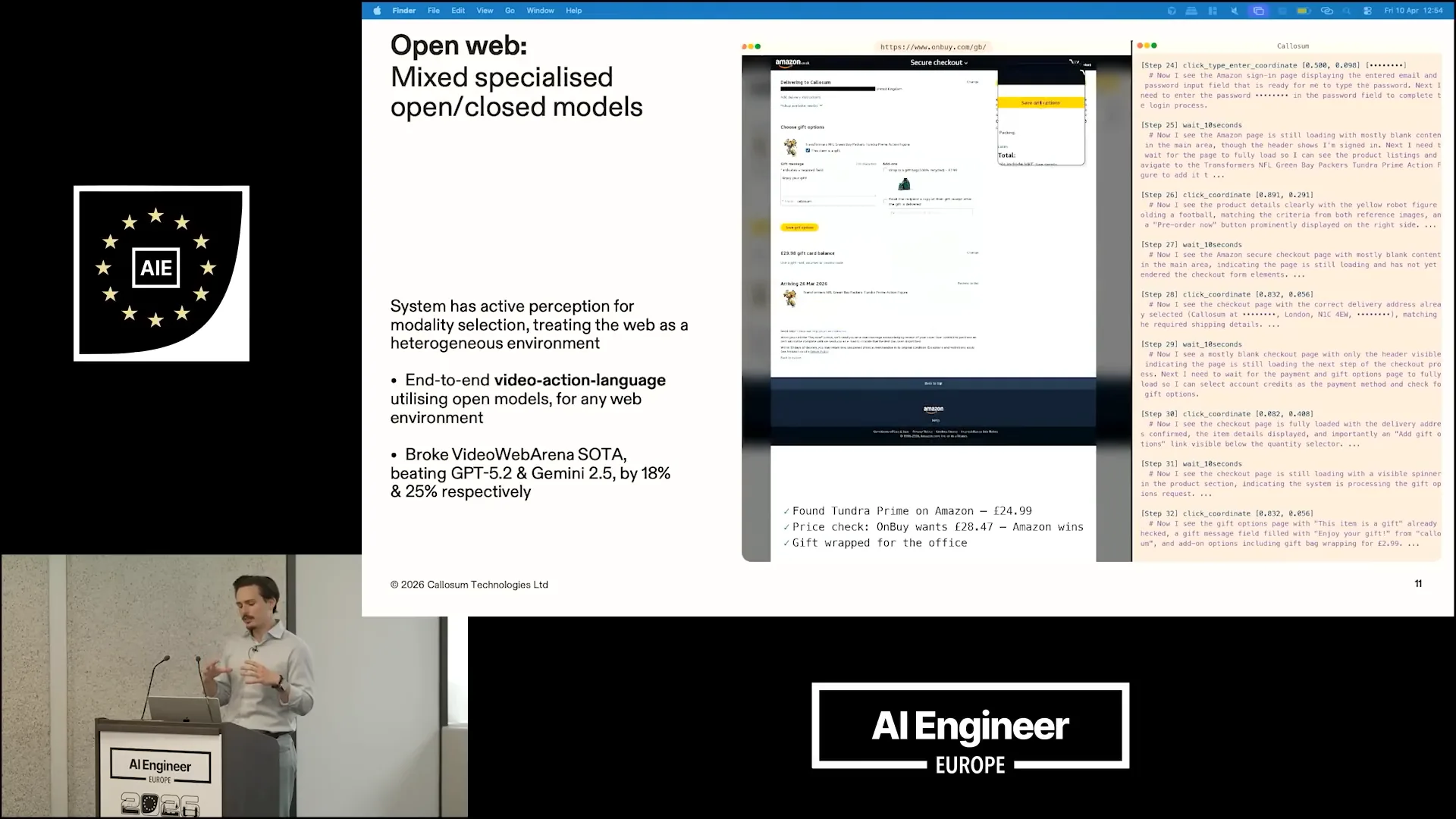 | We approached the problem by recognizing its heterogeneous nature rather than treating it as homogeneous. |
Slide 24 — 11:04 (watch)
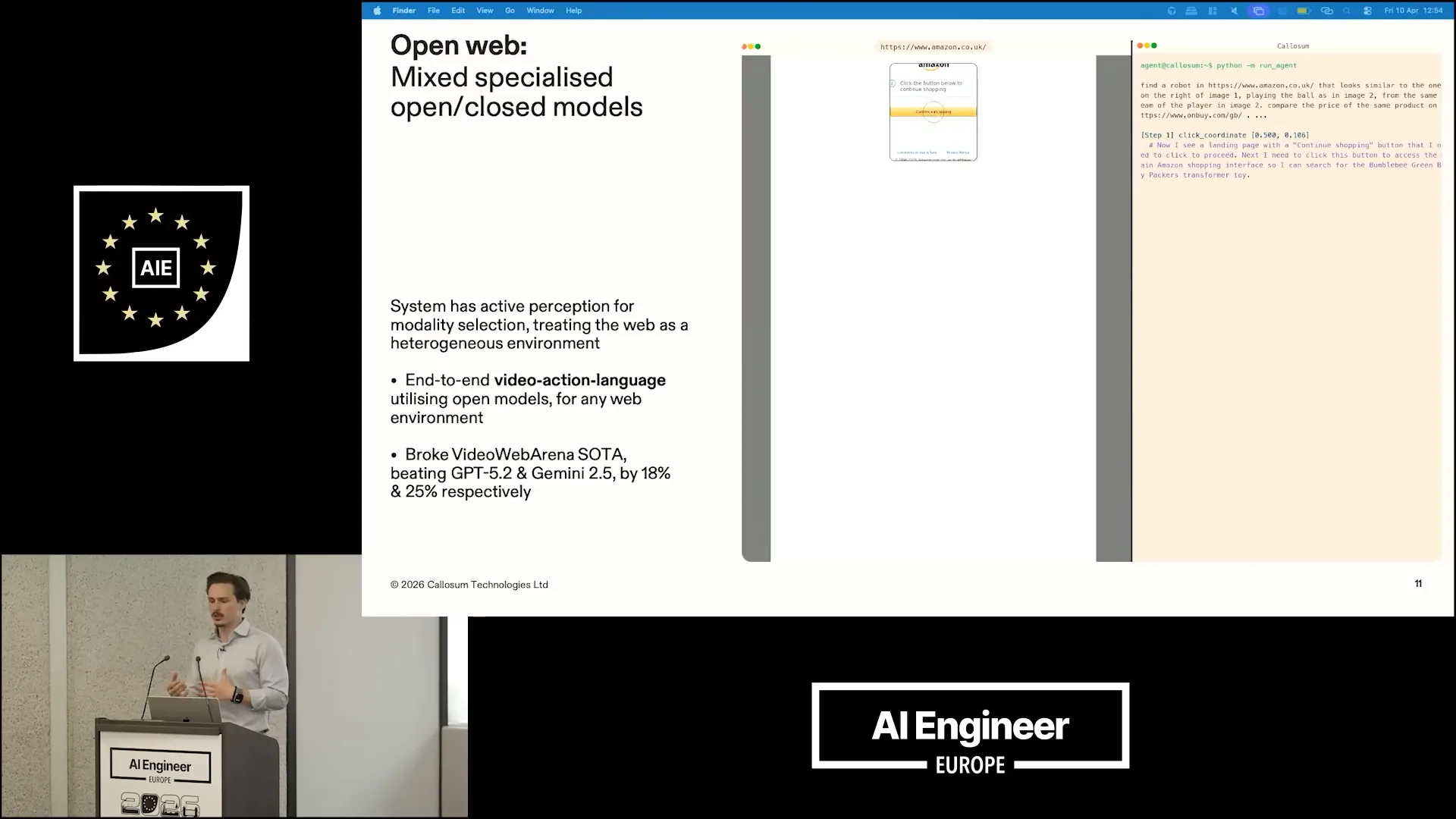 | The problem decomposes into multiple steps involving visual reasoning and textual reasoning. Each of these subcomponents requires different models to be successfully completed. |
Slide 25 — 11:16 (watch)
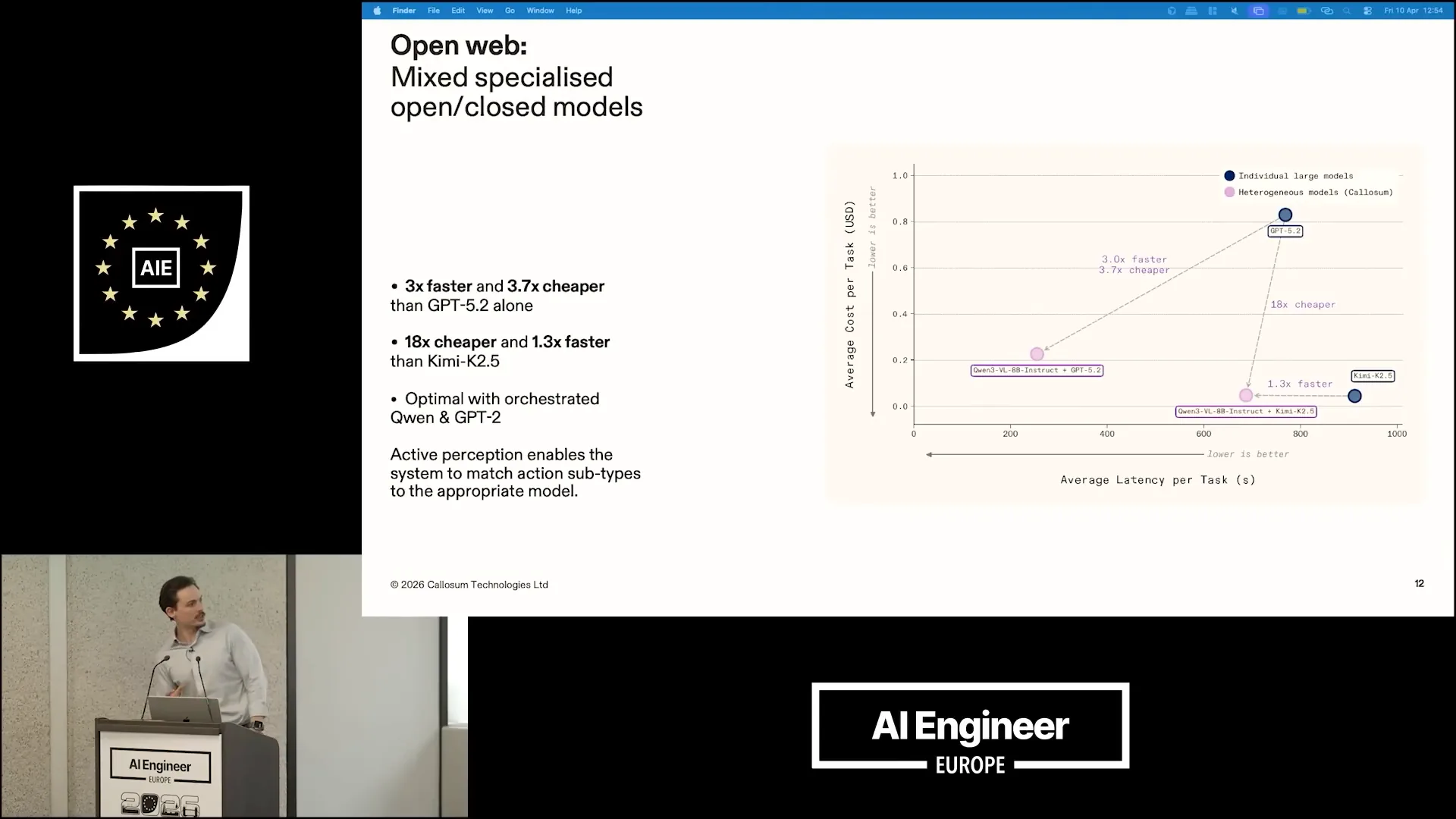 | Here, we observe a fundamental shift in the Pareto frontier, where singular models like Kimi K2.5 and GPT-5.2 are outperformed by a heterogeneous set of models. |
Slide 26 — 11:50 (watch)
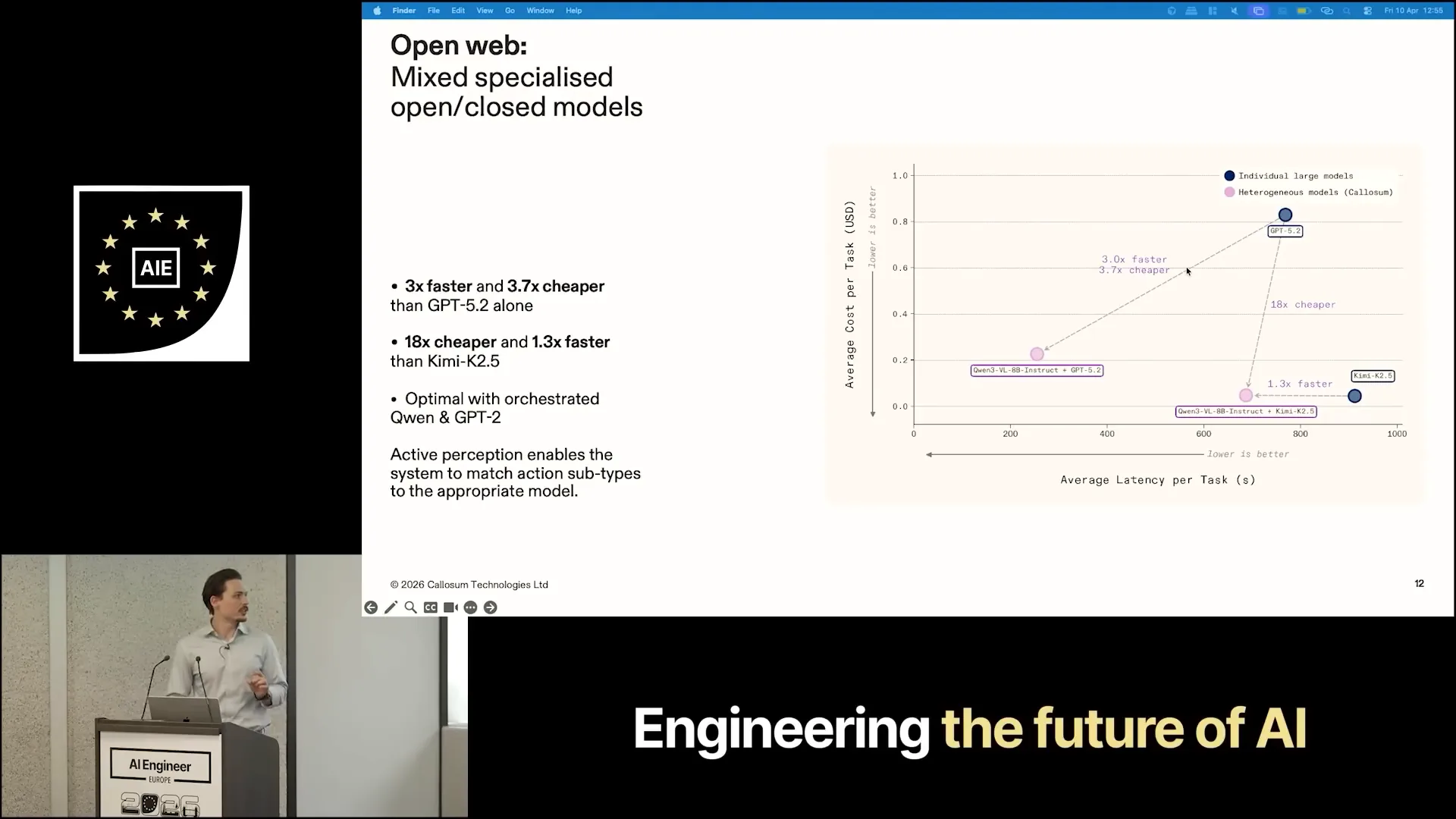 | When we use Qwen3 VL 8B Instruct alongside Kimi K2.5, we achieve a speed increase of 1.3 times compared to using Kimi alone, and we are 18 times cheaper than using GPT-5.2 alone. Combining Qwen3 with GPT makes us three times faster and 3.7 times cheaper. This approach has no downsides; it solely provides benefits. One of our differentiating factors that allows us to surpass the state-of-the-art is that we mapped certain sub-tasks, such as zooming and creating different visual reasoning for the agent, to less intelligent models. For instance, GPT is not necessary for performing zoom functions. |
Slide 27 — 12:30 (watch)
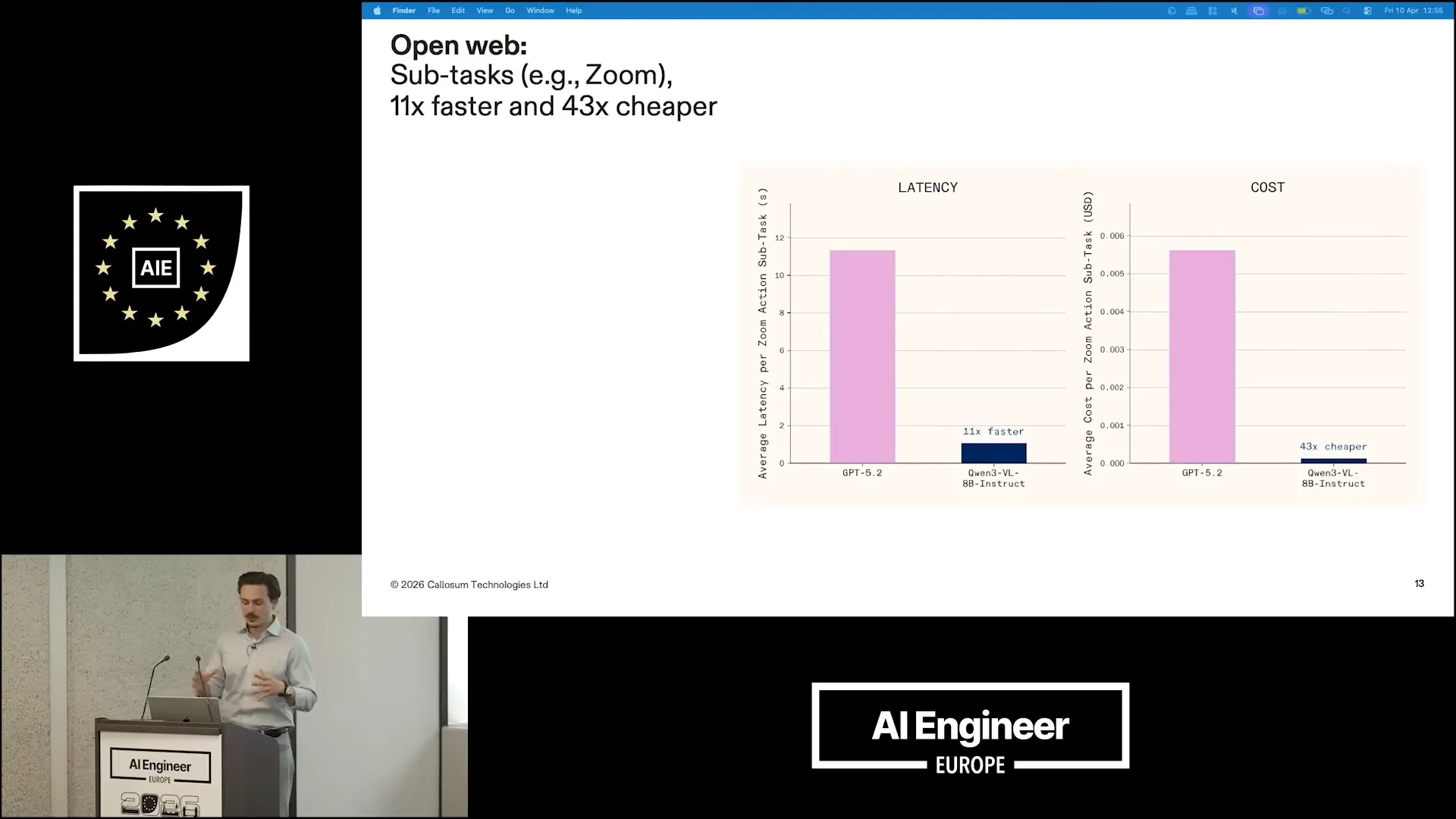 | For these sub-tasks alone, we are 11 times faster and 43 times cheaper than using ChatGPT. This contributes to our overall performance, making us 3.7 times cheaper and three times faster. |
Slide 28 — 12:50 (watch)
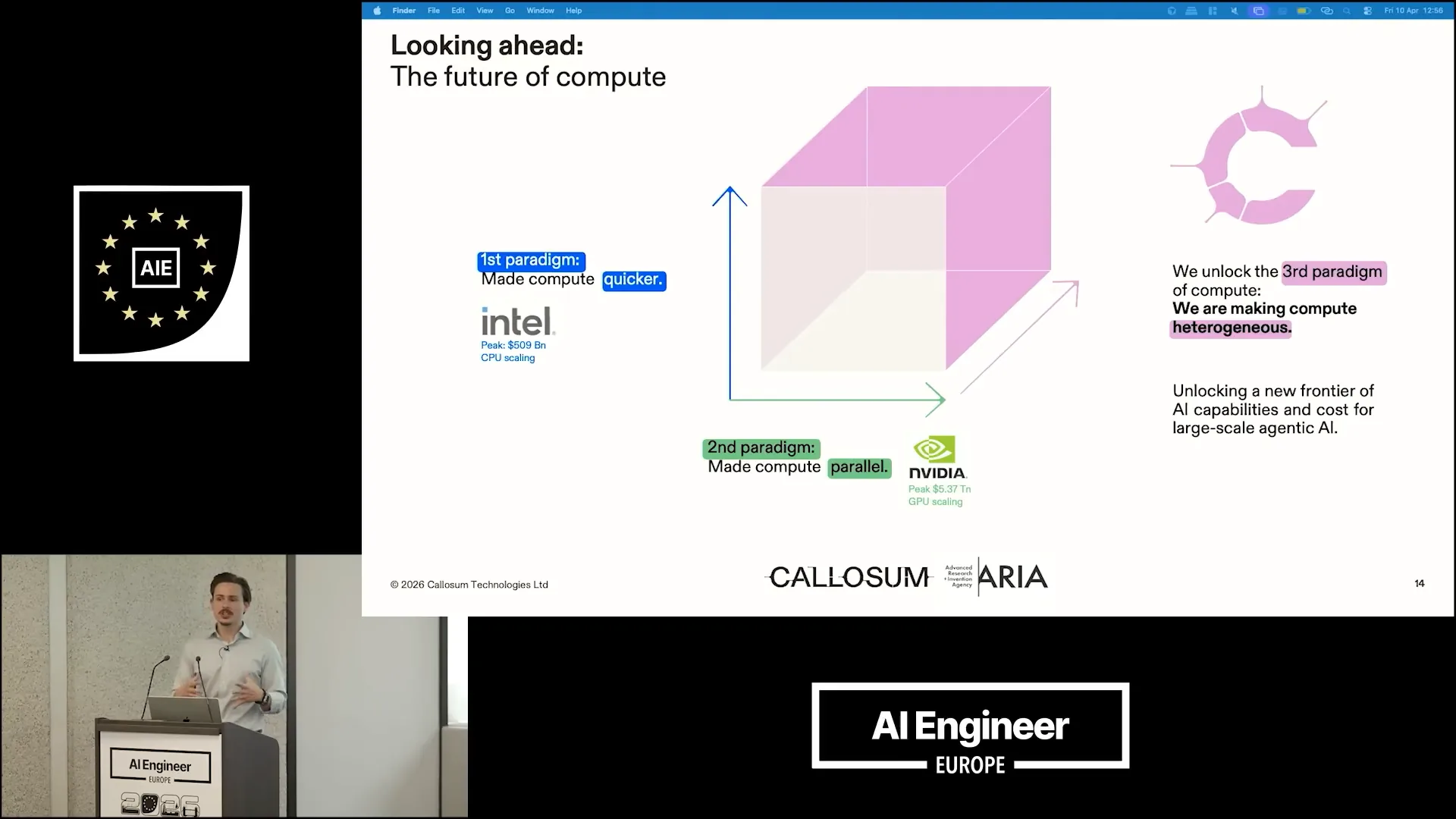 | Looking ahead, we consider the future of compute. The first era of scaling compute was dominated by the CPU, which focused on increasing speed. The second era emphasized massively parallel computing, primarily driven by NVIDIA. |
Slide 29 — 13:08 (watch)
 | The third paradigm of compute will be heterogeneous, focusing on mapping multi-agentic workloads optimally onto different chips. We are collaborating with ARIA, the UK institute. |
Slide 30 — 13:22 (watch)
 | We received a £3 million grant to operate the first heterogeneous co-located cluster in the UK. Our goal is to make a significant impact and lead this new era of innovation. |
Slide 31 — 13:38 (watch)
 | The era of homogeneous scale has delivered extraordinary progress, for which we should be grateful. The next phase is heterogeneous intelligence, where models, workflows, and silicon co-evolve. Each new source of diversity enhances the entire system, making it smarter, faster, and more cost-effective. |
Slide 32 — 13:52 (watch)
 | This is the worst our infrastructure will ever be. Thank you. |
Slide 33 — 14:24 (watch)
 | How do you define which tasks to run on the faster, cheaper model, such as a Zoom? Is this hard-coded, meaning if you need to Zoom, you use this model, or do you have a more intelligent system in place? Initially, we made bespoke decisions to map certain simple subtasks to specific models. However, we have since developed an automation layer that detects task complexity and automatically predicts the most suitable model and hardware. Any other questions? Thank you for your attention. |
Slide 34 — 14:54 (watch)
 | My name is Adrian Bertagnoli. If anyone is interested, we are hiring. Thank you very much. |