41 slides extracted.
Slide 1 — 0:18 (watch)
 | Can you all hear me? Great. Thank you for sticking around despite the delay. We will discuss why CI/CD is dead and propose that continuous compute is the next evolution in this space. |
Slide 2 — 0:44 (watch)
 | Welcome, everyone. My name is Madison, and I am a partner at NEA, where I invest in technology. We have two speakers today; one is currently getting set up. |
Slide 3 — 0:54 (watch)
 | I focus on infrastructure and developer tools. Previously, I was a Meta AI researcher, where I led data and AI teams. Frustrated by the state of infrastructure, I transitioned into venture capital to address these issues from a higher level. |
Slide 4 — 1:08 (watch)
 | I would like to introduce my partner, Hugo Santos, who is the CEO of Namespace. Namespace is developing high-performance compute infrastructure, which we believe will surpass the current CI/CD wave. Hugo previously led microservices at Google. |
Slide 5 — 1:30 (watch)
 | We will discuss how agentic software is disrupting traditional CI/CD practices. |
Slide 6 — 1:52 (watch)
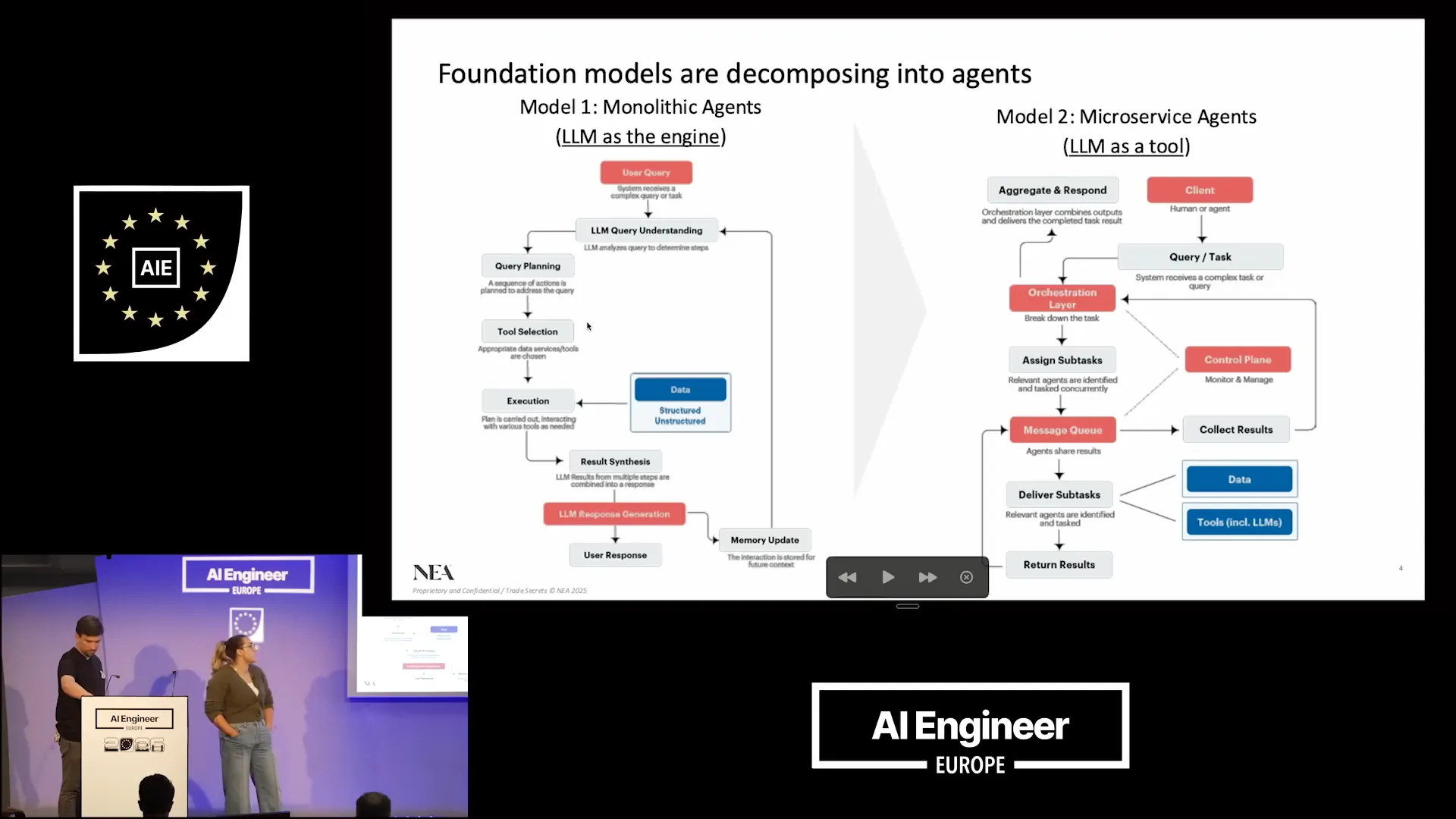 | We won't cover everything today, but the key point is that agentic software began with monolithic agents on the left side. Initially, we used the LLM as a single engine. Now, we are transitioning to the right side, which involves microservices with agents. This shift is essential for how we approach software development in an agentic world. |
Slide 7 — 2:48 (watch)
 | The life cycle of software development has become very fragmented. We have integrated traditional CI/CD systems, including build, test, and deploy processes, alongside new IDEs and autonomous agentic engineering solutions. Traditional DevOps remains central, but we believe it will undergo significant innovation in the coming year. Currently, CI/CD pipelines operate with human developers submitting one or two diffs while writing code. These pull requests (PRs) require considerable time for colleagues to review. After that, developers run build, test, and deploy steps through GitHub Actions, addressing any failed test cases and iterating on the diffs. This process typically results in just one or two PRs per week. In contrast, when considering agent scale, agents utilize the same systems but can generate numerous PRs across multiple repositories. The verification process remains similar in duration unless review bots are employed, which complicates matters further. Agents also need to correct failed cases as in the previous scenario. With human developers, the process is relatively predictable, aided by local caches that are often warm. However, for agents, the situation becomes complex due to the presence of thousands of short-lived branches, all pulling the same codebase in different directions. This leads to challenges in merging the various versions, making it increasingly difficult to manage. |
Slide 8 — 4:14 (watch)
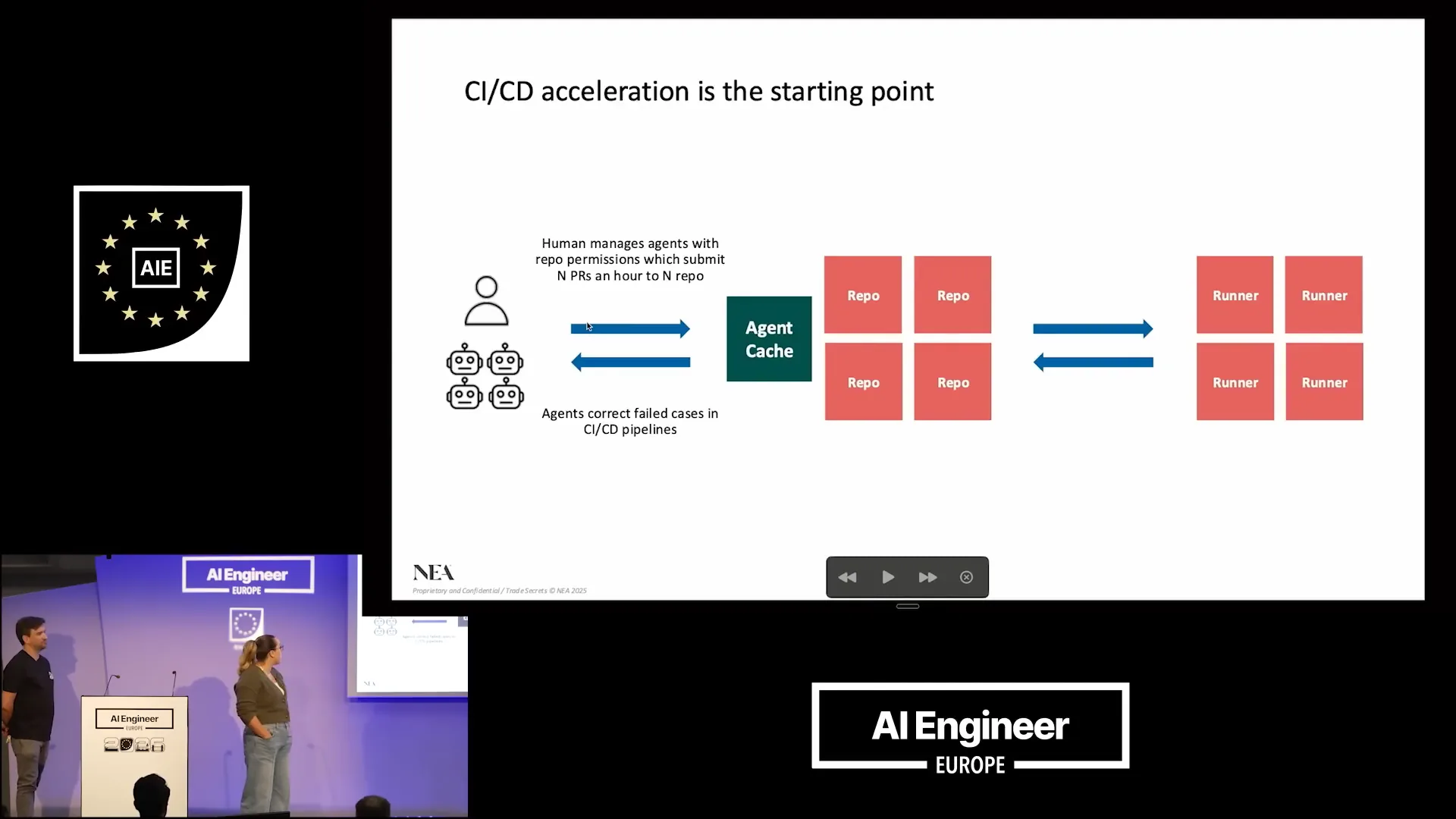 | This is where we encounter a significant problem. GitHub activity has surged dramatically, as illustrated by the white line representing the number of commits over the past couple of months, alongside the number of lines added versus deleted. This spike is remarkable. To address the challenges with CI/CD, we need to focus on acceleration. Many of you are currently facing slow build, test, and deploy times with your CI/CD solutions, which is a common issue. Our goal is to enhance speed by integrating caching over existing GitHub actions and other underlying CI/CD infrastructure. This cache will serve as the orchestration layer in this scenario, which is crucial for achieving hardware and software co-design. So, what does this look like, and how does it improve upon traditional CI/CD? First, we need to establish our intake, which involves ingress shaping and rate limiting. |
Slide 9 — 4:58 (watch)
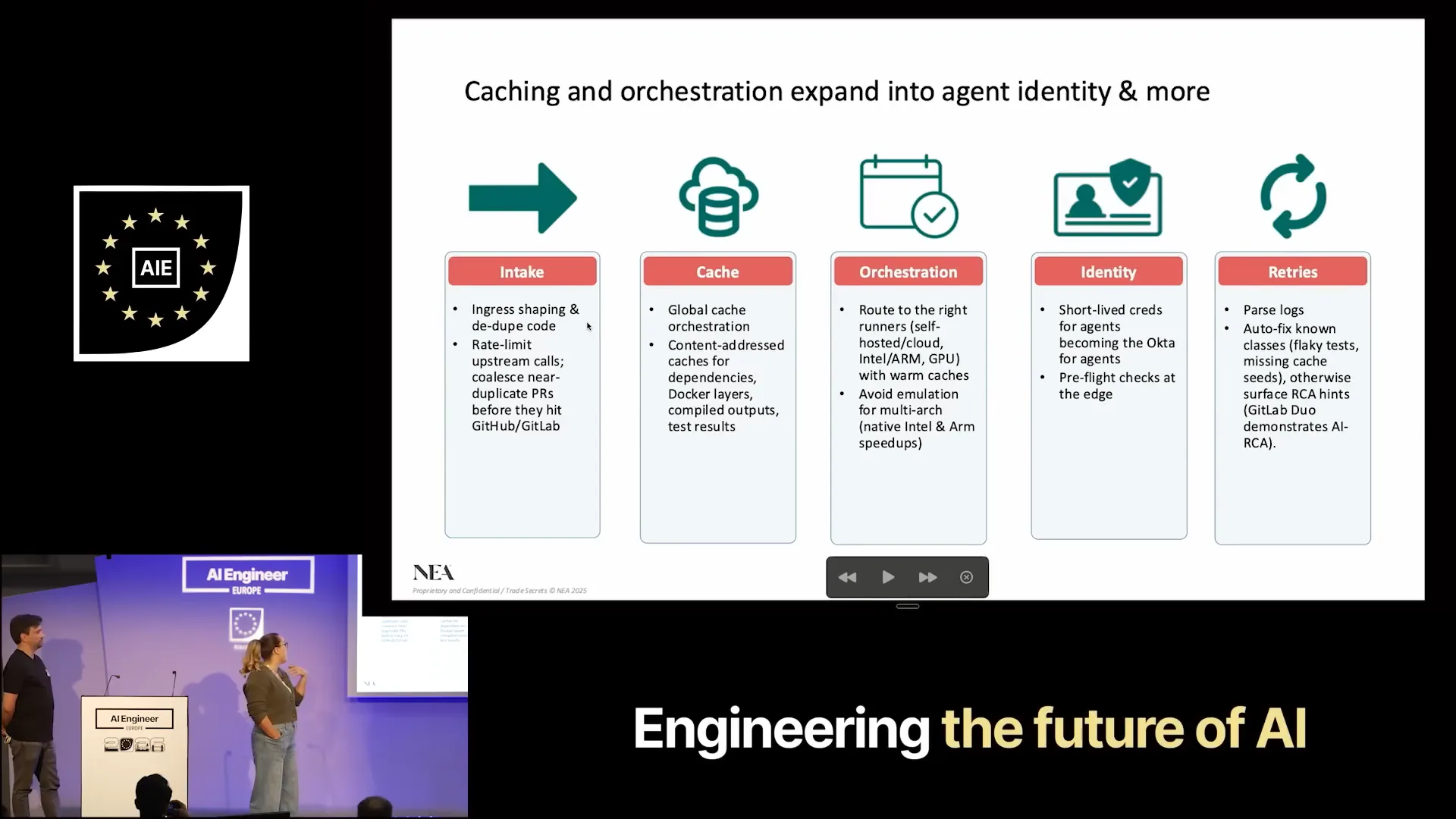 | Next, we move to our cache, which is a significant step. We need to consider how to orchestrate and ensure proper routing to the right infrastructure. From this point, we can also explore agentic identity for software and the concept of retries at scale. |
Slide 10 — 5:28 (watch)
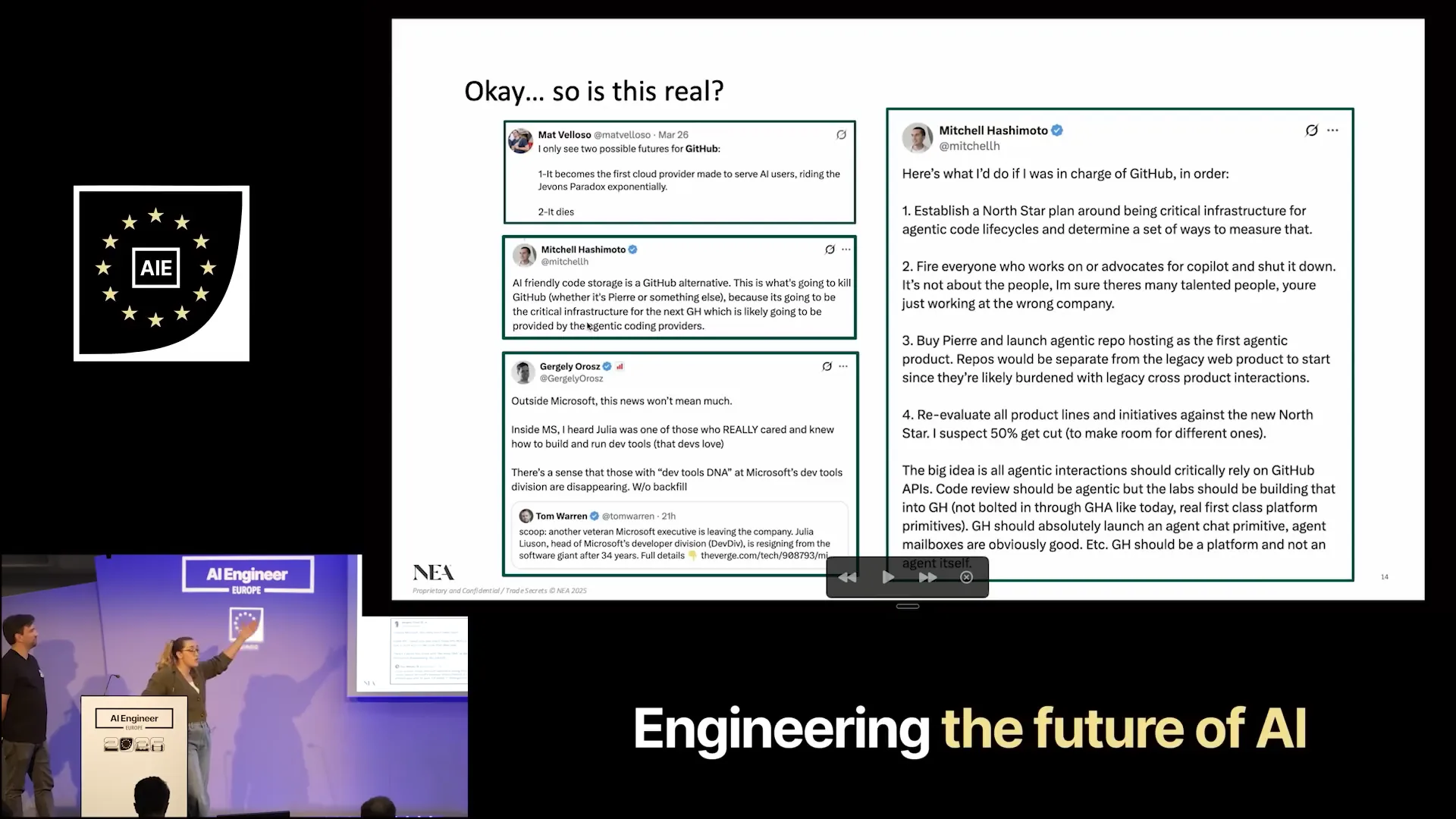 | If you don't believe me, let's consider the experts. Mitchell Hashimoto, a prominent developer advocate and the former founder of HashiCorp, outlined his vision for fixing GitHub today. His suggestions include shutting down Copilot and evolving GitHub to thrive in the cloud era while enabling inference at scale. Additionally, we have several other data points on the left-hand side that emphasize the need to prioritize AI and agentic users, or we risk failure. |
Slide 11 — 6:36 (watch)
 | Considering friendly code storage solutions may also help address frustrations with existing CI/CD processes, which are just the starting point. We have only begun to see agentic software take over. I will now pass it to Hugo, who will discuss what a real solution can look like. My team and I spend a lot of time with companies transitioning from traditional CI/CD to our vision of the future. To give you a hint, it's agents all the way down. We collaborate with companies like Fall, Zed, and Ramp, which are at the forefront of development. You may recognize yourselves in the transition between two phases: up to six months ago, humans were writing all the code, albeit slowly, and packaging changes in pull requests with validation as part of that process. Behind the scenes, machines were somewhat slow, but this was masked by human latency. Many of you may already be noticing the current trend where code generation is inexpensive, work is more continuous, and this shift forces validation into the inner loop. |
Slide 12 — 7:32 (watch)
 | Up to this point, you, as a human, are the agent. You have a goal in mind and navigate through various phases. For example, you start a pull request, but your team points out that you didn't follow the correct format, sending you back to the beginning. This puts you in a loop. Your changes are in the pull request, the tests are running, but they fail, requiring you to modify the code. |
Slide 13 — 8:06 (watch)
 | You find yourself back in the loop. A human reviewer points out that you didn't use the correct API and asks you to make changes. After addressing those, when you attempt to merge your code, you discover that another colleague has submitted code ahead of yours, forcing you to re-enter the loop. |
Slide 14 — 8:22 (watch)
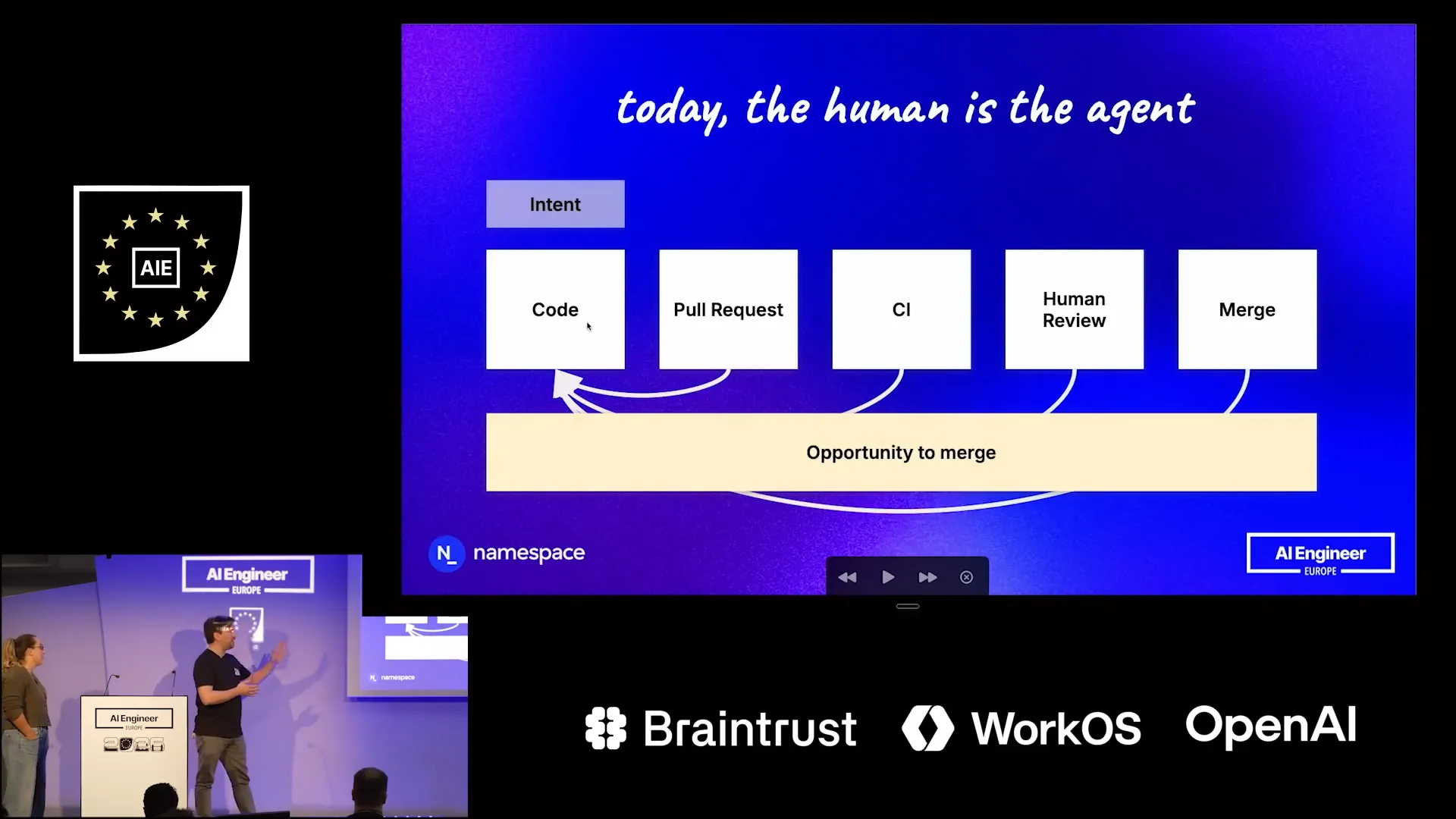 | When working at a human scale, the time from when you start coding until the code is merged into the repository can be significant due to the limited number of changes being made simultaneously. However, as you accelerate development, the opportunity to merge becomes crucial because the rate of change increases dramatically. |
Slide 15 — 8:54 (watch)
 | We discussed how the pull request (PR) serves as the unit of work, designed primarily for human review. It anticipates some delay in feedback and involves discrete handoffs, where the code is sent to the reviewer and then returned. Continuous Integration (CI) is crucial because it validates the work being done. It checks for issues such as potential regressions, ensures that the code compiles and builds from a known source, and identifies any conflicting changes that may arise. |
Slide 16 — 9:14 (watch)
 | Is this change allowed? All of this is part of the automated validation process. |
Slide 17 — 9:28 (watch)
 | Human reviewers are overwhelmed, a point that has been made repeatedly. |
Slide 18 — 9:50 (watch)
 | The act of merging resembles high-performance database challenges. It involves serialization and a single ledger where every change must be recorded. You need to lock the database to commit changes. The time required for locking is significant when humans are involved, but it is much shorter when machines are used. |
Slide 19 — 10:00 (watch)
 | The time to merge is crucial. |
Slide 20 — 10:24 (watch)
 | We need a new architecture. Our team is already working this way, and many leading companies are adopting similar approaches. There are no pull requests. We start with intent and planning, defining what we want to achieve and codifying it into a specification. This specification is documented, possibly in a linear ticket or on Slack; it is essential to have a written record of the goal. This process feeds into a loop, which is a typical agent harness. It could involve your cloud code, and in our case, we often use AMP, but it might also include tools like Cursor or Factory. |
Slide 21 — 11:14 (watch)
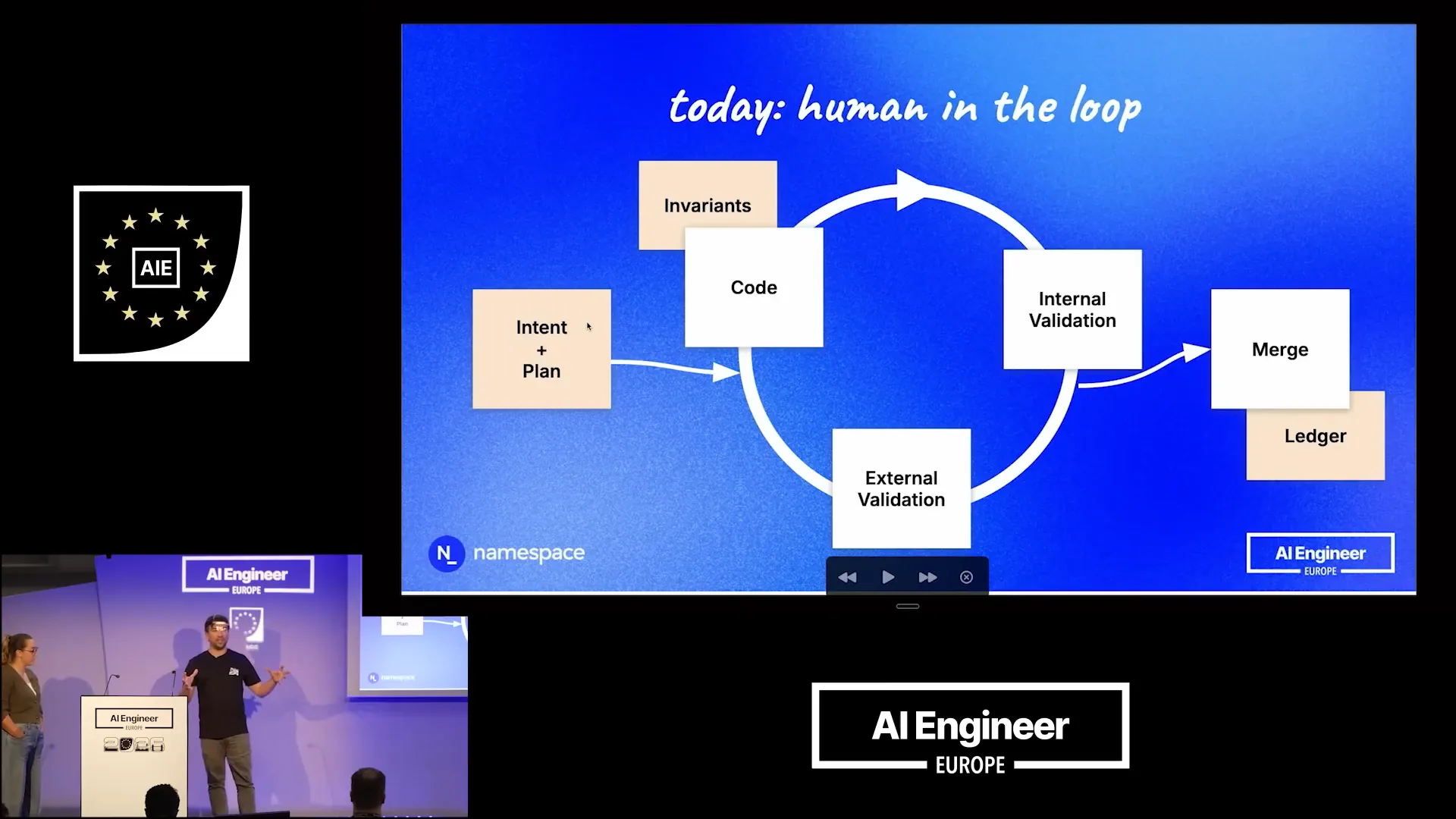 | The agent enters a loop where it checks out your code and begins implementing your plan. It utilizes established invariants and checks out a well-known commit to ensure it doesn't start from an arbitrary point. Internal validation involves using existing assets in the repository to verify that the change is correct; it builds and tests the code. After completing these steps, it notifies you, asking if everything looks good or if any changes are needed. You can respond with "yes" or "continue," which is the term we use most frequently. The agent then resumes executing the plan. Once everything is complete, the code enters the merge queue and is recorded in the ledger, with your Git repository serving as that ledger. |
Slide 22 — 11:50 (watch)
 | This process is fast, but not fast enough, as it still requires a human in the loop for external validation. |
Slide 23 — 12:12 (watch)
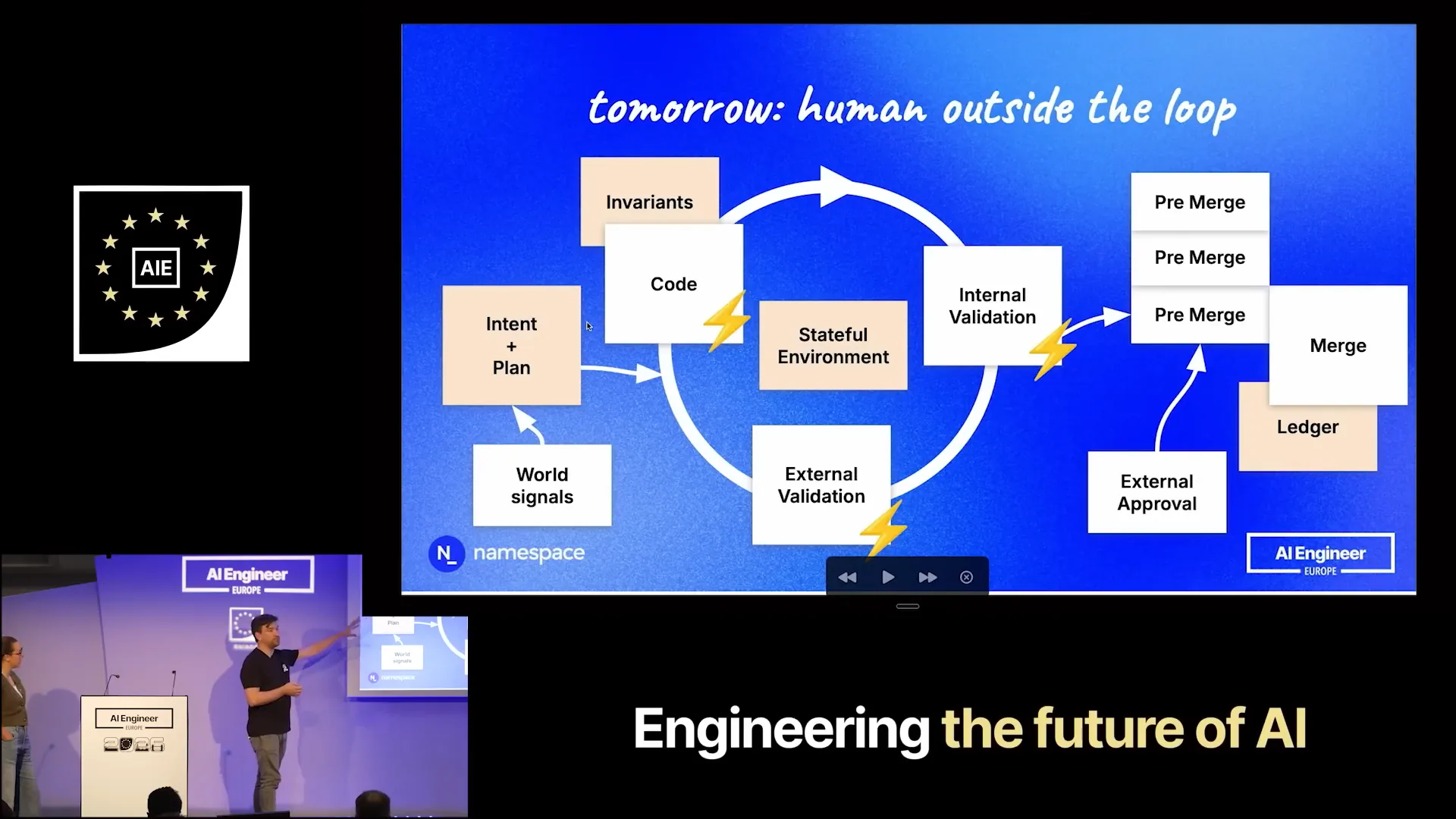 | We are moving towards a future where code generation occurs within weeks to months, rather than years. Although it is already fast, inference will continue to improve and become even quicker. |
Slide 24 — 12:40 (watch)
 | External validation, including running builds and tests, must be extremely fast. Spending 15 or 45 minutes on tests delays the entire loop. In this process, external validation no longer involves humans; instead, other agents evaluate the changes. For example, a security-focused LLM or an API conformance-based LLM provides feedback within the loop, which the main harness quickly incorporates back into the code. |
Slide 25 — 13:18 (watch)
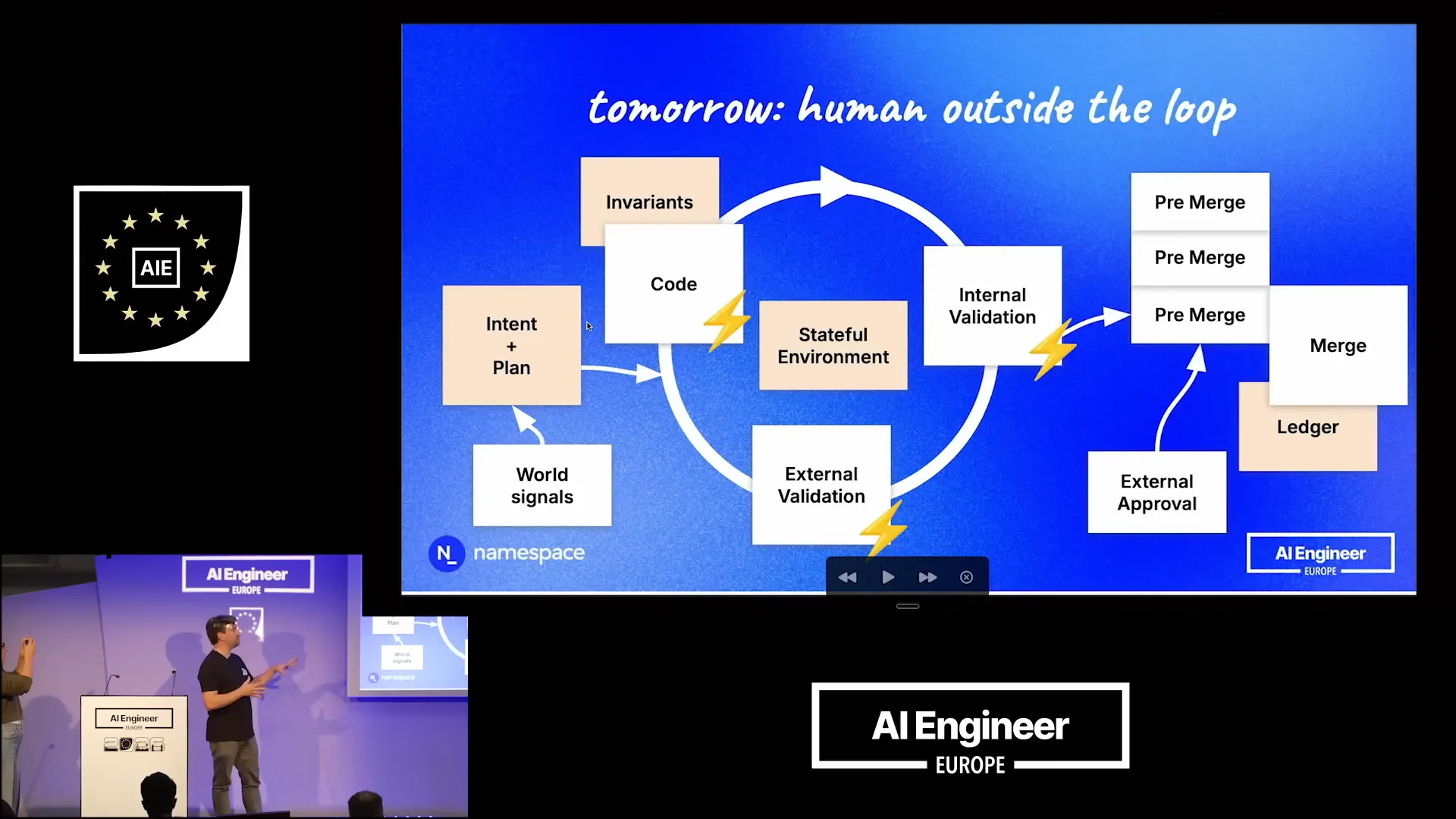 | To operate efficiently, the system must run in a stateful environment. Maintaining state is crucial; if processes are continually restarted from scratch, it will only introduce further delays. Therefore, statefulness plays a vital role in this feedback loop. |
Slide 26 — 14:12 (watch)
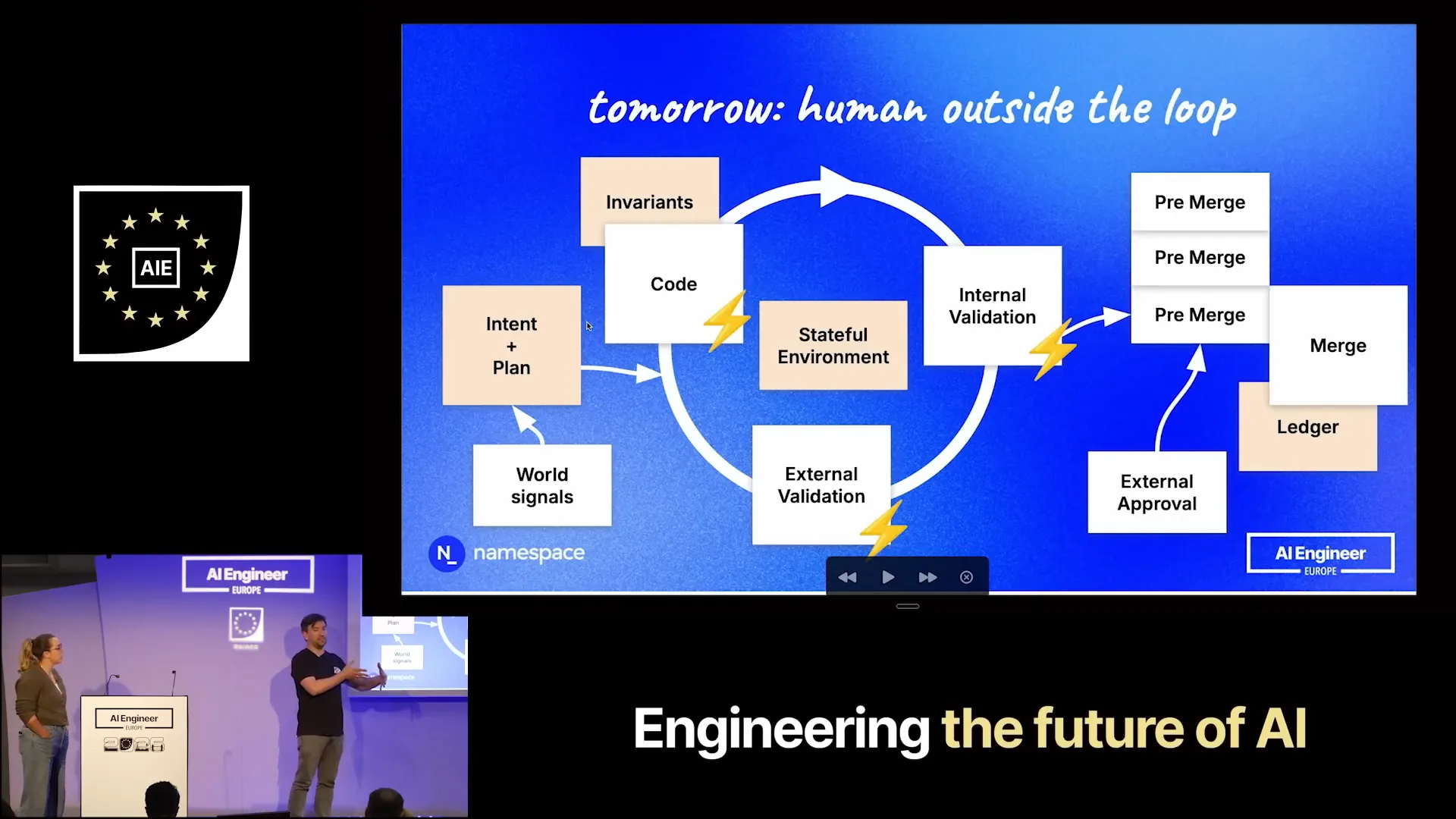 | You receive world signals intermittently, such as changes in plans or updates from others. The harness adapts its intent and plan, creating a new loop. When you finish, due to the numerous ongoing changes and the team's lack of acceptance of these changes, you do not go directly into the repository. Instead, you enter a pre-merge queue, where changes are held that would have been merged if the merging process were faster. In reality, many changes run in parallel and operate on the same parts of the codebase, necessitating a process to reconcile them to ensure serializability. This guarantees that all changes are recorded sequentially in your ledger and repository. At this stage, external approval is required. A human reviews not just the code but also the intent and the resulting output, which could include a video demonstrating the feature or the results from a security-focused LLM regarding the specific change. |
Slide 27 — 14:50 (watch)
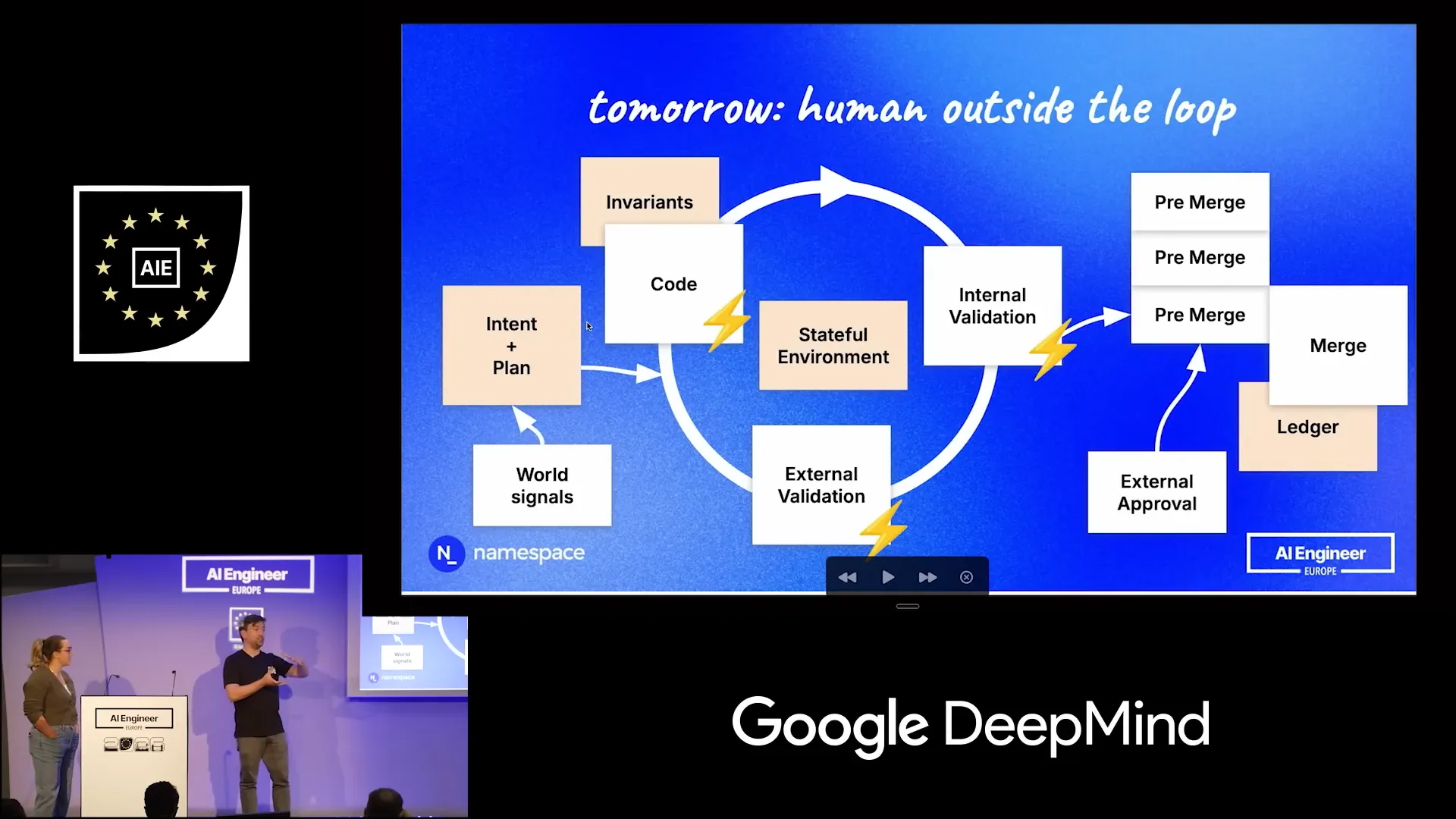 | It is not limited to a single commit or pull request; it can involve multiple commits. You may have several agents independently working on features that are added to this pre-merge queue. These features are semantically grouped into a manageable set for you as a human, as the volume will be too large otherwise. |
Slide 28 — 15:06 (watch)
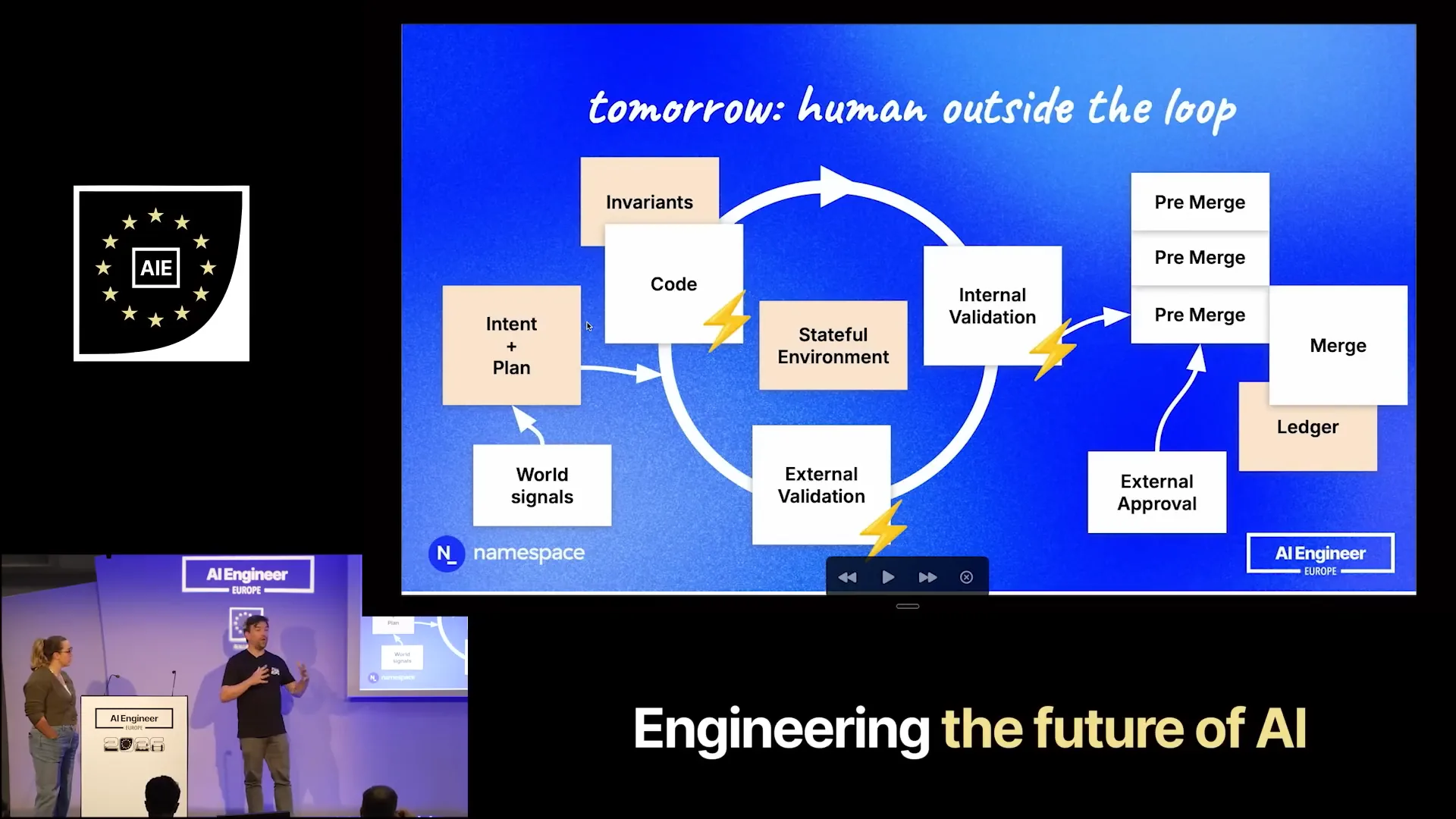 | We already observe this trend within our team; the volume of what we call pull requests has increased to four times its previous level. |
Slide 29 — 15:20 (watch)
 | It is impossible for a human reviewer to examine every single pull request. |
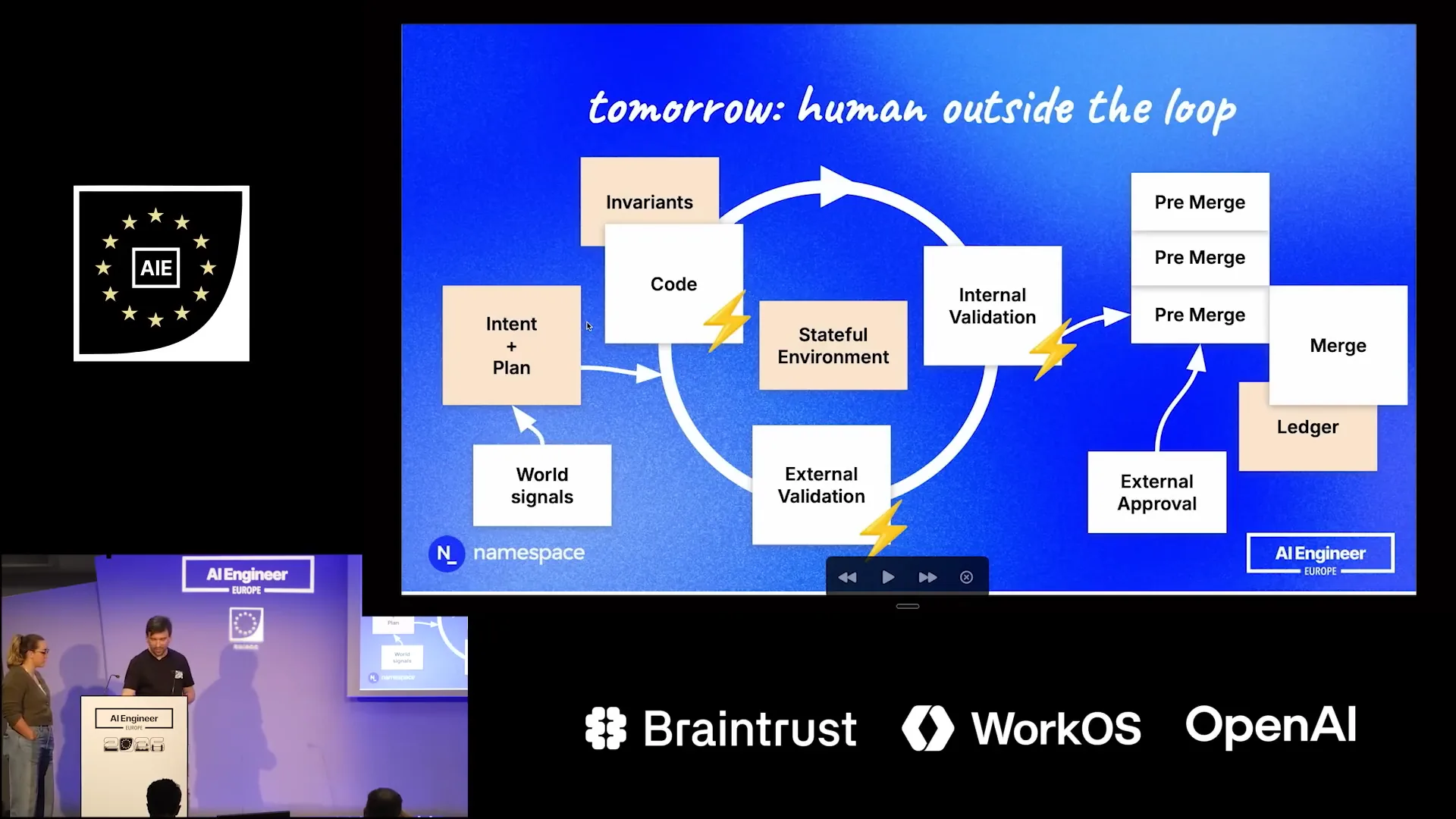
Slide 30 — 15:36 (watch)
 | Looking ahead, if this process becomes extremely quick, we may need to consider a multiverse approach. In this scenario, the starting point for intent and planning would not be the latest commit in your repository, as that is constantly changing. |
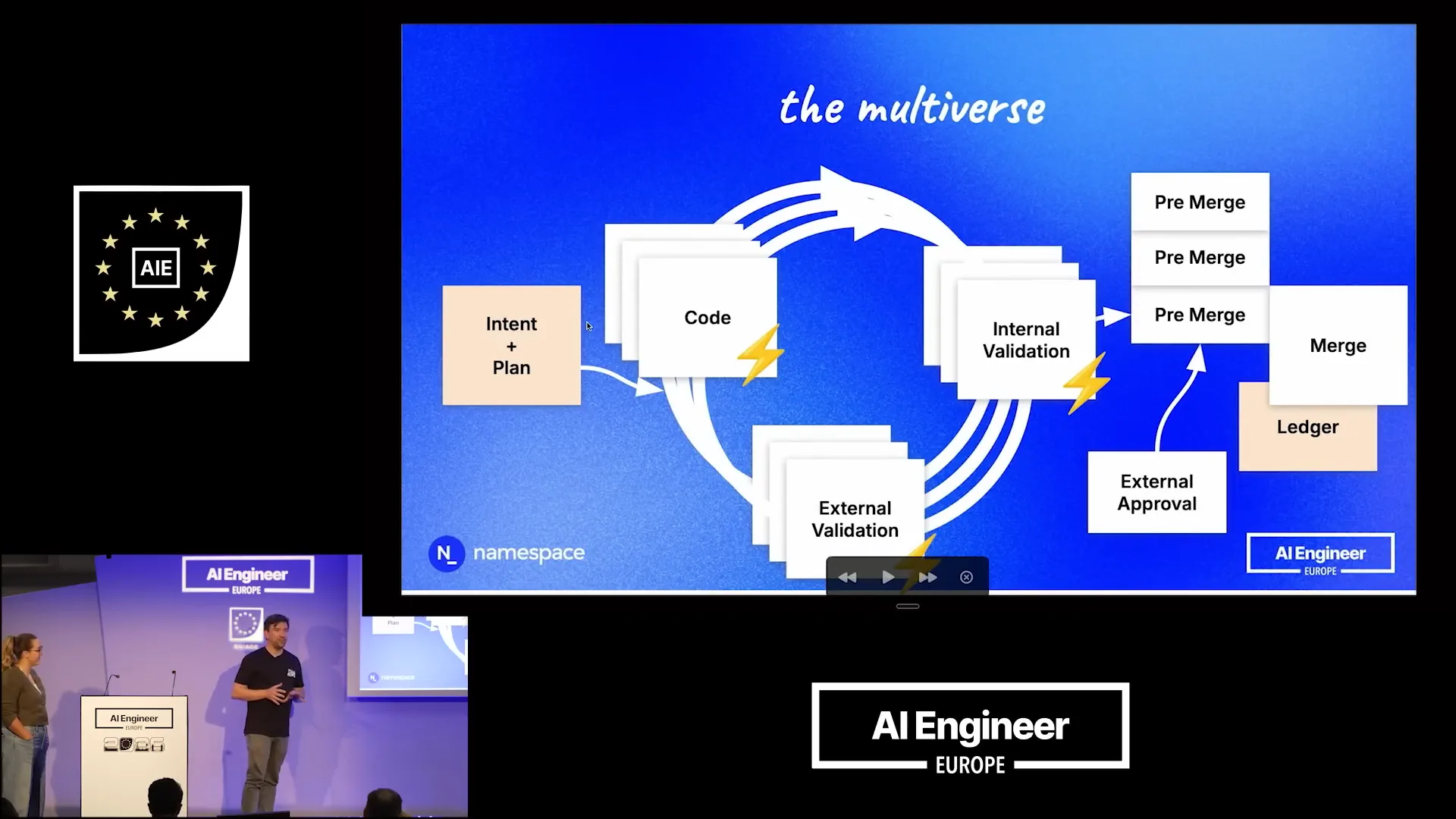
Slide 31 — 16:06 (watch)
 | There are many candidates, so the agents may work on multiple commits simultaneously to address the same plan. To achieve this, the inner loop must be extremely quick, which increases capacity and leads to significant resource usage due to the number of candidates being explored at the same time. This is the direction we believe we are moving towards. |
Slide 32 — 16:32 (watch)
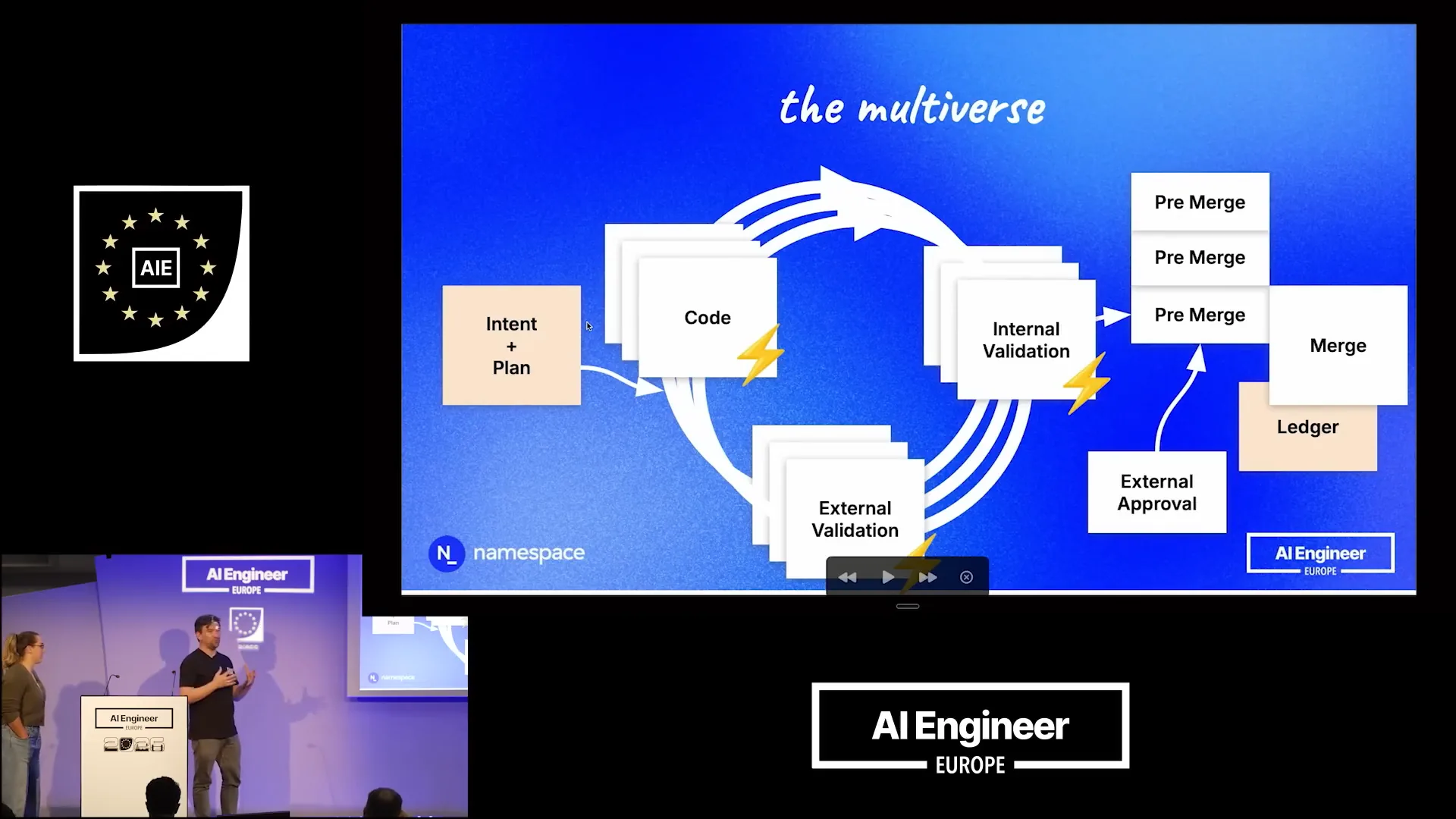 | We prioritize performance and efficiency, dedicating significant effort to maintaining efficiency within this loop. A key aspect is to avoid unnecessary work and not to start projects from scratch repeatedly. Instead, we should enable agents to operate more incrementally, similar to how engineers work on their own workstations. |
Slide 33 — 16:44 (watch)
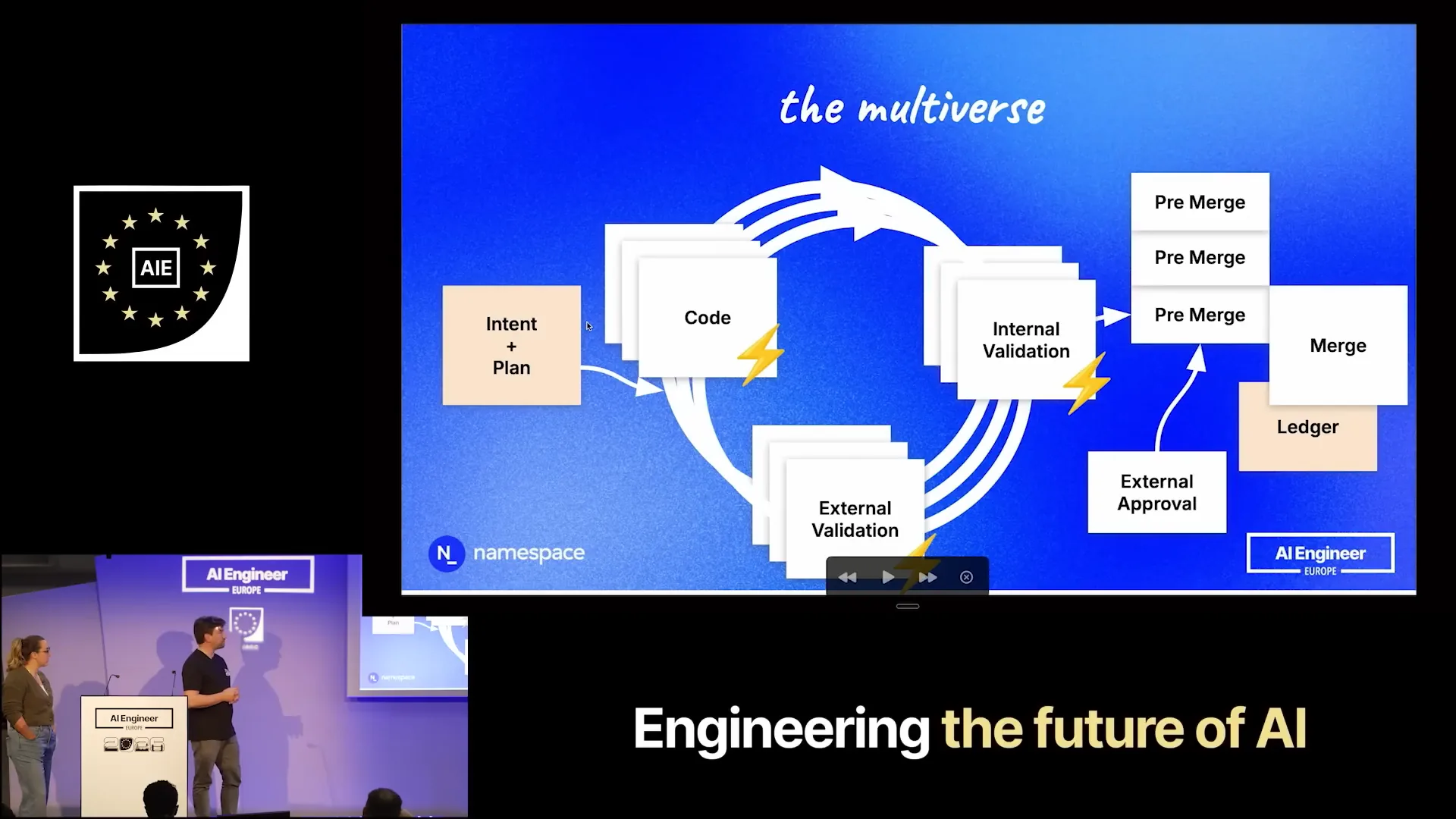 | We are moving towards a world where this approach becomes the norm. |
Slide 34 — 16:58 (watch)
 | Did CI go away? CI still matters, but it has shifted. The principles, such as whether the code actually works, are no longer a separate phase; they are now part of the continuous loop. Every iteration now includes validation. |
Slide 35 — 17:16 (watch)
 | It is still important to enforce those invariants as well. |
Slide 36 — 17:24 (watch)
 | For compliance reasons, it's essential to ensure that you start from a well-known checkout. This prevents the risk of someone in your company adding unvetted code that could compromise the integrity of your system. |
Slide 37 — 17:38 (watch)
 | These invariants must still be enforced, but on a continuous basis. Coordination shifts away from continuous integration (CI), meaning CI no longer needs to manage different changes or ensure that tests pass before changes can be committed. |
Slide 38 — 17:54 (watch)
 | Governance must be integrated into the overall loop. While it remains important, it becomes more embedded within the harness, which guides changes to adhere to the processes your team has established. |
Slide 39 — 18:08 (watch)
 | We believe that the world is moving towards this direction. If you're interested in this topic, we at Namespace have dedicated significant time to exploring it. |
Slide 40 — 18:18 (watch)
 | There are others in the industry who are also preparing for this rapidly changing environment. Thank you, and let's go for lunch. |
Slide 41 — 18:30 (watch)
 | Thank you. |