43 slides extracted.
Slide 1 — 0:48 (watch)
 | Hello, everyone! Let's dive right in. Over the past few years, developers have developed a series of bad habits due to slow AI code generation. We often write massive prompts and attempt one-shot completions, make large commits, or have multiple agents on screen simultaneously, all trying to process information. About a month ago, we at Cerebras and OpenAI released a state-of-the-art model called CodeX Spark, which can generate code at 1,200 tokens per second. In contrast, the Sonnet and Opus families generate code at only 40 to 60 tokens per second. This new era of coding models, which are 20 times faster, not only unlocks new capabilities and use cases but also requires us to rethink how we interact with these coding models. If we don't address our previous bad habits, which generated around 50 tokens per second of poor code, we risk generating 1,200 tokens per second of bad code. This is the focus of today's talk. My name is Sarah Chang, and I am the head of developer experience at Cerebras, where we are building the world's largest and fastest AI processor. |
Slide 2 — 2:24 (watch)
 | A significant part of my role involves introducing fast inference and coding models to developers for the first time. For many, this is an exciting moment, as it eliminates the frustration of delays and startup times. However, as I mentioned, unless we change our habits, we will struggle to produce quality code in the future. This talk serves as a practical playbook for how we, as developers, can adapt to interacting with models in this new environment, particularly as these models begin generating code faster than we can manage. Looking back at recent history, we’ve experienced remarkable advancements. Models have become larger and smarter, with increased context windows. However, coding speeds have remained relatively stable over the past two years. For instance, popular model families like Gemini, Claude, GPT, and Sonnet have consistently operated within a range of 50 to 150 tokens per second. |
Slide 3 — 3:26 (watch)
 | This is CodeX Spark, the first of many models that developers can expect to be significantly faster than previous versions. We even had to adjust the y-axis on our graphs to accommodate this increased speed. Before diving into the playbook and tips, let's discuss why we are suddenly seeing such faster models. This is an exciting development, driven by numerous companies tackling the same challenges simultaneously. As a result, the entire AI inference stack is being optimized collectively. To break it down quickly, we start with hardware, which is the physical device where inference and training occur. One major consideration with hardware is the memory wall, which contributes to 50 to 80% of the latency time for inference. This is a significant source of frustration in the process. |
Slide 4 — 4:26 (watch)
 | When running inference, we must constantly move our weights and key-value cache values between memory and the chip. On traditional NVIDIA GPUs, this memory is stored off-chip in high-bandwidth memory (HBM), leading to a memory bandwidth bottleneck. Newer companies like Cerebras and Grok are exploring ways to move memory closer to the chip. For example, the Cerebras wafer distributes all memory across the chip in SRAM, allowing every core direct access to the values it needs. Additionally, disaggregated inference has recently become commercialized, which is one reason NVIDIA acquired Grok for $20 billion. Cerebras and AWS are also partnering to integrate the wafer with AWS Tranium. |
Slide 5 — 5:02 (watch)
 | In traditional inference, there are two steps: pre-fill and decode. Both steps have typically been executed on the same hardware. Pre-fill involves processing every token input by the user, embedding it, and adding it to our KV cache. This step can occur in parallel and is compute-bound. |
Slide 6 — 5:22 (watch)
 | Decode is the process of generating the output token by token, which is sequential and memory bound. This leads to the same issues we discussed earlier. Currently, we are separating these two steps: pre-fill is performed on hardware optimized for computation, while decode is executed on hardware optimized for memory. The diagram illustrates this separation as we examine the model architecture. |
Slide 7 — 5:46 (watch)
 | We have numerous methods for training and shaping our models to optimize for our hardware. We consistently consider specific layer dimensions, memory, and model size. A prime example of this is the mixture of experts architecture. |
Slide 8 — 6:04 (watch)
 | Instead of activating the entire model for every token, we activate only a subset of experts each time. This approach enables us to leverage the intelligence of a much larger model while incurring the compute cost of a smaller model. |
Slide 9 — 6:24 (watch)
 | We continuously consider memory and model size. Recently, many have built upon this concept, including REAP, or router-weighted expert activation pruning. In this approach, we identify experts that are not activated at all and prune them from the model entirely. This helps us reduce the overall model size. |
Slide 10 — 6:52 (watch)
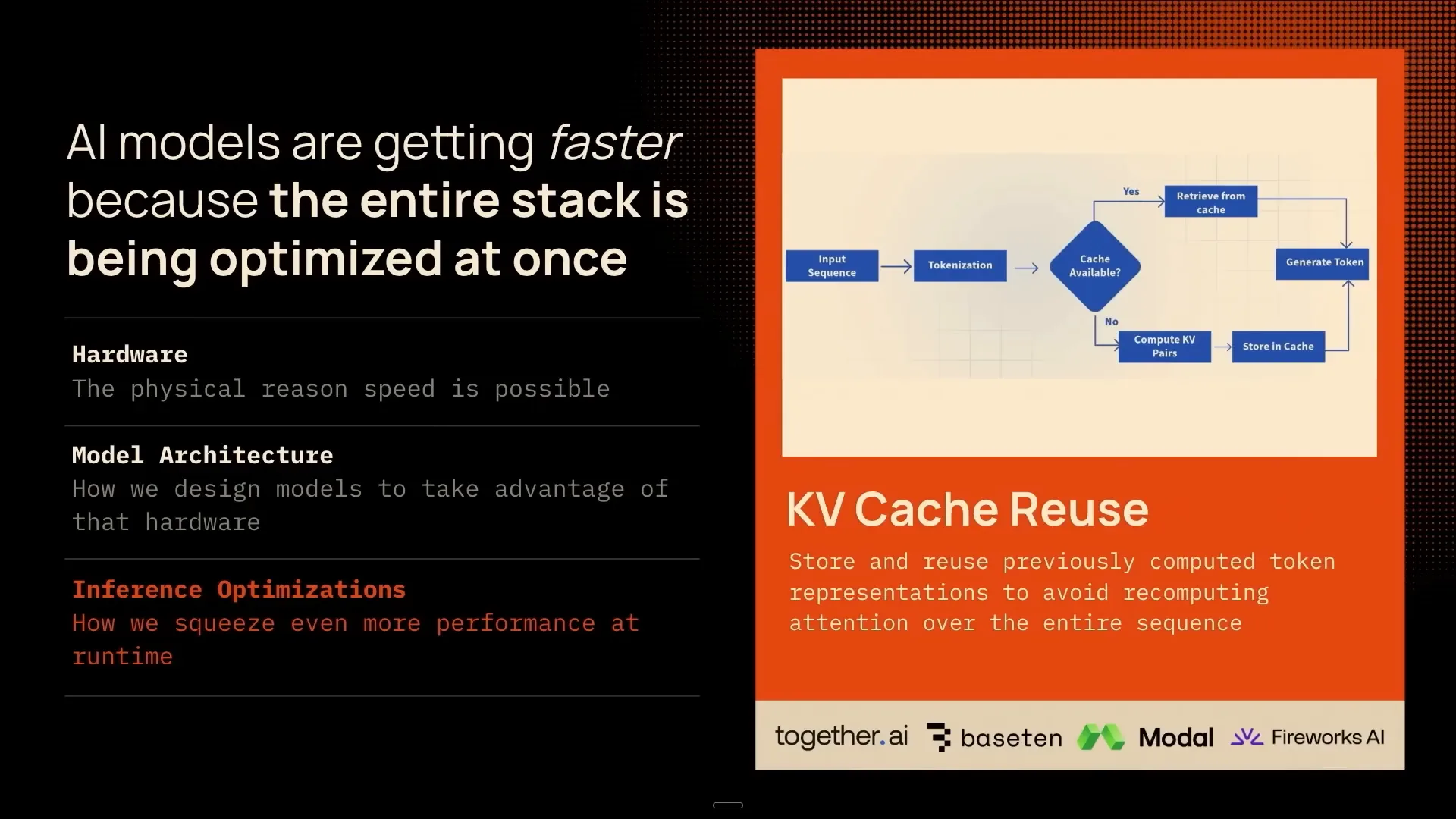 | At the top layer of the stack, we focus on inference optimizations, an area where many of you may be working, along with companies like Together, Base10, and Modal. A key consideration at this level is KVCache reuse. By storing and reusing previously computed token representations, we eliminate the need to recalculate attention over the sequence at every step. |
Slide 11 — 7:38 (watch)
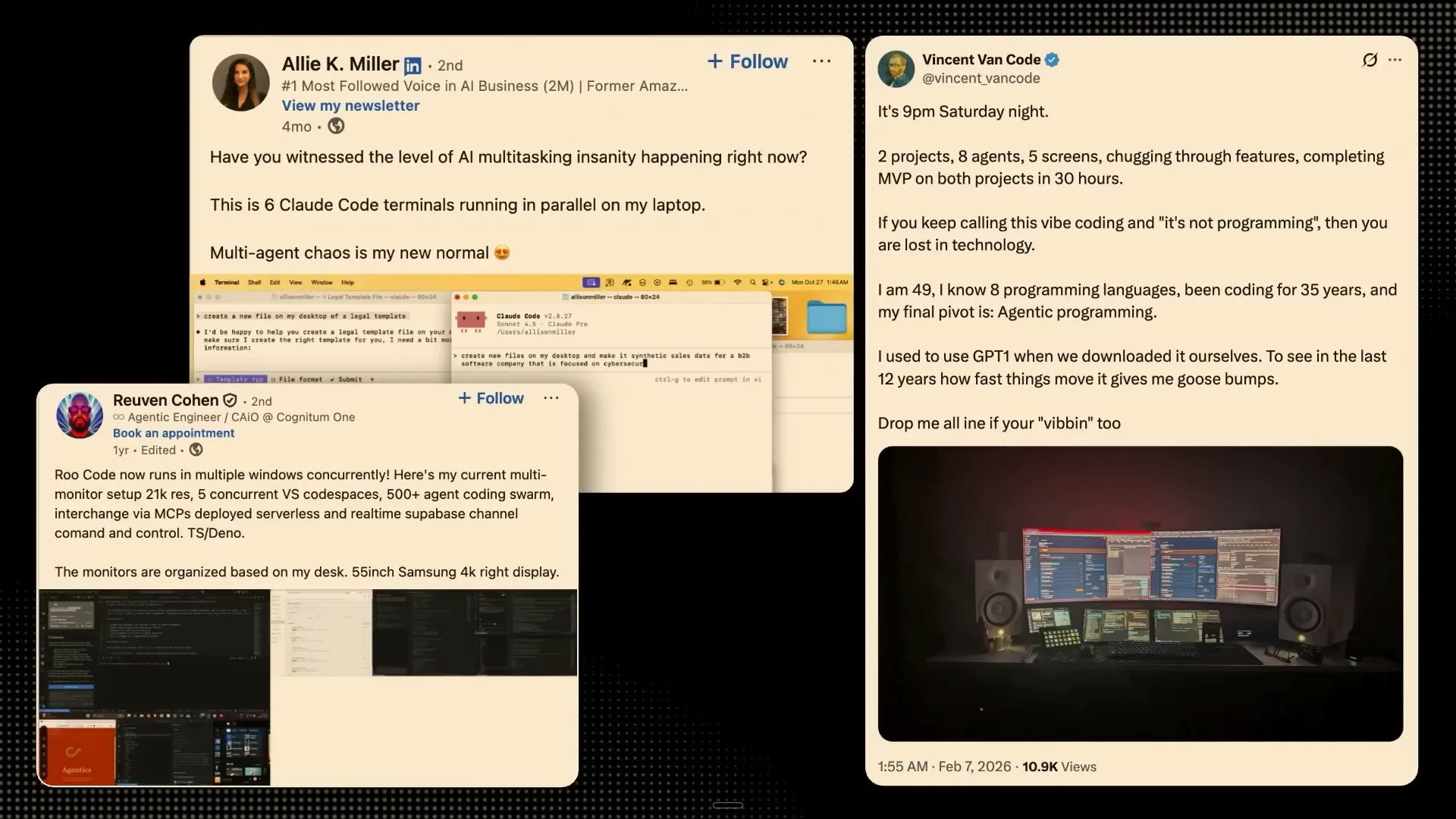 | Now, I want to focus on the most exciting aspect: the developer. This is the current state of the internet, exemplified by platforms like Twitter and LinkedIn. We see individuals running multiple cloud code terminals simultaneously, with coding swarms of over 500 agents and others managing eight agents across five screens. It’s tempting to engage in such setups. If you’re active on Twitter, it often feels like if you’re not doing something similar, you’re falling behind in the tech world. However, the reality is that we are generating vast amounts of code that often go unverified. With the advent of much faster inference, this situation becomes increasingly precarious. Fast inference will lead to unprecedented levels of technical debt, and we may struggle to manage it effectively. |
Slide 12 — 8:18 (watch)
 | I will now pivot to discuss practical playbooks, tips, and workflows for developers operating in this new regime of faster inference. CodeX Spark operates at 1,200 tokens per second, but it is just the first model in what we, as developers, should expect and prepare for: a new era of faster models across the board. |
Slide 13 — 8:28 (watch)
 | The first category involves selecting the right models and orchestrating our agents to leverage the strengths of different models. |
Slide 14 — 8:48 (watch)
 | Historically, we have focused on intelligence in model selection. Developers tend to be adaptable, often switching to the model or family that demonstrates the highest intelligence at any given time. Cost is also a consideration, unless the company covers all expenses. |
Slide 15 — 9:06 (watch)
 | The inference speed shows a 20x difference. We also need to consider speed as a vertical. A good mental model is to use a larger model like GPT-5.4 or GPT-5.3 for planning or long-horizon workflows, while employing a faster model like CodeX Spark as the executor. |
Slide 16 — 9:22 (watch)
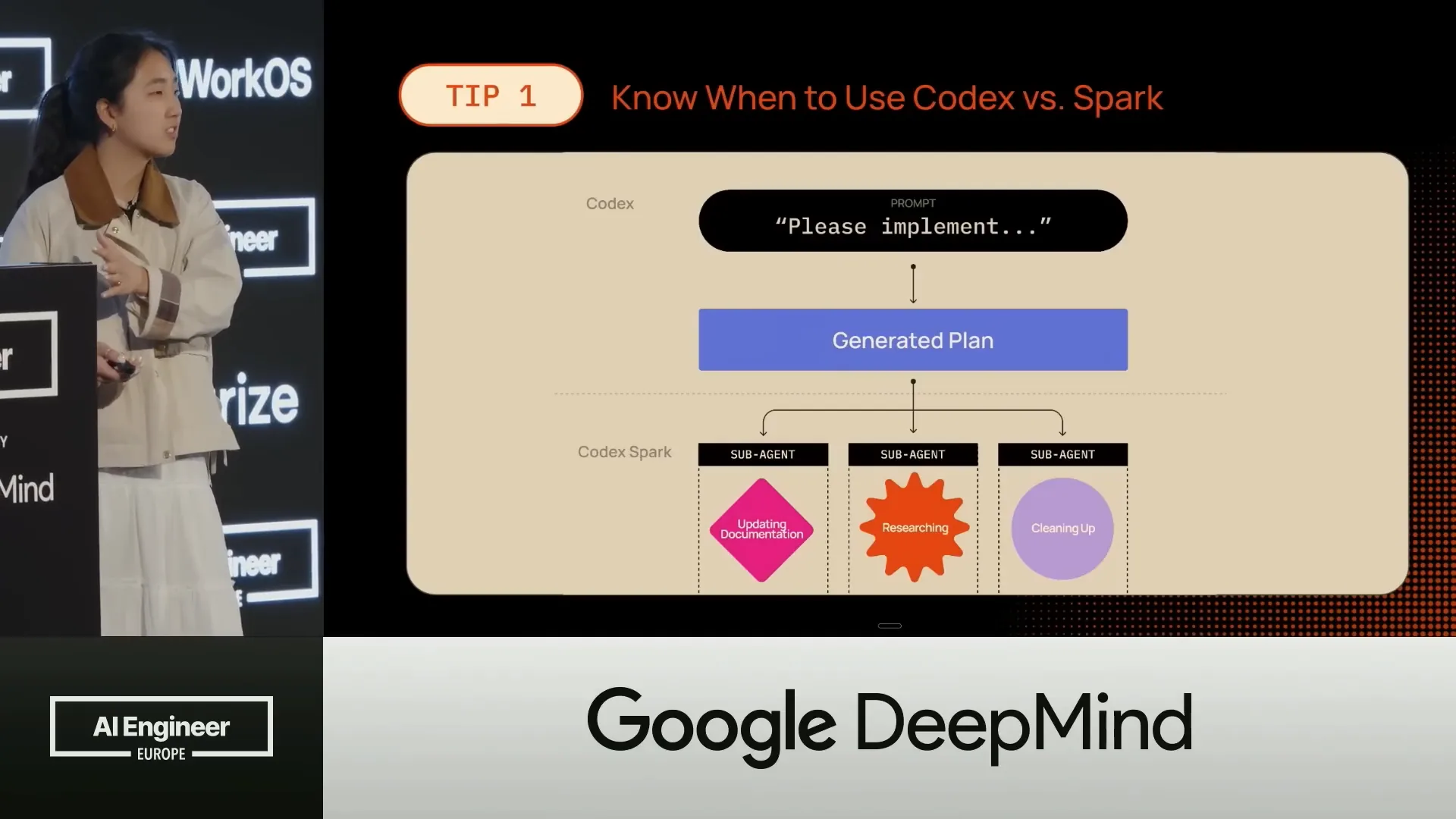 | For example, you could ask GPT 5.4 to generate your plan. Then, you would spawn all of your sub-agents using CodeX Spark to execute each step one by one. |
Slide 17 — 9:44 (watch)
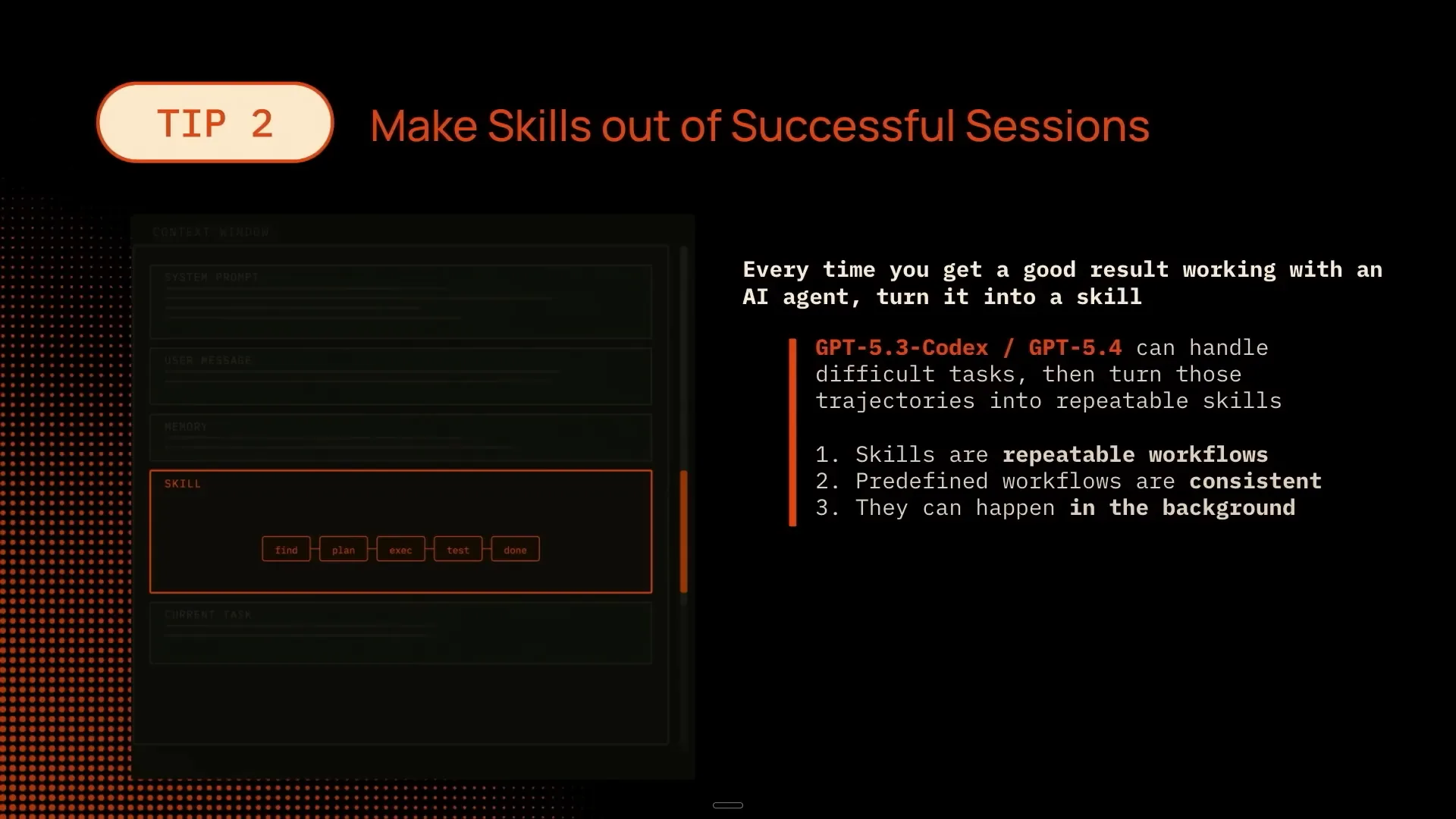 | Another helpful technique is to create skills from successful sessions and capture effective trajectories. You can use a model like GPT 5.4 to handle the initial, more complex task, and then save that as a skill, creating a verifiable and repeatable workflow. Subsequently, a faster agent like CodeX Spark can execute this workflow repeatedly in the background. |
Slide 18 — 10:04 (watch)
 | The next category is particularly exciting because it encompasses capabilities that were previously impossible or impractical. These are tasks we avoided due to the extensive deliberation and gesturing involved. |
Slide 19 — 10:30 (watch)
 | I want us to internalize the significance of this. At 1,200 tokens per second, a model like CodeX Spark makes validation essentially free. There is no excuse for not implementing practices such as test suites, linting, pre-commit hooks, diff reviews, and browser-based QA automations. You can integrate these processes into every step of your workflow because they are instantaneous. This approach does not slow you down, allowing you to perform these tasks continuously rather than waiting until the end or just before pushing your code. |
Slide 20 — 10:58 (watch)
 | One effective strategy is exploring cherry-picking. For example, if I want to code a nav bar in midnight blue with four different icons, I can provide this request to the model and receive a satisfactory result. However, with CodeX Spark or a faster model, I can instruct it to generate 15 versions in the same time it would take a previous model to produce just one. This allows me to select the version I like best. |
Slide 21 — 11:38 (watch)
 | I can generate five sub-agents, each producing 15 versions, resulting in a total of 75 versions from which I can select the best. This approach is particularly beneficial for scenarios where quantity or variety is essential, such as exploring research directions, different architectural options, or graphic design. I appreciate this method because it allows us to artificially induce taste into our model outputs. Traditionally, it's well-known that it's easy to identify any UI or text generated by a model, as they lack inherent taste. We have typically worked around this limitation by creating examples ourselves, finding suitable examples for the model, which is time-consuming, or providing overly detailed prompts that essentially complete the task for us. This new approach saves time and yields significantly better results. |
Slide 22 — 12:30 (watch)
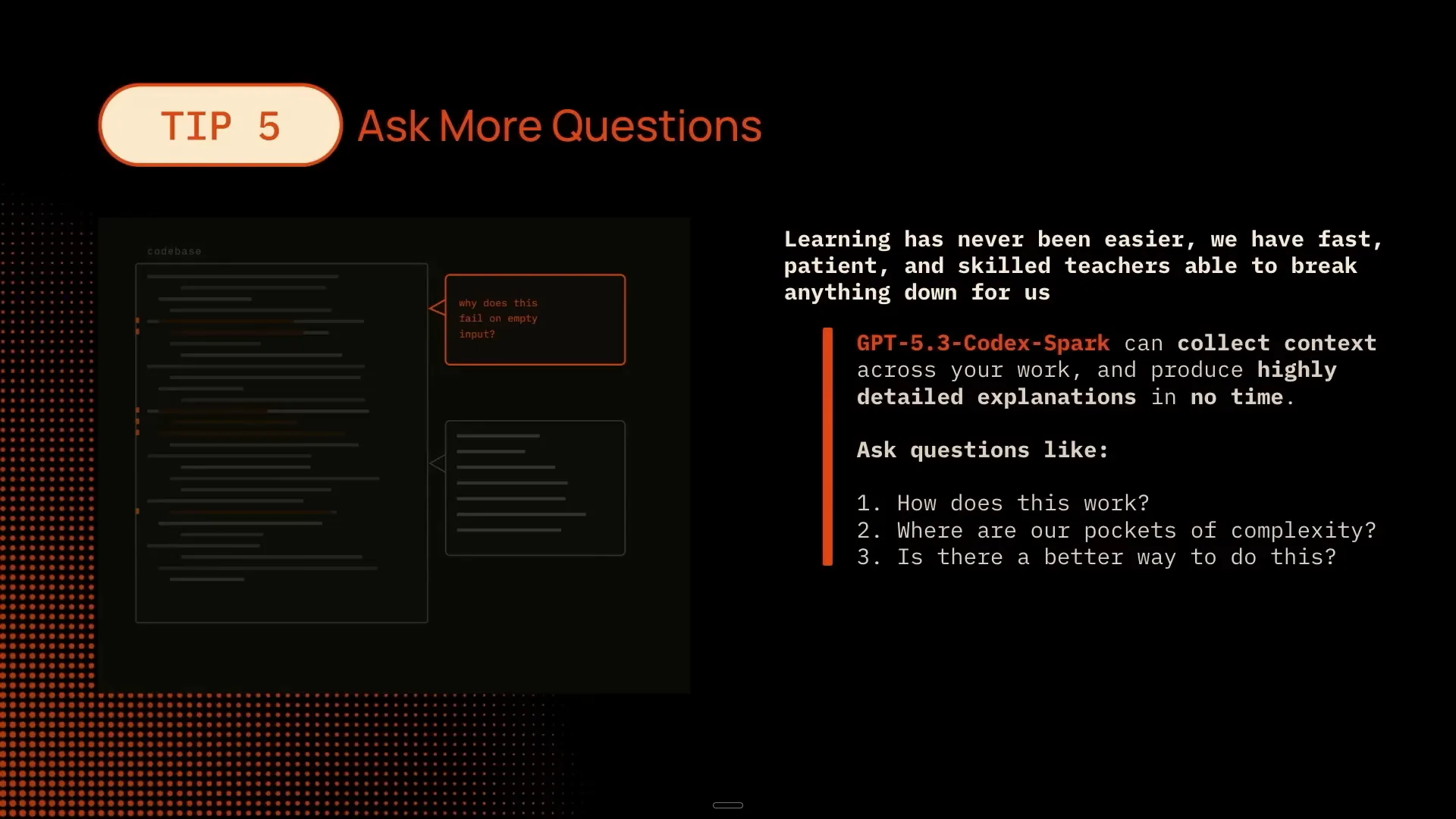 | The next tip is more of a mental model. With the models being so fast, you should not spawn a session and then leave to get a hamburger or scroll through Twitter. Instead, you can engage in real-time collaboration with the model. View this interaction as a pure programming experience; this approach is essential to avoid producing bad code. You can sit down and ask questions, such as having the model collect all the context from your repository and inquire about how it works. You should be the one in the driver's seat, making decisions and implementing changes. The AI should assist you in making decisions, not the other way around. |
Slide 23 — 12:56 (watch)
 | I dislike this slide because it features an overused term that triggers strong reactions. The question is, how do we avoid slop? |
Slide 24 — 13:10 (watch)
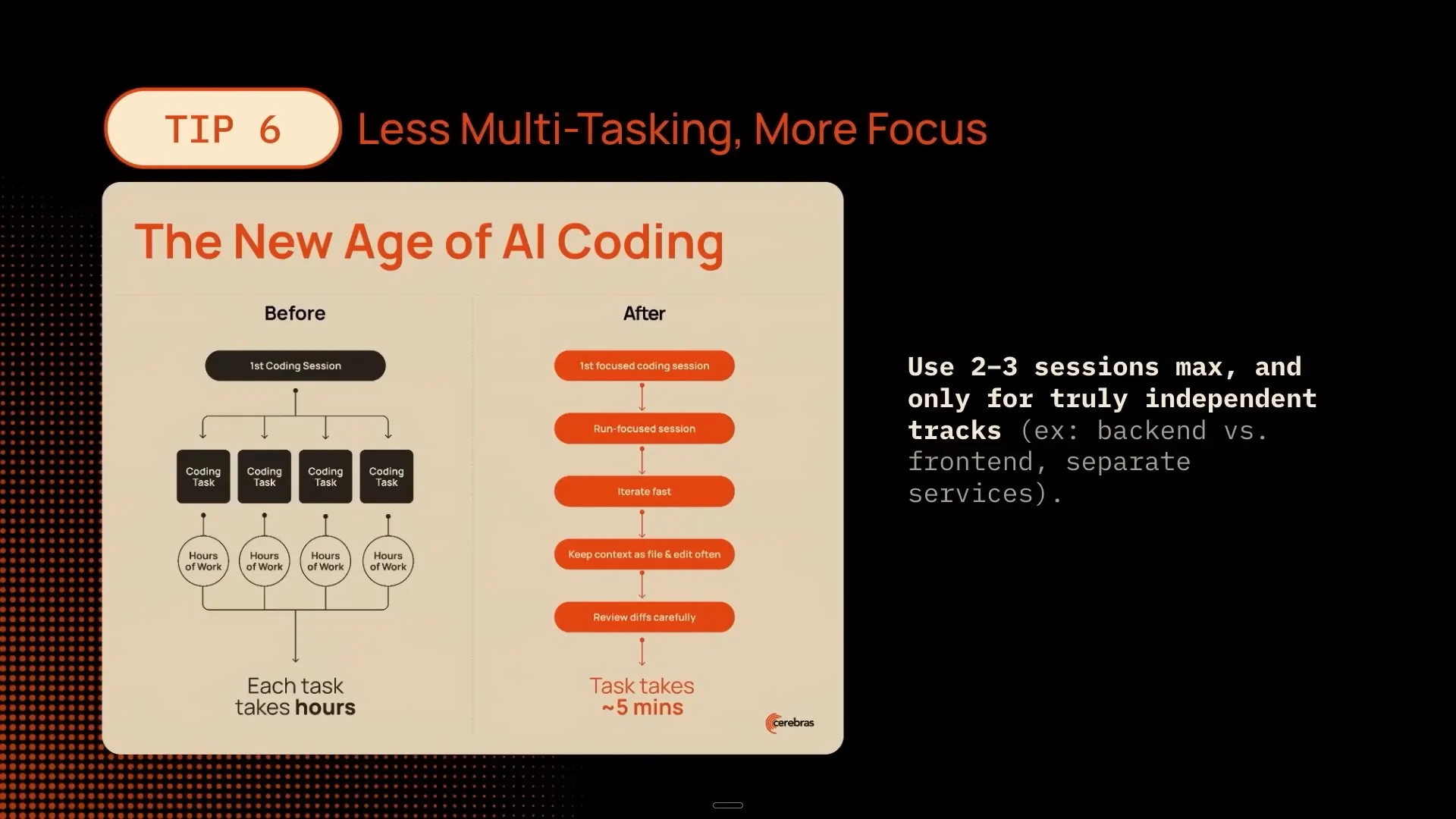 | It’s important to avoid spawning multiple agents without verifying the code. If you do this, you may find yourself reading the code for the first time when asked to explain it. Instead, take the time to have two to three sessions where you sit down with your code. Although this may be unfamiliar, engaging directly with the code allows you to understand what’s happening. We are now experiencing real-time collaboration as we code with this agent. |
Slide 25 — 13:36 (watch)
 | You can be very specific with the model's capabilities. For instance, you can prevent it from deleting files, set a maximum diff size, restrict it to read and write operations, and provide steering directions such as "only change this," "don't touch types yet," or "that implementation wasn't quite right; let's redo that." |
Slide 26 — 13:46 (watch)
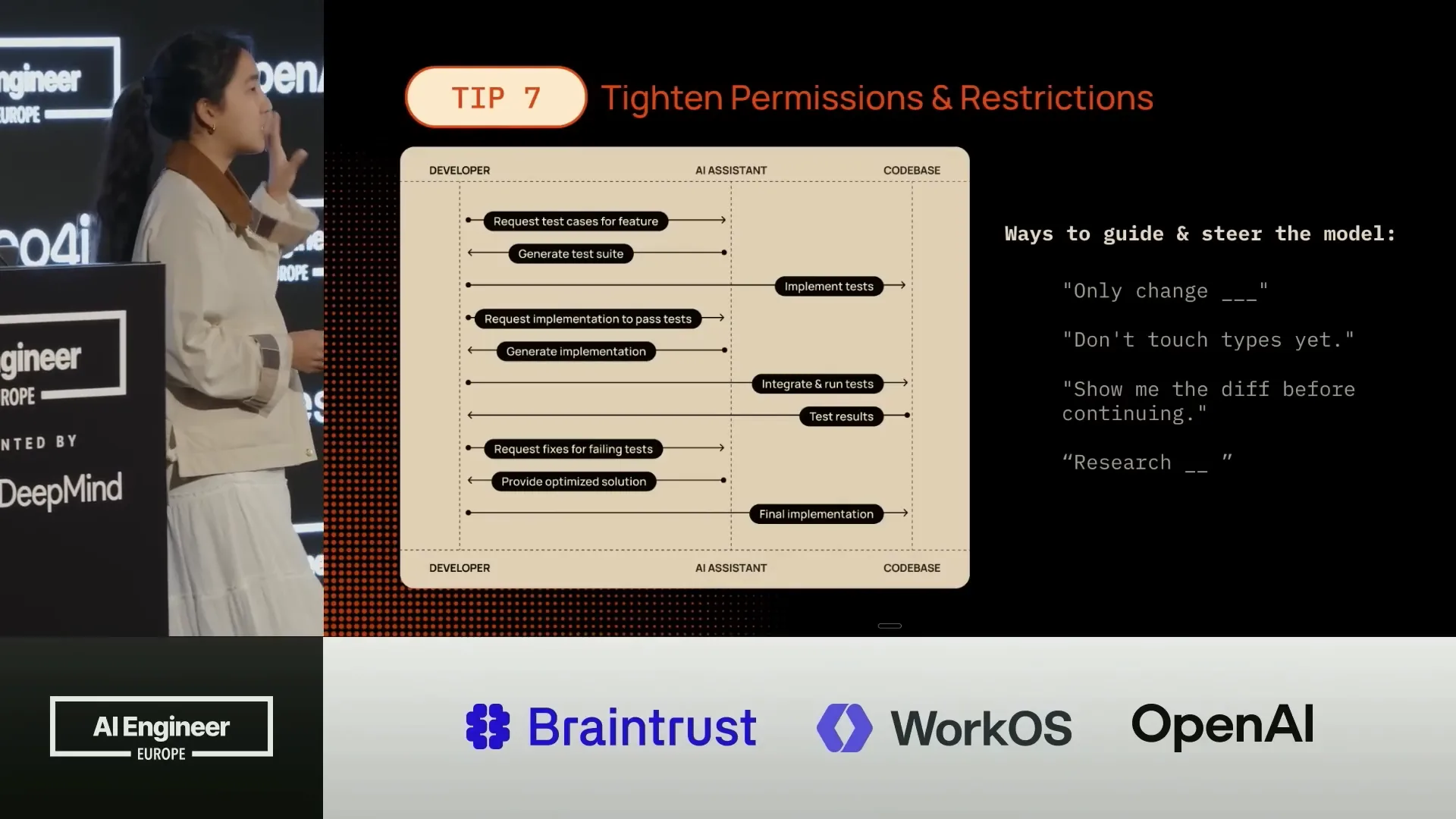 | The graph on the left serves as a useful mental model, illustrating how the developer, the AI agent, and the codebase can collaborate effectively and what that interaction should resemble. |
Slide 27 — 14:12 (watch)
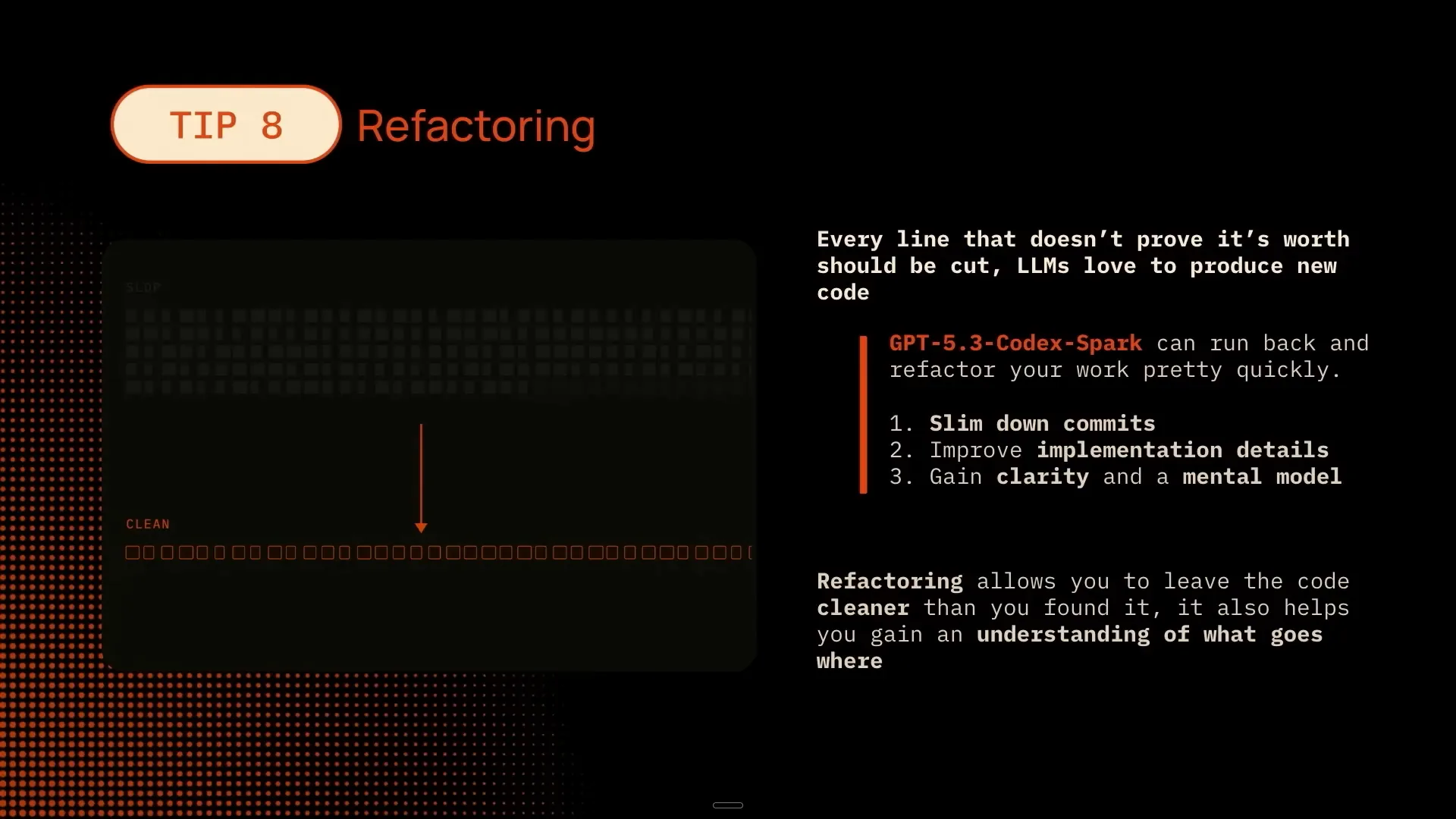 | The next step, refactoring, is very similar to verification. Just like verification, constantly refactoring and cleaning up your code can be done automatically at a cost of 1,200 tokens per second. Instead of waiting until the end, right before committing your code, you can integrate this into your automated workflow. After completing each task on your checklist, you can instruct the model to automatically delete unused imports, clean up unnecessary lines of code, and ensure that all functions are structured consistently. |
Slide 28 — 14:42 (watch)
 | The last category I want to discuss is context management. Many of you have likely heard these two words numerous times over the past few days in various talks. I want to emphasize its importance because, historically, it took about 10 minutes to fill up your context before encountering the term "compaction." |
Slide 29 — 15:04 (watch)
 | If you take 10 minutes and divide it by 20, you will achieve compaction in 30 seconds. Therefore, context management, particularly with fast inference, is more crucial than ever, and sloppy practices are no longer acceptable. |
Slide 30 — 15:14 (watch)
 | These are good practices regardless of the coding model or speed you are using. |
Slide 31 — 15:28 (watch)
 | A high-level framework suggests that you should always break large tasks into smaller, bounded goals. The graph on the right illustrates how the fullness of your context affects model behavior. It's important to avoid the 80 to 100% range, as this can lead to compaction, resulting in the loss of some information. |
Slide 32 — 15:48 (watch)
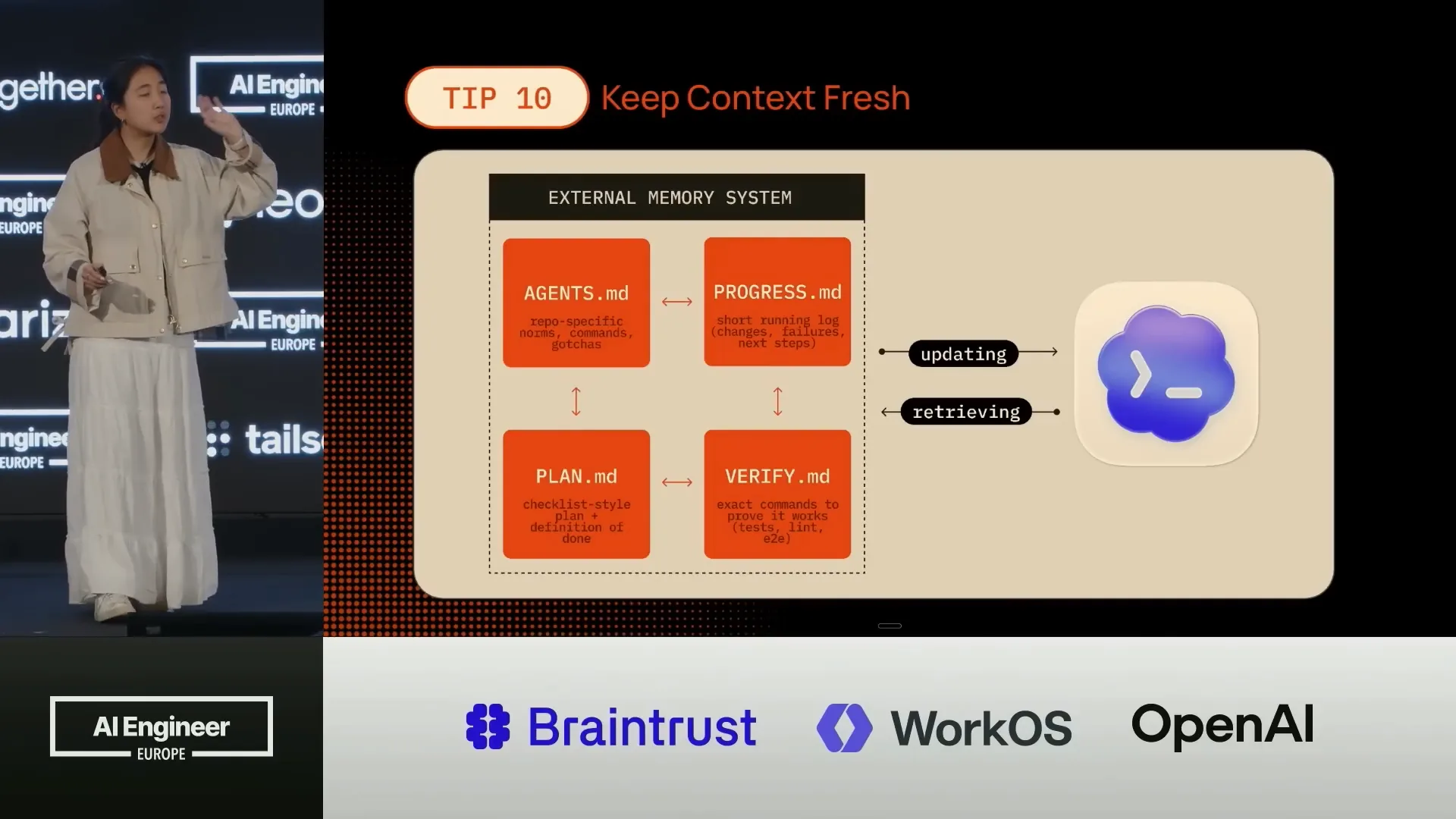 | A good way to externalize memory and establish small, bounded goals is to implement a persistent external memory system. One example of this is a four-file system that you can set up each time you initiate a new session. |
Slide 33 — 16:08 (watch)
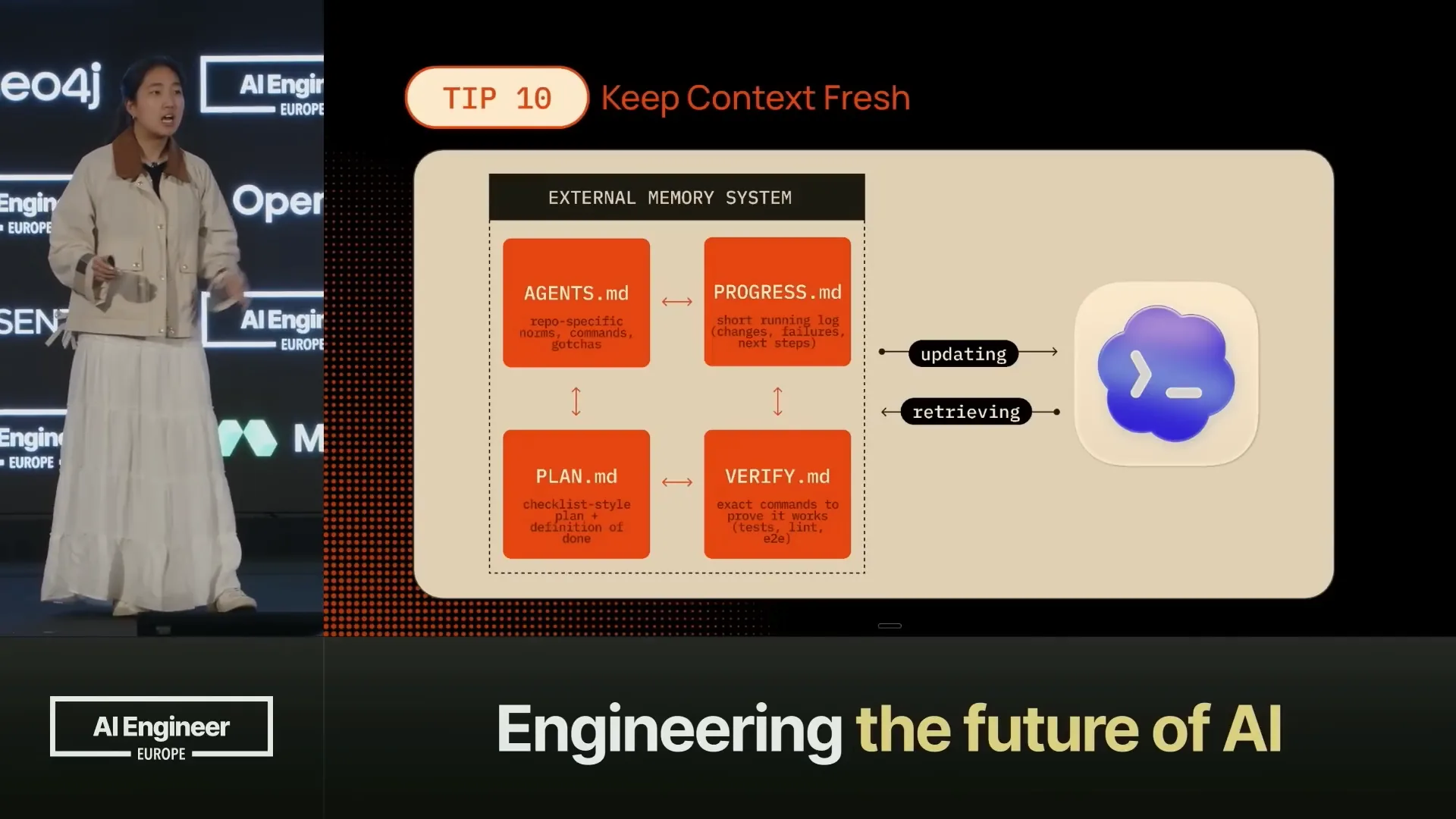 | We have AgentsMD, where we define all our agents and sub-agents. PlanMD is created at the beginning, generating the entire plan in step-by-step checklists that we will follow. ProgressMD tracks what needs to be done and what has already been completed. |
Slide 34 — 16:22 (watch)
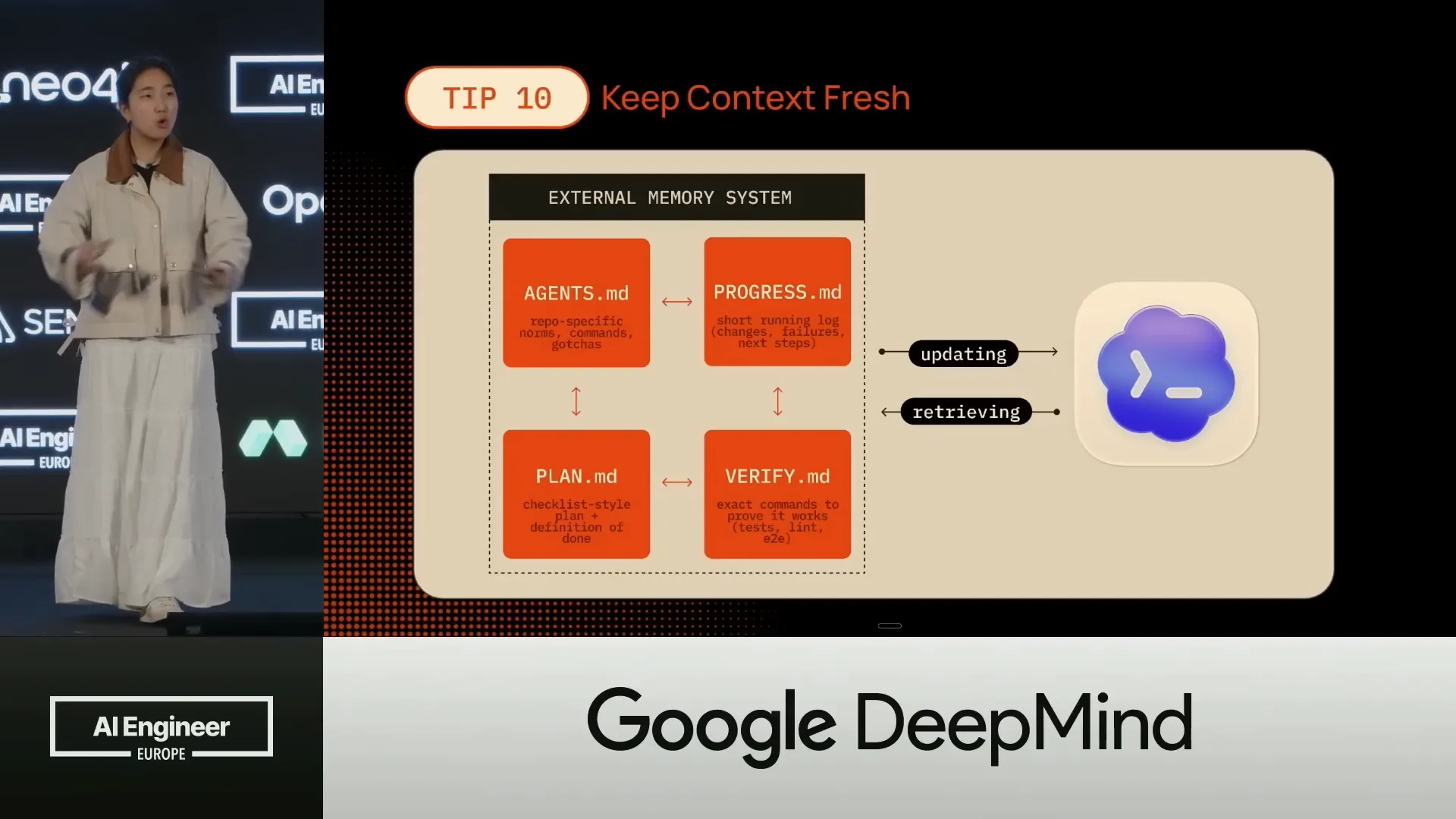 | Every time you spawn a new agent or session, it starts without any context. It references ProgressMD to see what has been done before and determines where to pick up. |
Slide 35 — 16:28 (watch)
 | The next task needs to be completed here. |
Slide 36 — 16:36 (watch)
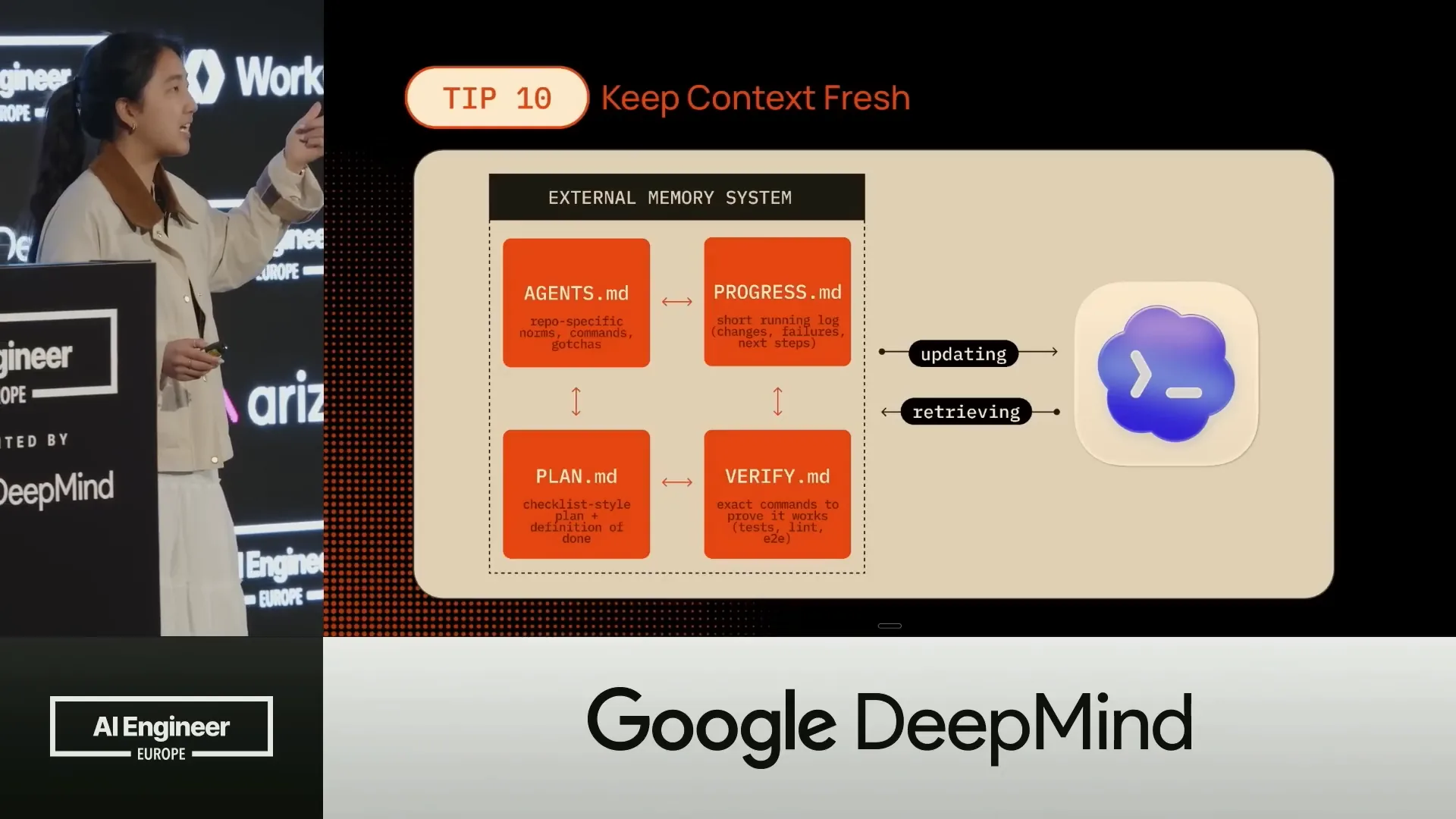
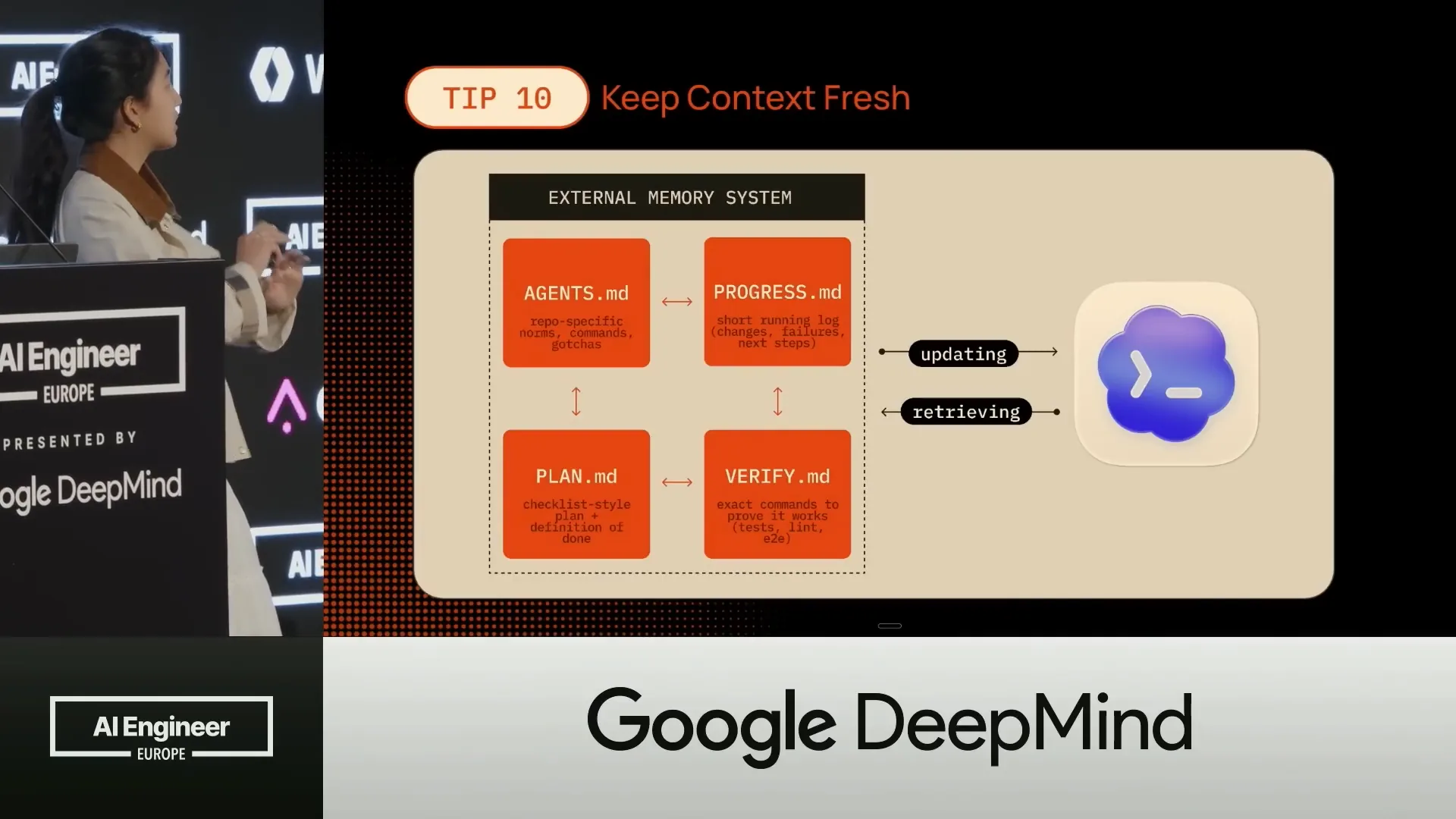 | The last tool is VerifyMD, which we use at every step to ensure that everything is in order, the code is clean, and we can proceed to the next task. |
Slide 37 — 16:44 (watch)
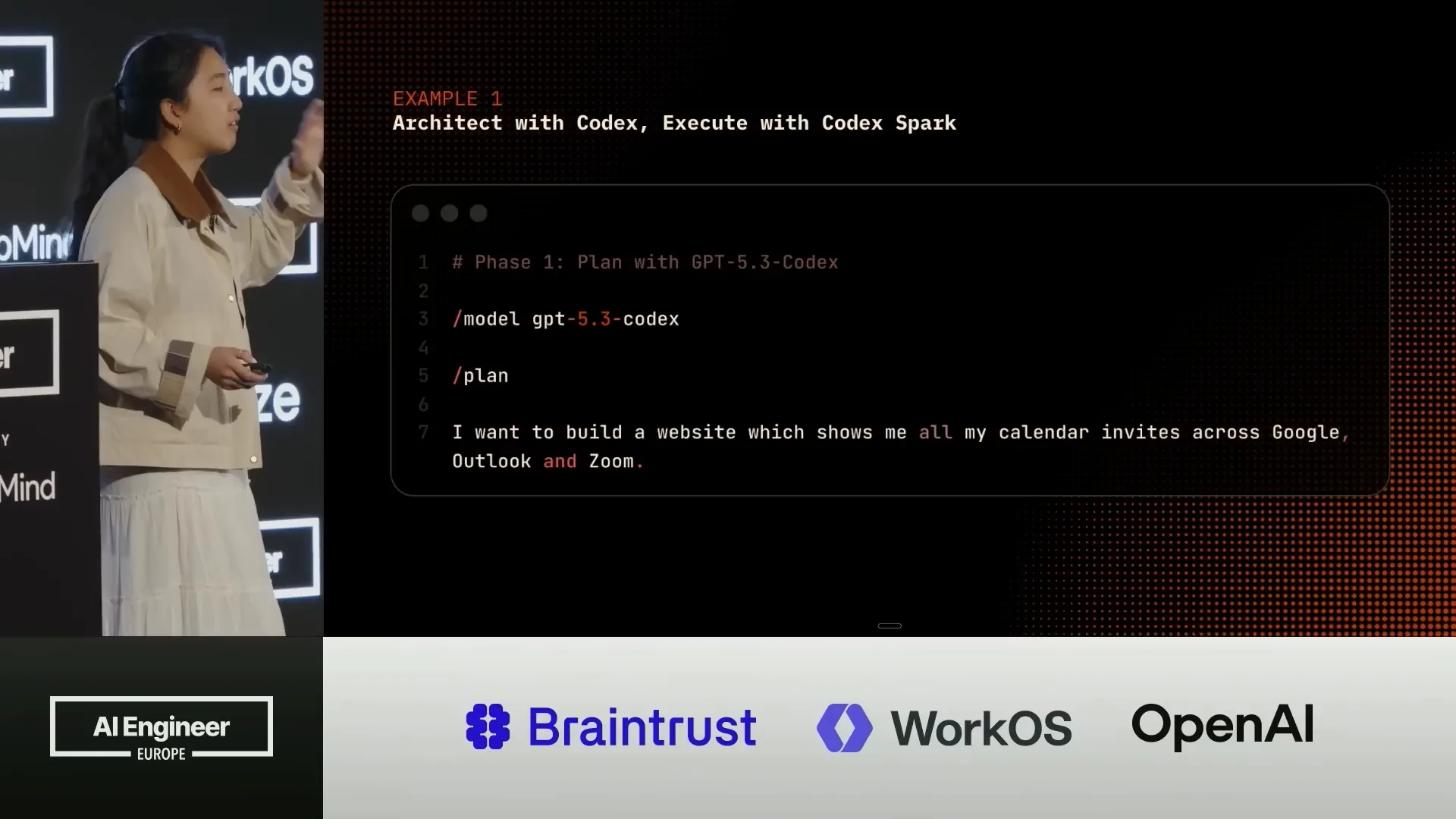 | An example of this process involves leveraging different models, such as using GPT-5.3 or GPT-5.4 codecs to create your plan. Then, the GPT-5.3 codec can execute the checklist one by one, significantly faster than before. |
Slide 38 — 16:56 (watch)
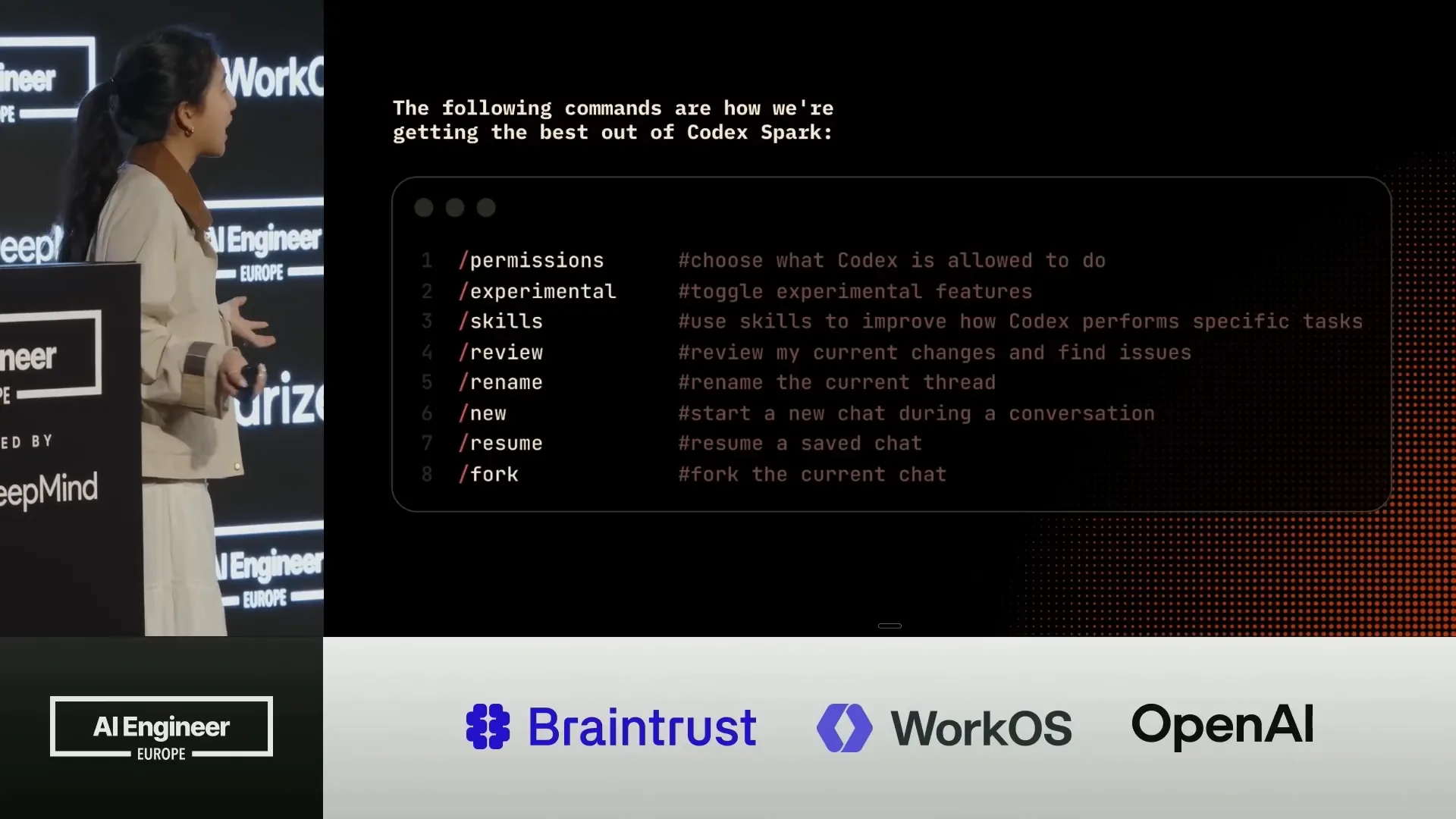 | As a final note, I want to share a few helpful commands to optimize your use of codecs, including managing permissions, utilizing experimental skills, and options for reviewing and renaming. |
Slide 39 — 17:10 (watch)
 | The most important point I want to emphasize is that it's not just about having faster coding models. The real impact is that the developer experience will significantly improve. |
Slide 40 — 17:24 (watch)
 | As the developer experience improves, we gain the ability to do much more and find numerous ways to avoid creating bad code without the frustration of staring at a screen for 30 minutes. |
Slide 41 — 17:34 (watch)
 | Thank you for welcoming me today. My name is Sarah Chang, and I'm visiting from San Francisco. It's an honor to be here in London. |
Slide 42 — 17:42 (watch)
 | If you have any questions or need credits, my handle is milksandmacha on all platforms. Thank you. |
Slide 43 — 17:54 (watch)
 | Thank you for the incredible experience. Be safe and take care. Goodbye, I'm B. Didier. |