71 slides extracted.
Slide 1 — 0:16 (watch)
 | Hello, and thank you for joining us today. I'm excited to kick things off on the breakout stage. My name is Ravi, and I lead the API knowledge team within the platform at Anthropic. |
Slide 2 — 0:56 (watch)
 | Since joining Anthropic last year, I have focused on creating the building blocks for agents to interact with various forms of knowledge, including the context window, skills, files, and content on the web. We recently released two features that I am particularly excited about: memory and dreaming. These features provide the foundation for agents to learn over time and improve from one task to the next. I will discuss the importance of memory, how we designed it, and conclude with dreaming, our new frontier memory feature. |
Slide 3 — 1:20 (watch)
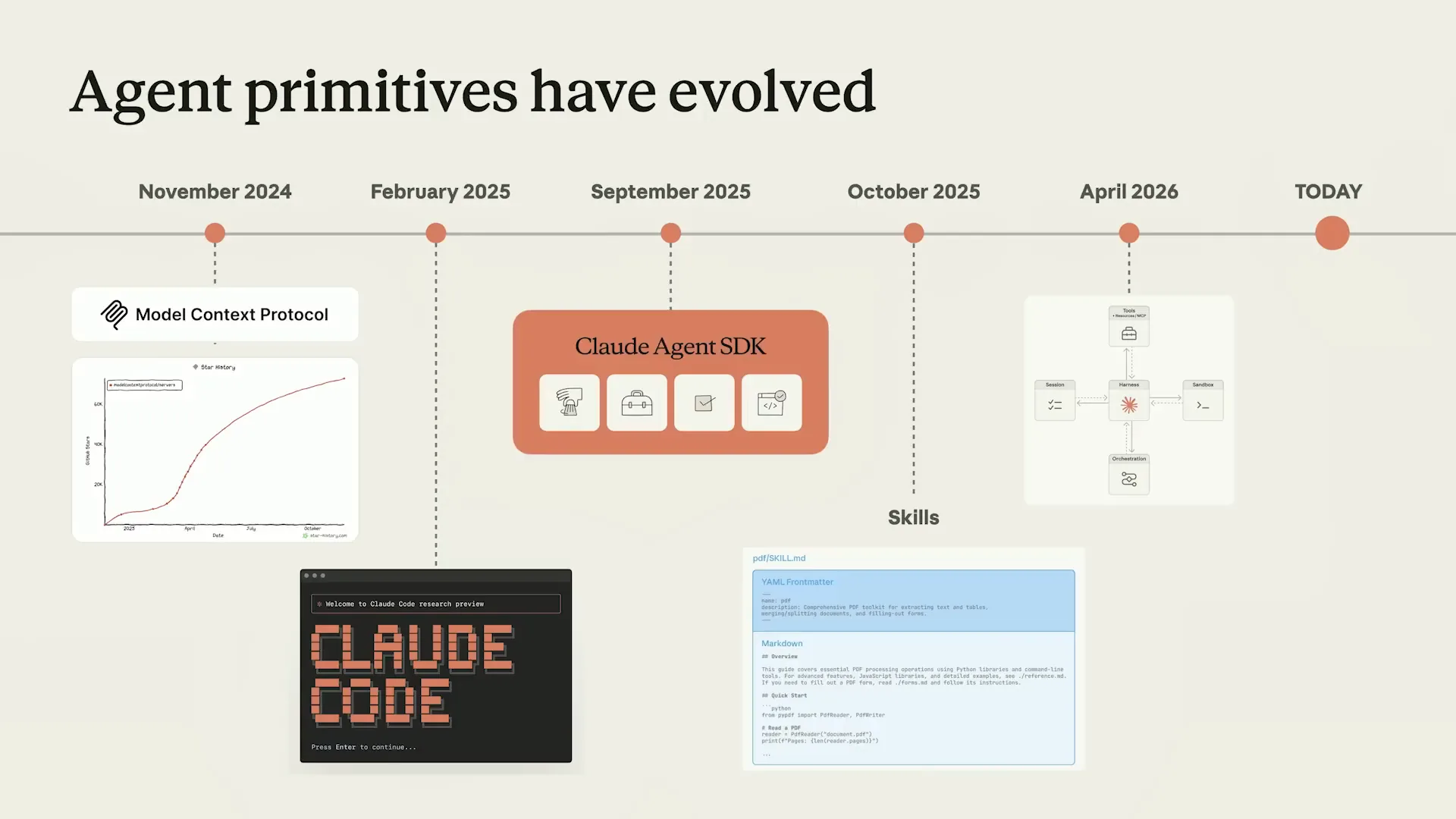
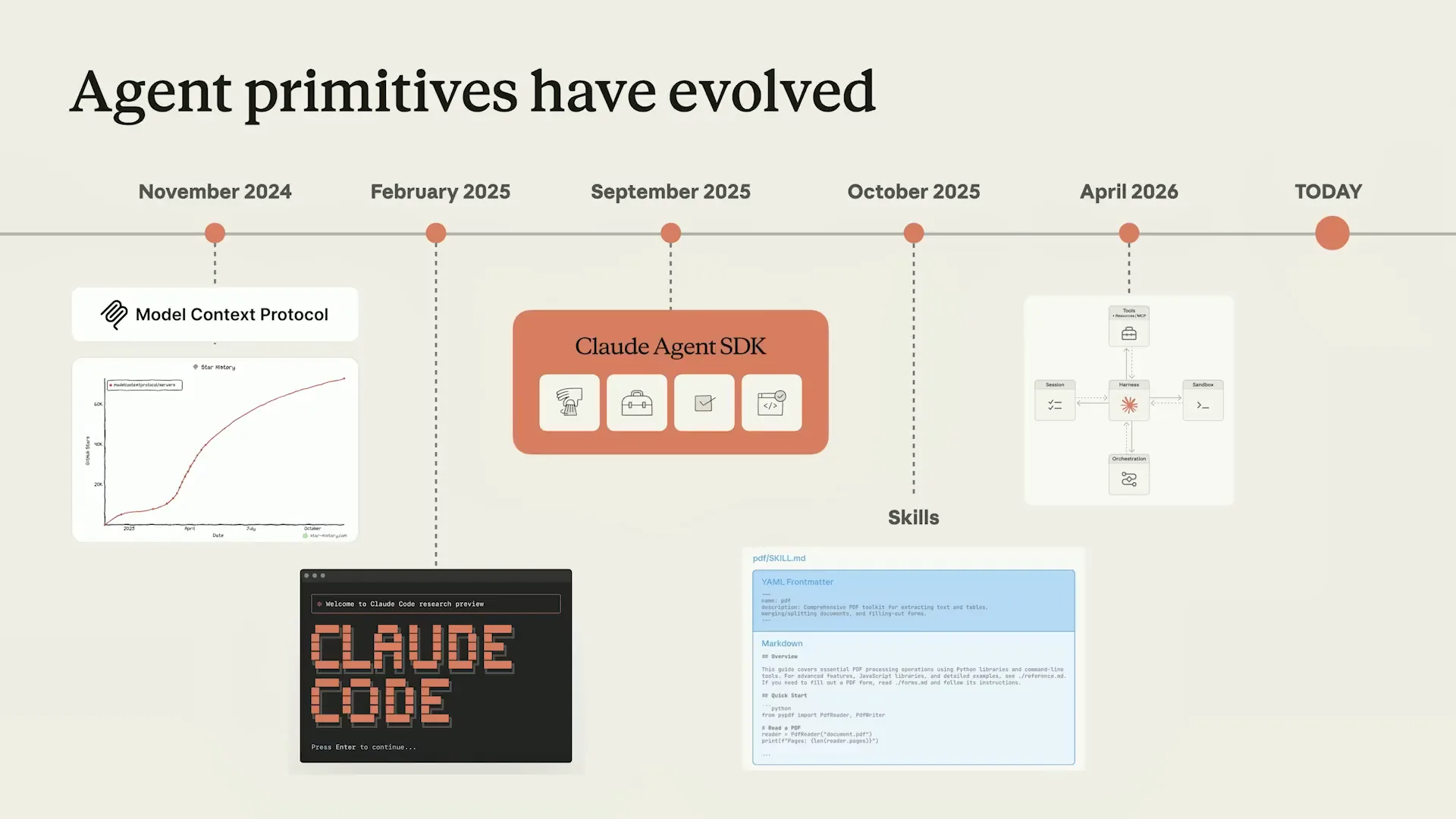 | Here is a quick timeline of milestones that brought us to this point. Models have been improving, and agents are now capable of completing increasingly complex tasks that take many hours. In 2024, we released the Model Context Protocol (MCP), which provided models with access to external tools and data in a principled manner. In 2025, we introduced Cloud Code and the agent SDK, which lowered the barrier for using and building agents. |
Slide 4 — 2:00 (watch)
 | It's incredible to think that was in 2025; it honestly feels like a lifetime ago. Later that year, we launched skills, providing models with a generic abstraction to unlock and effectively integrate new capabilities for completing specific tasks. |
Slide 5 — 2:20 (watch)
 | Last month, we released Cloud Managed Agents, a platform for reliably running agents that handles the complex aspects of operation. The key point is that agents can perform more tasks and operate over increasingly longer time horizons. In 2025, Meter released a study indicating that the duration of tasks agents can complete is doubling every seven months, and we are observing this trend. |
Slide 6 — 2:52 (watch)
 | Managing context over long-horizon tasks is still a work in progress, and this is where memory plays a crucial role. Memory enables agents to learn and carry forward insights from their previous tasks. |
Slide 7 — 3:16 (watch)
 | In the simplest terms, consider a series of tasks: task 1, task 2, task 3, and so forth. |
Slide 8 — 3:44 (watch)
 | The goal is to improve performance from one task to the next. In the base case, without memory, performance on each task may be similar because every agent starts from the same slate. In the optimal case, performance improves sequentially from task 1 to task 2, from task 2 to task 3, and so on. This reflects the goal of learning not only from task to task but also from environment to environment and agent to agent. With memory, agents can learn from common strategies and previous mistakes, as well as from the tools, codebases, and files they have access to. Ultimately, they can transfer these learnings to and from other agents. |
Slide 9 — 3:56 (watch)
 | Imagine swarms of agents contributing to and maintaining a shared understanding of their organization. This is the vision we aspire to achieve. |
Slide 10 — 4:14 (watch)
 | We recently launched Memory for Cloud Managed Agents, marking a significant step toward our vision. This system provides developers with a frontier memory architecture designed to maximize intelligence out of the box. It supports multi-agent systems while ensuring enterprise control and observability. |
Slide 11 — 4:44 (watch)
 | We developed memory in collaboration with several teams utilizing managed agents, and the results are impressive. Rakuten experienced a 97% reduction in first-pass errors in their deployed agents. Wise Docs improved their document verification pipeline by reducing common issues through cross-session memory. The consistent feedback we receive is that our memory primitive enables teams to concentrate on product development rather than infrastructure. |
Slide 12 — 5:28 (watch)
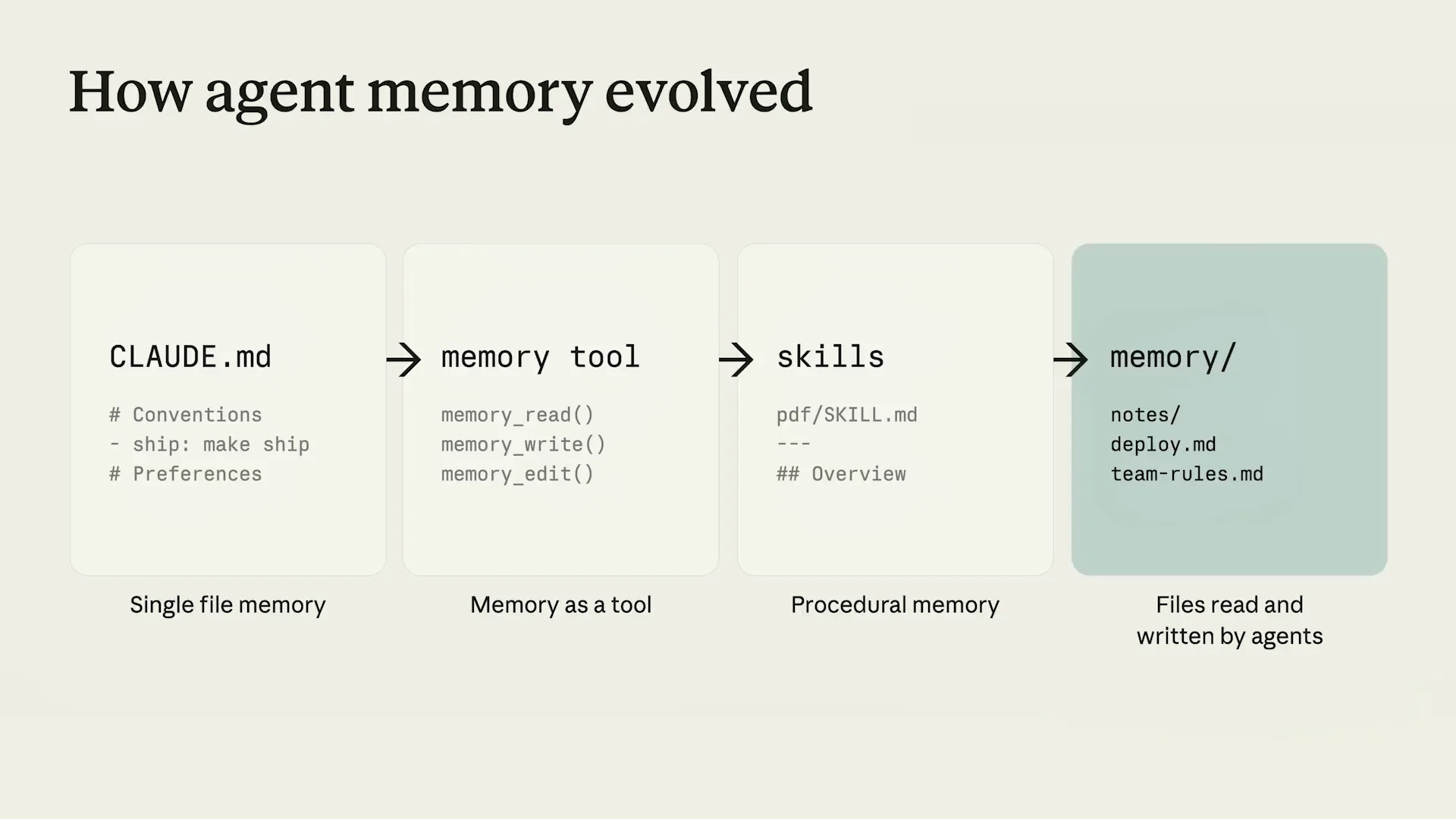 | We reap the benefits of increased intelligence that comes with improved memory. You may wonder if memory is truly a new concept, and that’s a valid question. While memory itself is not entirely new, our approach to it with agents has significantly evolved. |
Slide 13 — 5:44 (watch)
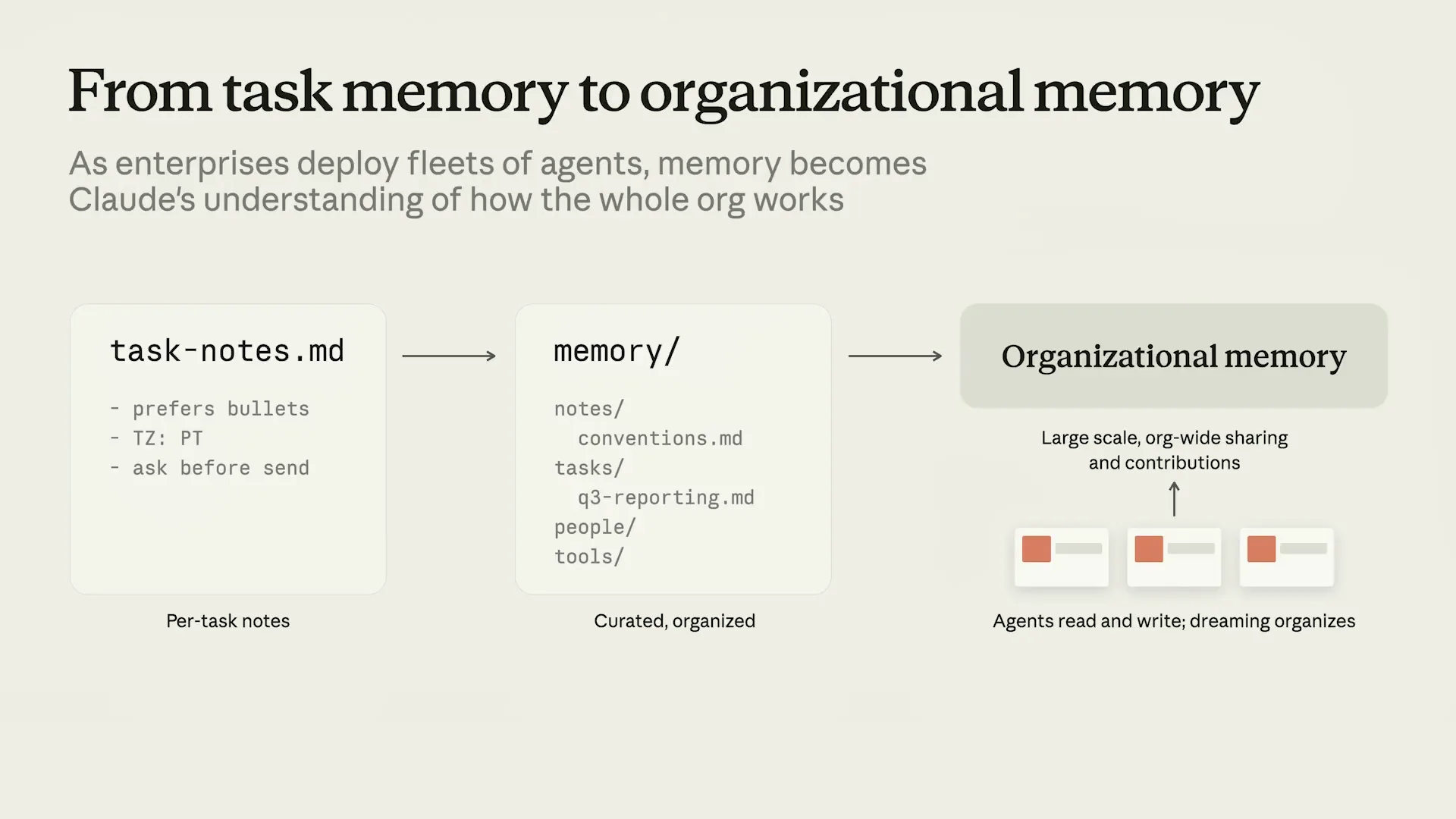
 | Previously, we built memory by focusing on capabilities within the harness. You may be familiar with Cloud.MD for Cloud Code or dedicated memory tools in the SDKs. |
Slide 14 — 6:10 (watch)
 | One pattern we're observing is that as models improve, we want to allow them more freedom, similar to our approach with skills. Skills were a basic yet highly flexible format that opened up endless possibilities, and the model understood how to interact with it. Similarly, with memory, we are adopting that same approach with files. |
Slide 15 — 6:26 (watch)
 | Let's discuss the capabilities we designed memory around. Currently, we know that models and Cloud excel at navigating virtual environments and file systems. |
Slide 16 — 6:54 (watch)
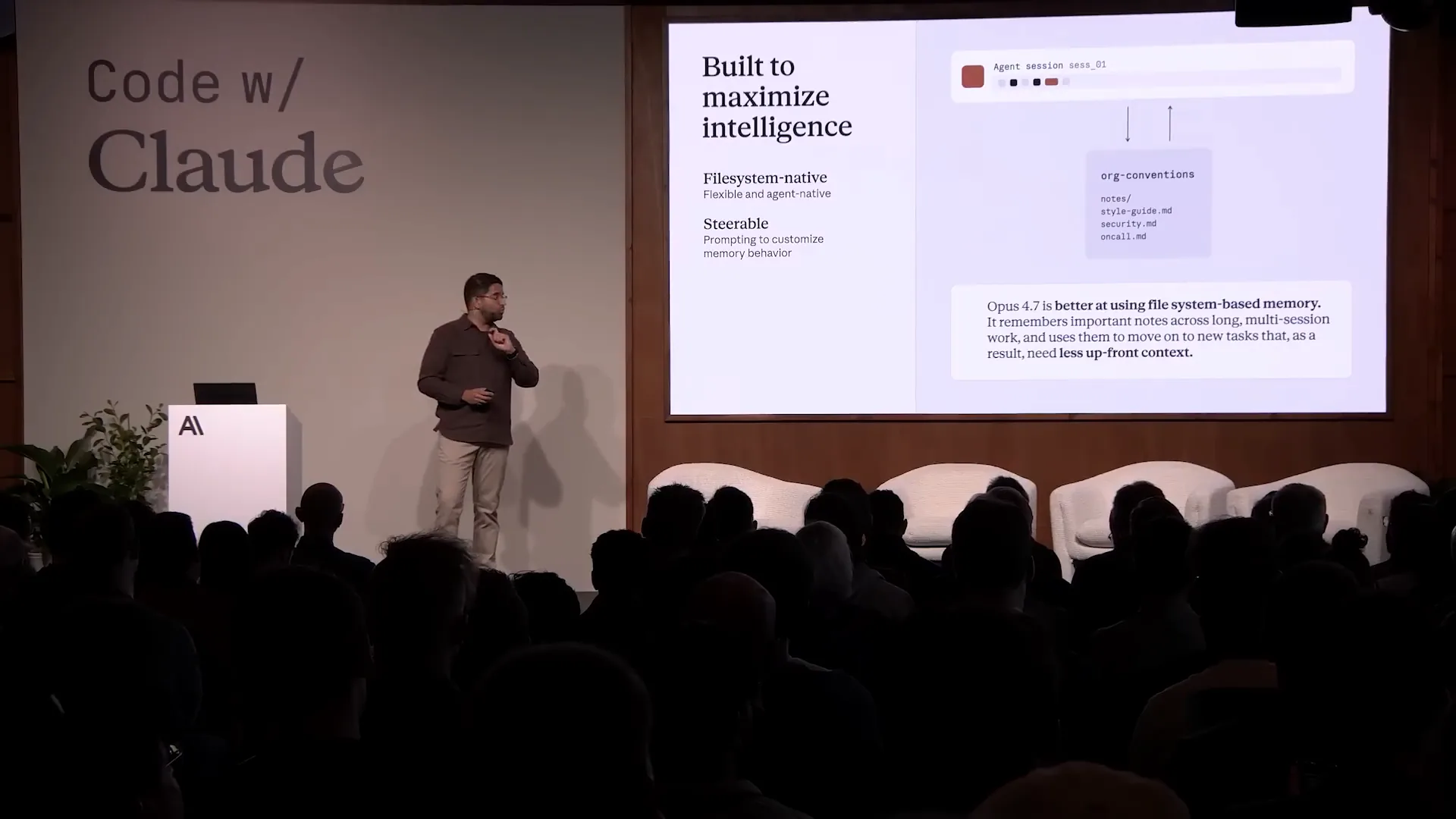 | Cloud is also very capable of using familiar tools like Bash and Grep to read, update, and organize files. Opus 4.7, which we launched last month, is a state-of-the-art model for file system-based memory. It is increasingly adept at discerning which context is most important to save for its future self, how that context should be structured, and how it should be represented. We have modeled memory as a file system for Cloud. The key principle is to get out of Cloud's way and allow it to leverage its existing strong capabilities. As we like to say, let it cook. This is the dream. |
Slide 17 — 7:32 (watch)
 | We have discussed Cloud's memory capabilities in the context of a single agent. However, we want these capabilities to function across multiple agents operating simultaneously in the same environment or across different environments. This introduces new requirements, such as enabling multiple sessions to share the same memory store concurrently. |
Slide 18 — 7:54 (watch)
 | They may require different scopes, so we provide both read-only and read-write scopes. |
Slide 19 — 8:36 (watch)
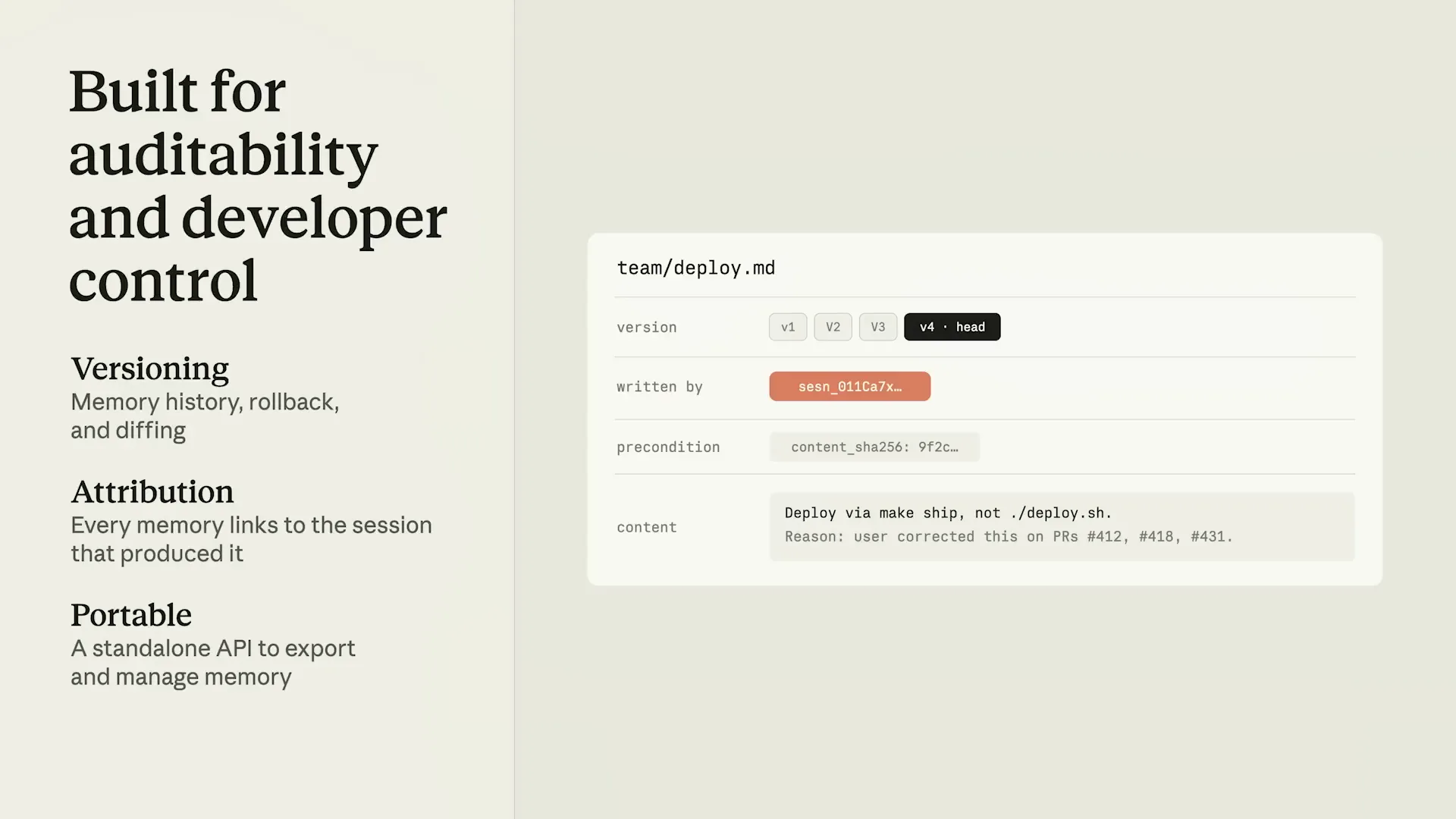 | For example, you could have organization-wide memory that is read-only, updated frequently, and accessible by all agents. The same set of agents can also access more granular memory stores that they can read and write freely. This creates a hierarchy and allows the memory system to scale effectively. To prevent write conflicts and ensure that one agent does not overwrite another's changes, we employed a concurrency control model. Additionally, memory must support real production agents, which requires enterprise-grade controls. Version control creates an audit trail as agents make changes, enabling developers to track how memory evolves over time and even diff between versions. There is also attribution to identify which agent wrote each part of the memory. Importantly, memory has a standalone API, allowing developers to manage it from anywhere. Teams are building their systems in various environments, so they can use memory through these APIs, which provide standard operations as well as more enterprise-focused features like exports and redactions. We have covered three key components of a memory architecture: first, the storage layer, which manages data and tracks changes; second, the structure of memory, optimized for Claude to maximize its utility; and third, Claude-driven processing for updating the memory. Now, let's focus on that processing aspect. |
Slide 20 — 10:20 (watch)
 | Agents writing memory during their tasks is crucial to the processing layer. This can be likened to taking notes while working. However, as we scaled this approach to more complex multi-agent use cases, we encountered limitations across different sessions and identified common patterns. For instance, agents tended to make similar mistakes and learned from them independently. Additionally, they exhibited patterns of inefficiency. |
Slide 21 — 10:40 (watch)
 | The general theme was that memory was being updated in a locally optimal way, but it was not globally optimal. In some cases, there was duplication or fragmentation. |
Slide 22 — 10:52 (watch)
 | We began to think deeply about this problem, and over the last couple of months, we developed a feedback loop in the processing layer to address some of these issues. |
Slide 23 — 11:06 (watch)
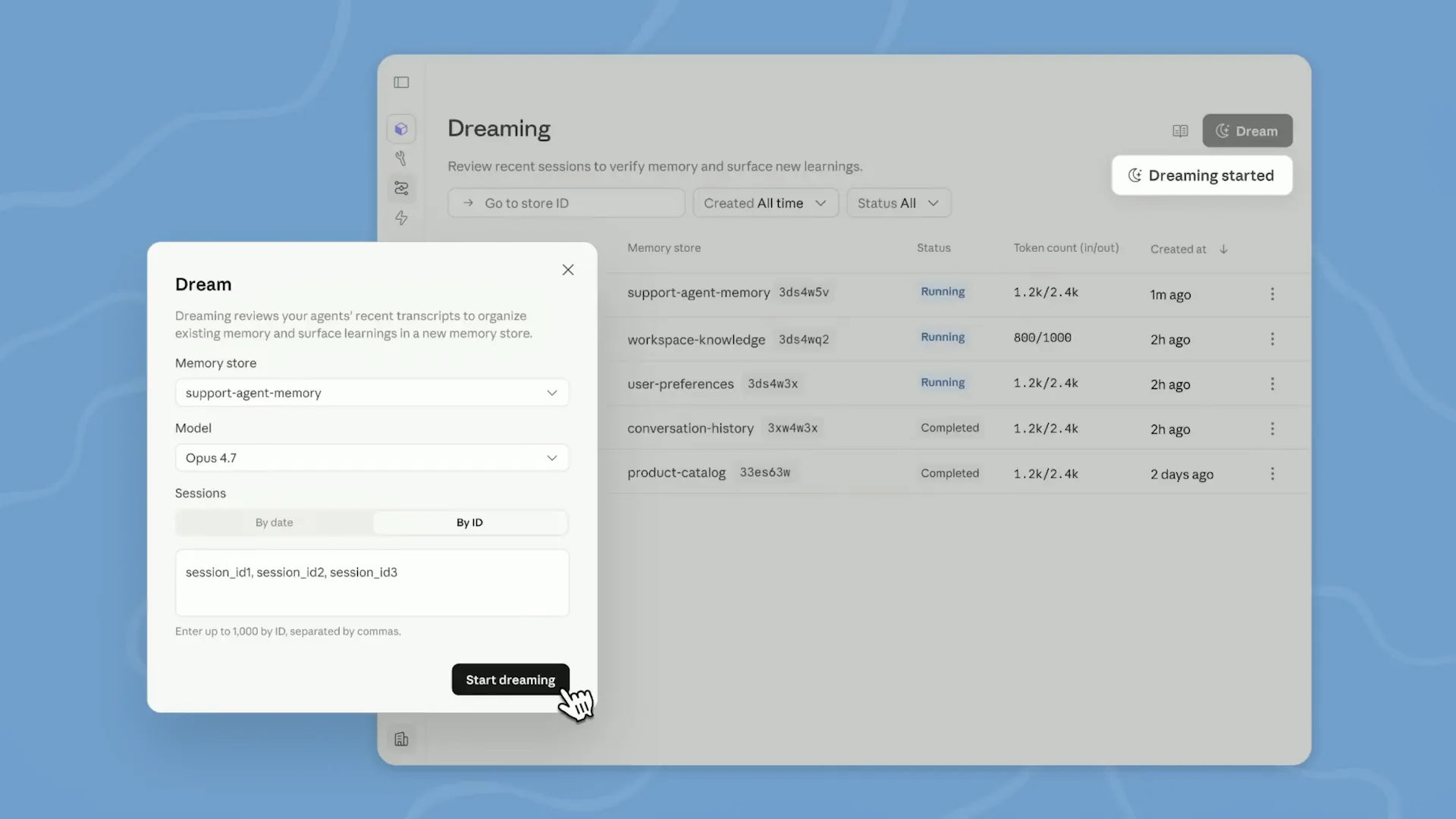 | This is the dream we envisioned, and we refer to this process as dreaming. Dreaming is currently available in Research Preview and can be utilized with managed agents. |
Slide 24 — 11:16 (watch)
 | Dreaming is a process that identifies patterns and mistakes across agents and sessions, automatically organizing and curating their memory. |
Slide 25 — 11:30 (watch)
 | Developers like Harvey experienced a sixfold increase in completion rates for their legal benchmark with dreaming. We are actively observing other applications of dreaming and are excited to see how users are benefiting from it. |
Slide 26 — 11:50 (watch)
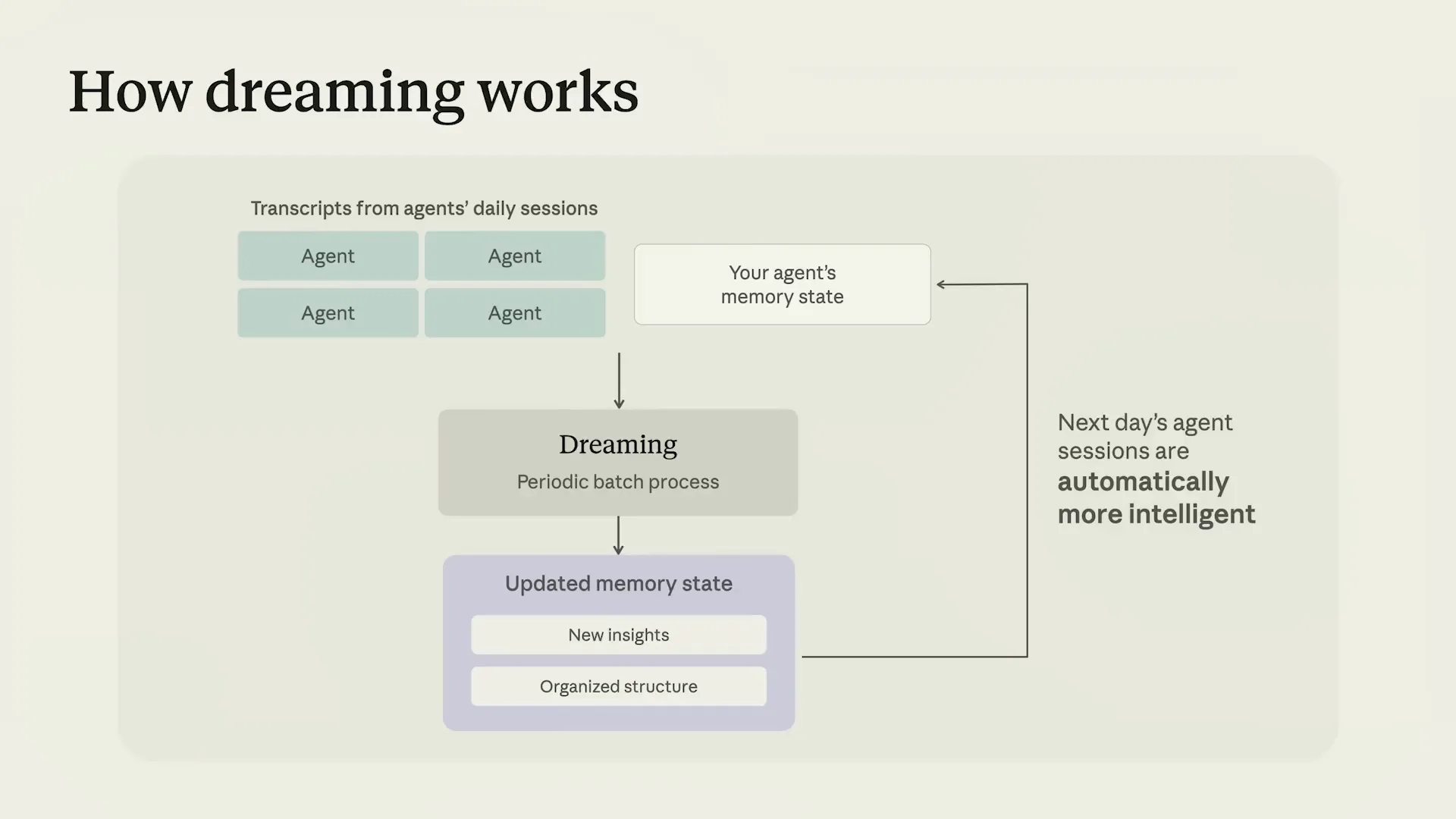 | Dreaming operates as a batch process that runs independently from sessions, making it completely decoupled. You can think of it as a feedback loop where agents write memories, and dreaming refines those memories in a continuous cycle. Dreaming can be initiated on an ad hoc basis, nightly, hourly, or triggered by specific events, such as the end of a session. |
Slide 27 — 12:08 (watch)
 | It's all controlled via API, providing great flexibility. Each dreaming run analyzes session transcripts. |
Slide 28 — 12:18 (watch)
 | It inspects the existing state of memory and proposes optimizations in scenarios where sessions were inefficient, made mistakes, or required improved guidance. |
Slide 29 — 12:34 (watch)
 | The output is a verified and better-organized snapshot of memories that agents can choose to adopt. Dreaming enables continuous self-learning and closes the loop on memory. |
Slide 30 — 12:58 (watch)
 | The out-of-band component of dreaming is critical. Creating a process that is decoupled from the underlying agent loop offers several benefits. This architecture is particularly useful for multi-agent systems, as it enables the identification of patterns in cross-session and cross-agent transcripts that a single agent might struggle to discern. Additionally, having a dedicated dreaming harness provides further advantages. |
Slide 31 — 13:26 (watch)
 | Dreaming allows for clearer objectives. Since it is an independent process, agents do not need to trade off between improving memory quality and completing their task objectives. This creates a clean separation. Additionally, it does not add any latency to the agent. |
Slide 32 — 13:52 (watch)
 | It is completely removed from the hot path. Zooming out, we now have a robust memory layer that can be shared across agents and environments, rather than being limited to specific tasks or usages. Additionally, we have dreaming, a process that globally optimizes and reconciles memory across agents. |
Slide 33 — 14:08 (watch)
 | The result is a capable memory system for organizational memory that scales both in size and quality. |
Slide 34 — 14:24 (watch)
 | I believe that sharing memory, which continuously improves across agents, elevates the baseline performance for each agent. |
Slide 35 — 14:36 (watch)
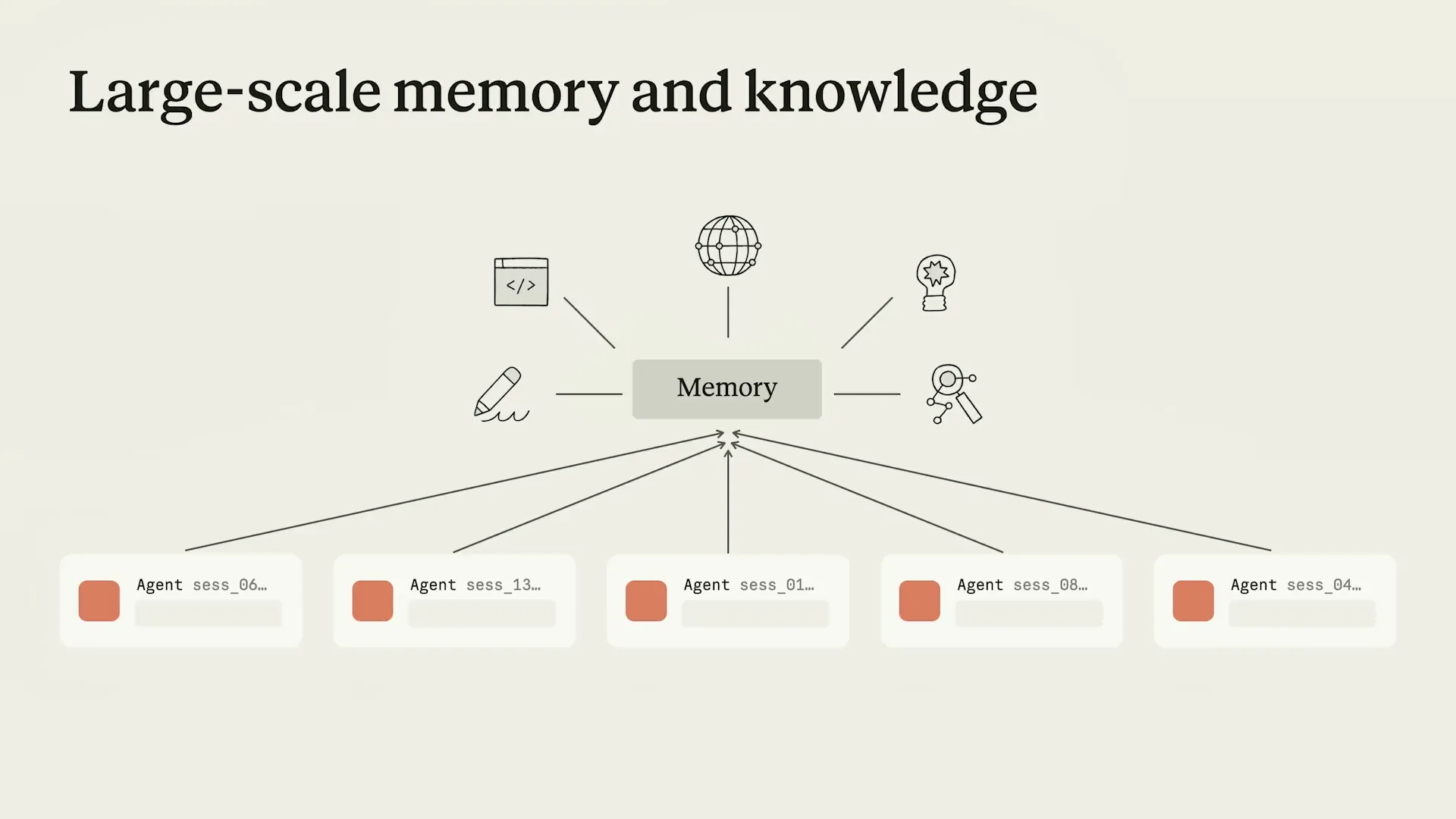 | Dreaming enhances this capability even further. By significantly expanding this ability and integrating it, memory transforms into a substantial source of knowledge that Claude can utilize to comprehend the organization and the world in which it operates. |
Slide 36 — 14:58 (watch)
 | One way to think about dreaming is as a form of test-time computation, where allowing models to spend some tokens to explore a problem generally leads to better outcomes. |
Slide 37 — 15:06 (watch)
 | With dreaming, agents similarly invest effort upfront to curate and produce higher quality memory, which benefits all downstream agent performance. |
Slide 38 — 15:20 (watch)
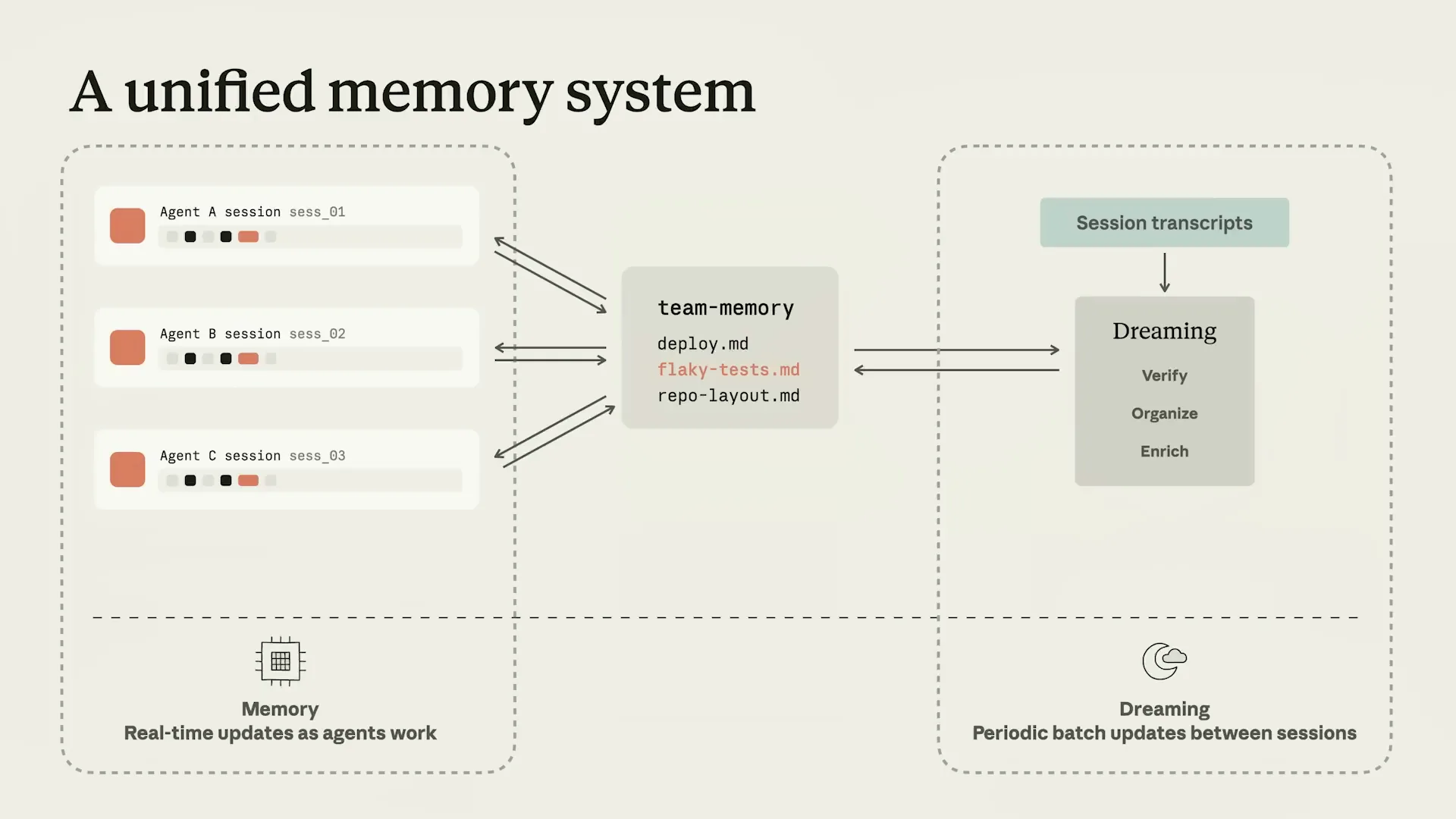 | We believe that dreaming and memory form the foundation of an advanced memory system. |
Slide 39 — 15:30 (watch)
 | Memory on the left aids agents in learning and retaining information across tasks, while dreaming on the right verifies, organizes, and enriches that memory. |
Slide 40 — 15:34 (watch)
 | I view dreaming as the bridge between our current understanding of memory and the organization of scale, memory, and knowledge. |
Slide 41 — 16:02 (watch)
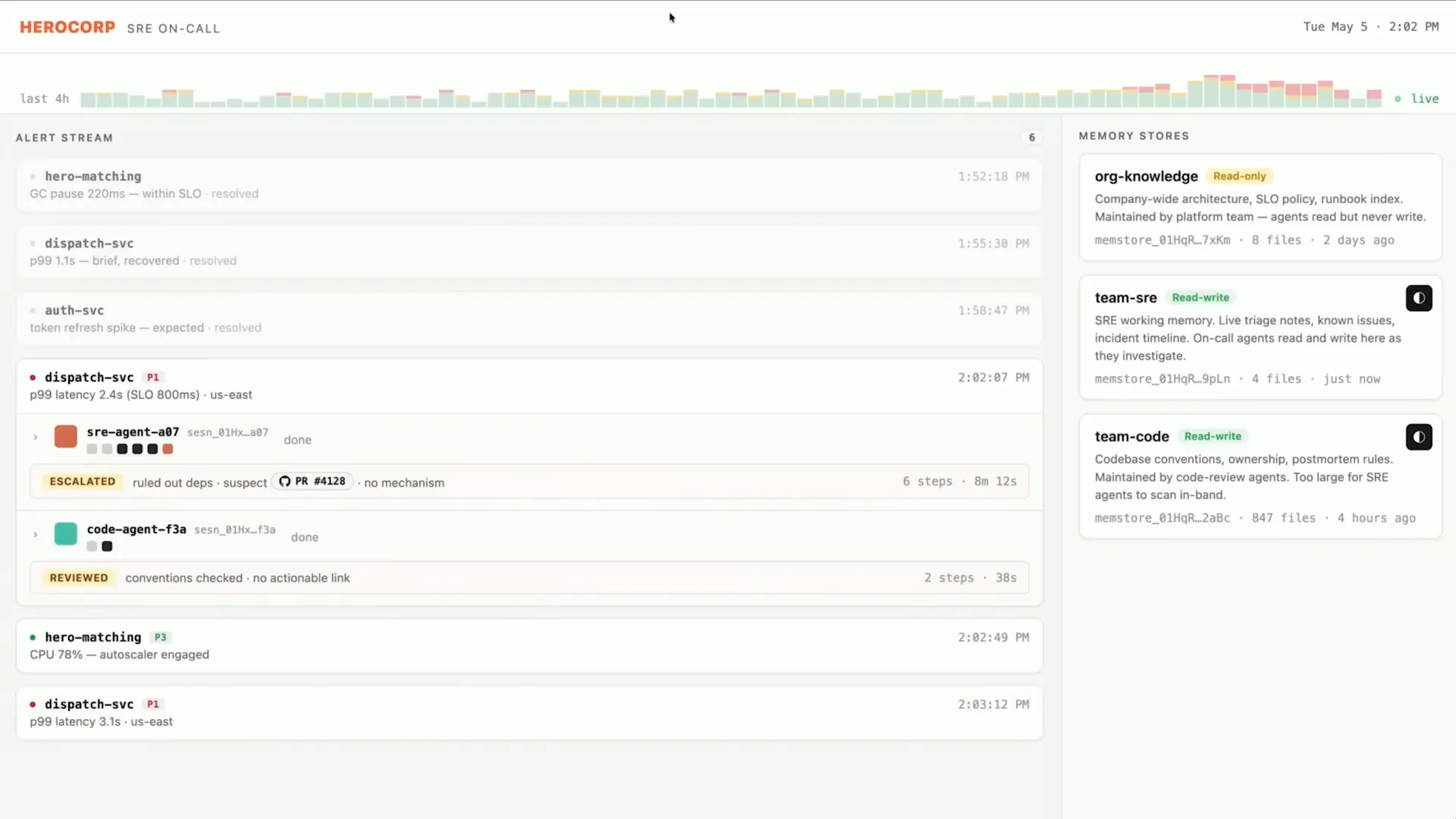 | Now, I will demonstrate an agent platform for Site Reliability Engineers (SREs) that utilizes both dreaming and memory in practice. This system monitors incoming alerts and pages. |
Slide 42 — 16:12 (watch)
 | For some alerts, it spins up agents that determine how to triage and resolve the issues as they arise. |
Slide 43 — 16:18 (watch)
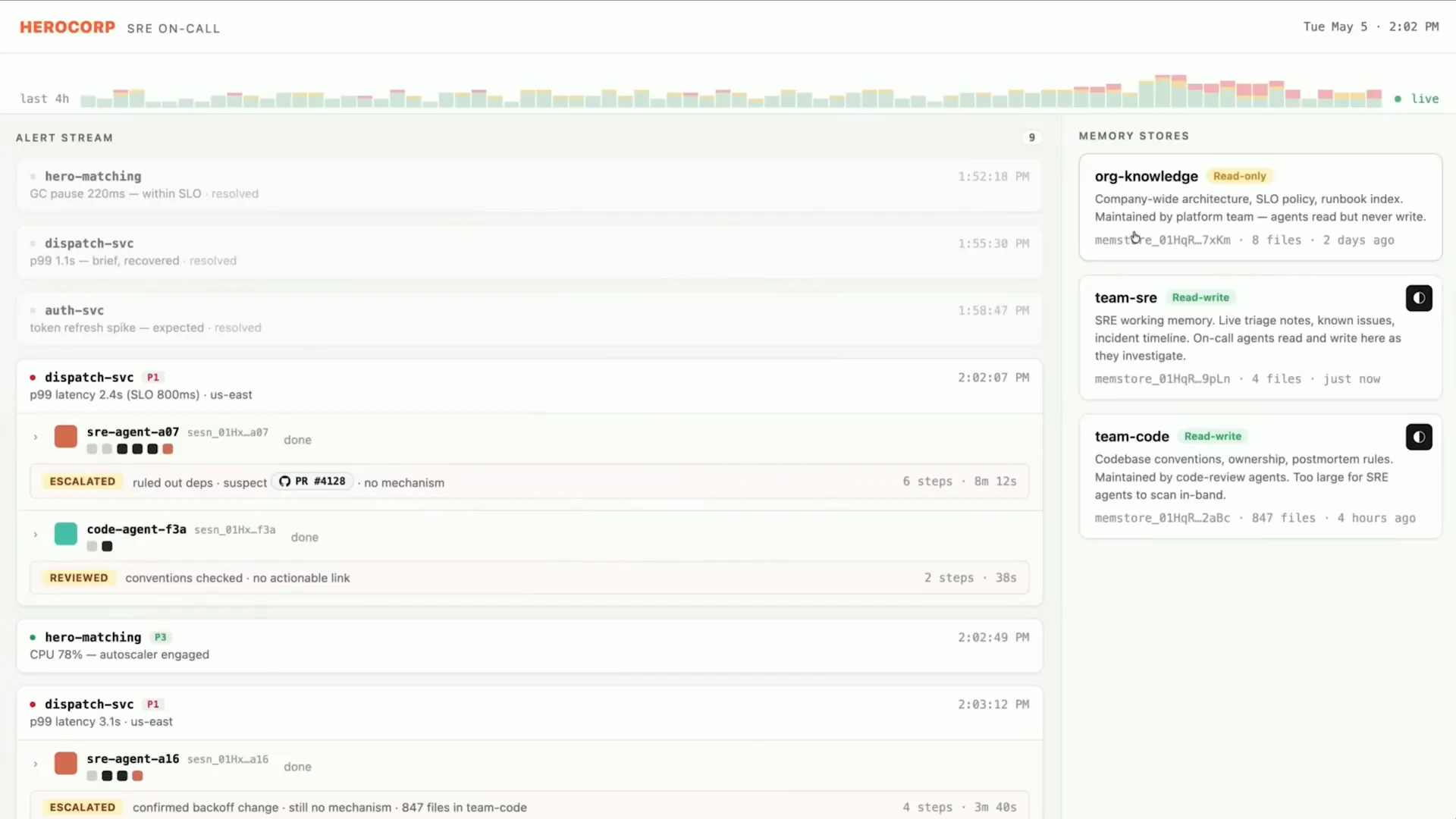 | It has access to a couple of memory stores. |
Slide 44 — 16:26 (watch)
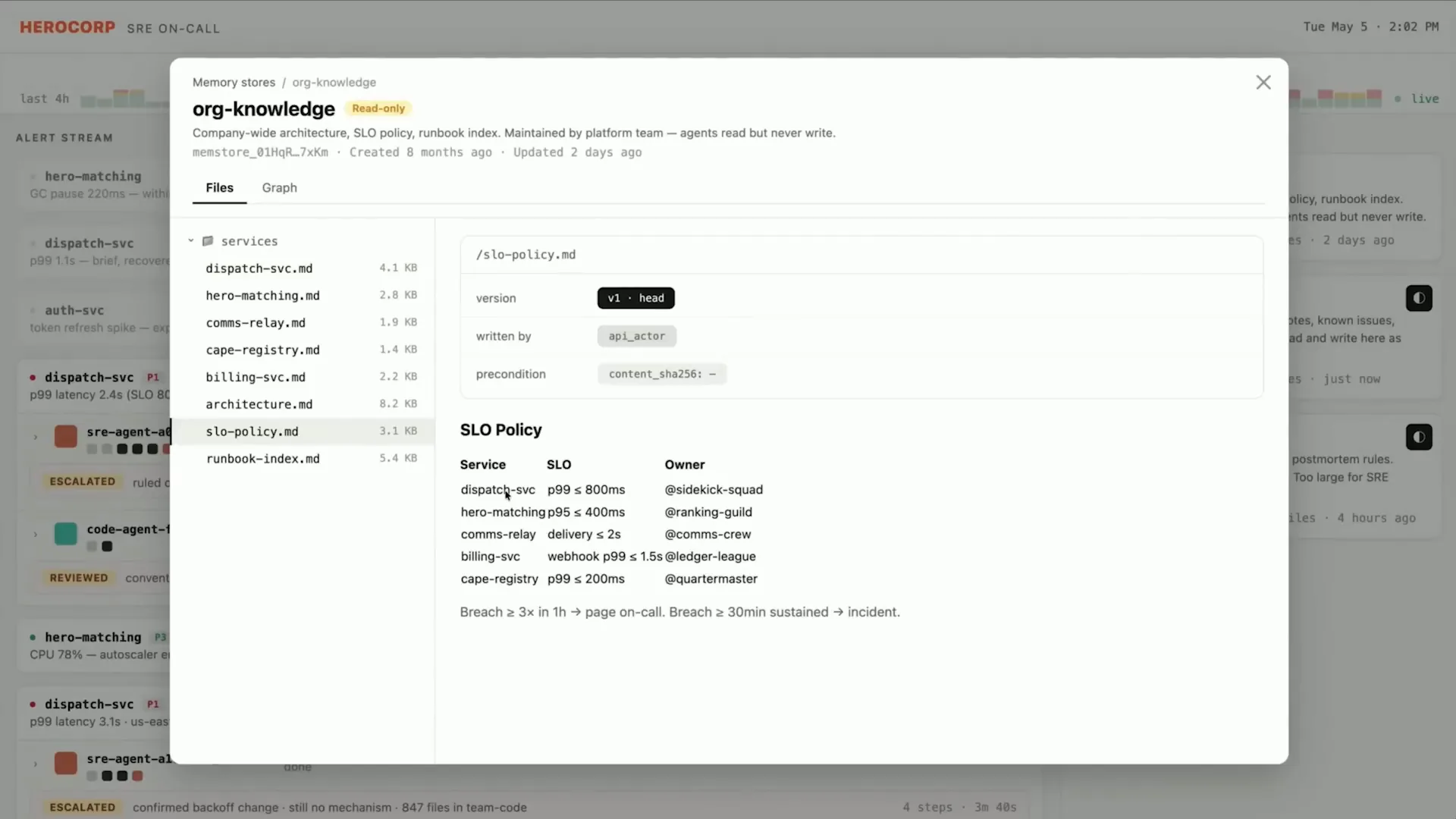 | One memory store is a read-only organization-wide knowledge memory store. This store contains information such as the SLO policy, runbooks, and on-call mappings. These elements do not change frequently but are essential for every agent. |
Slide 45 — 16:44 (watch)
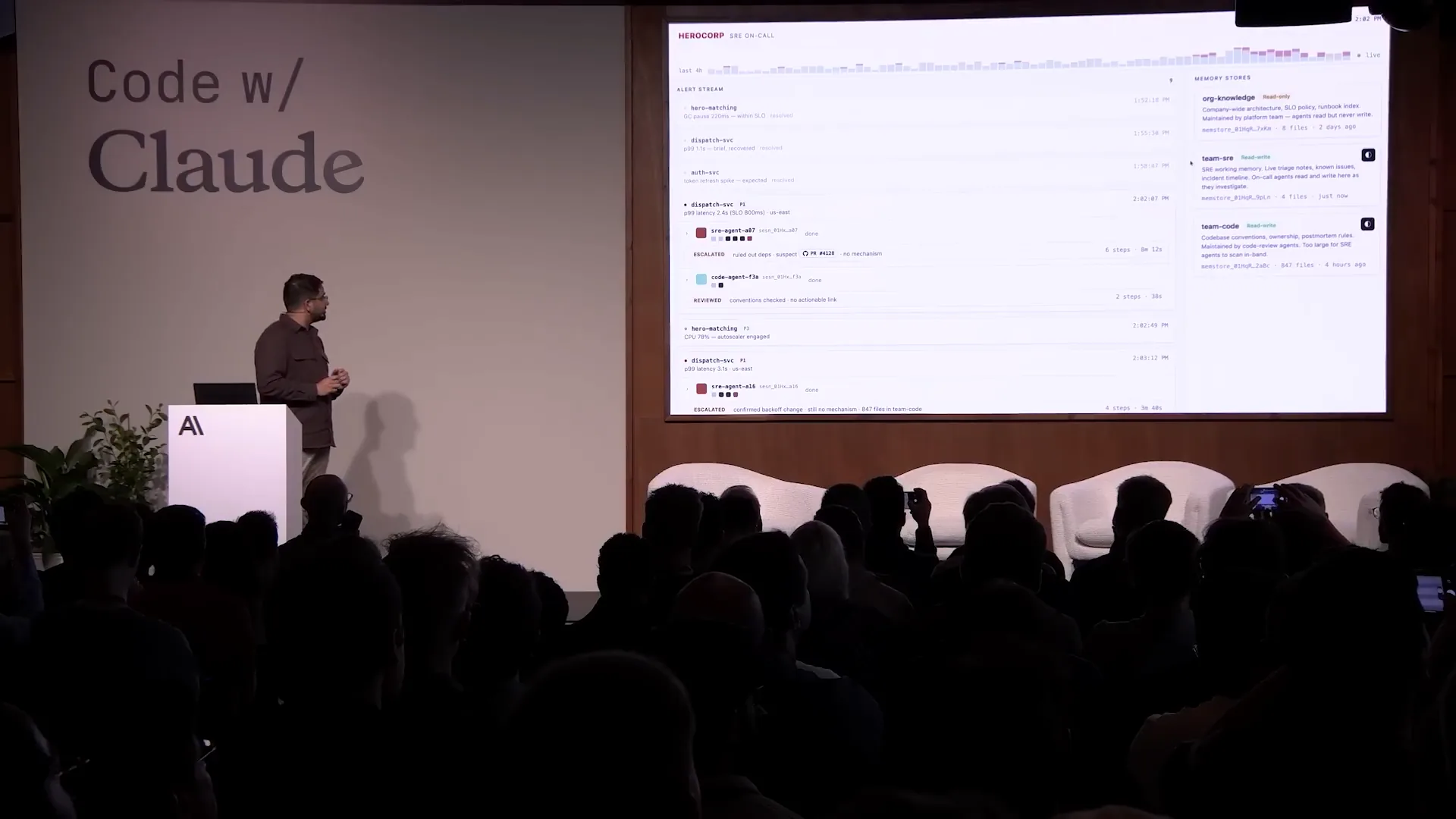 | It also has access to read-write memory stores specific to the task at hand. For example, an agent investigated and identified the root cause of an alert. |
Slide 46 — 17:00 (watch)
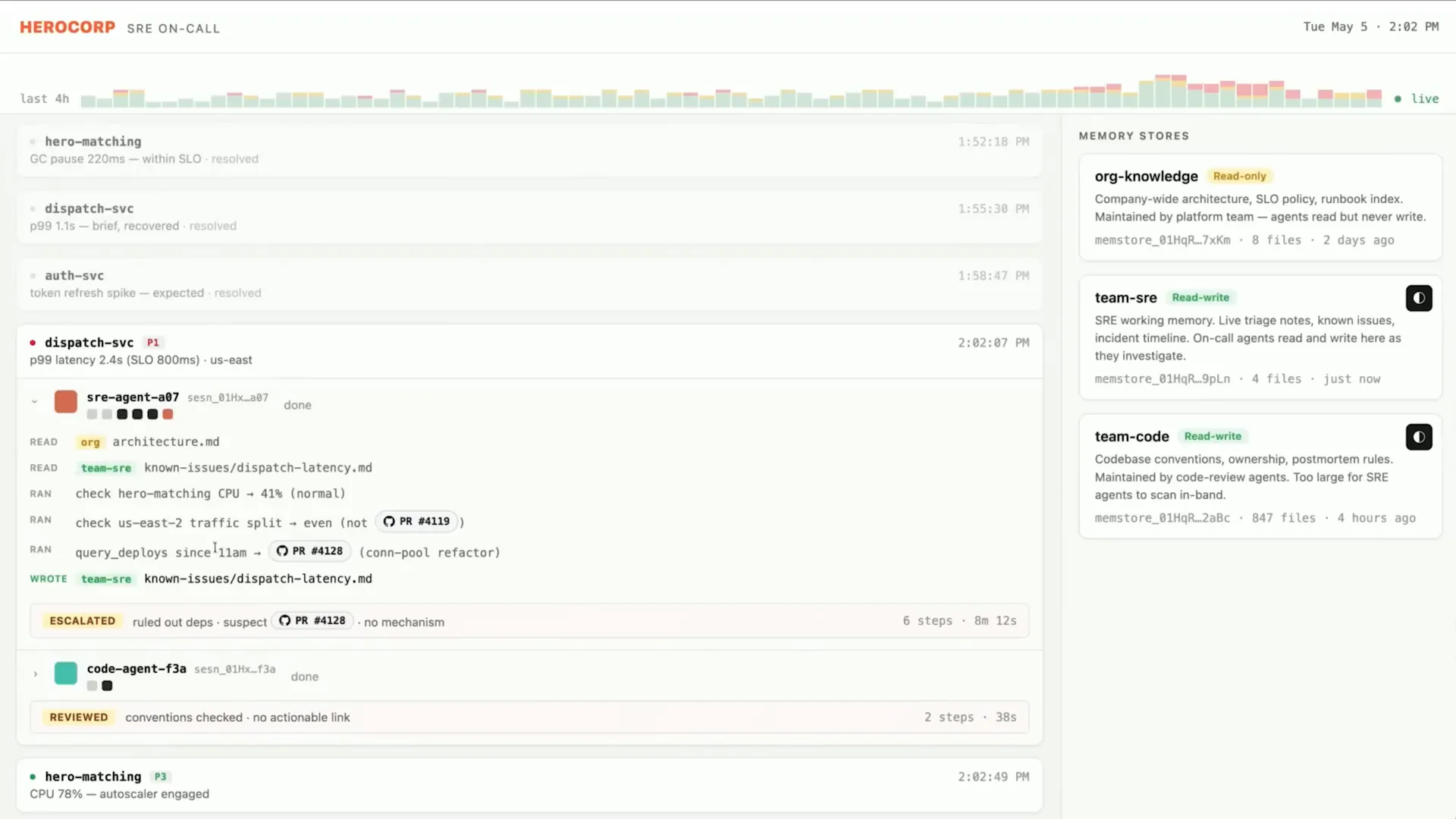 | It implemented a fix and recorded in memory that a fix was in flight and incoming. |
Slide 47 — 17:08 (watch)
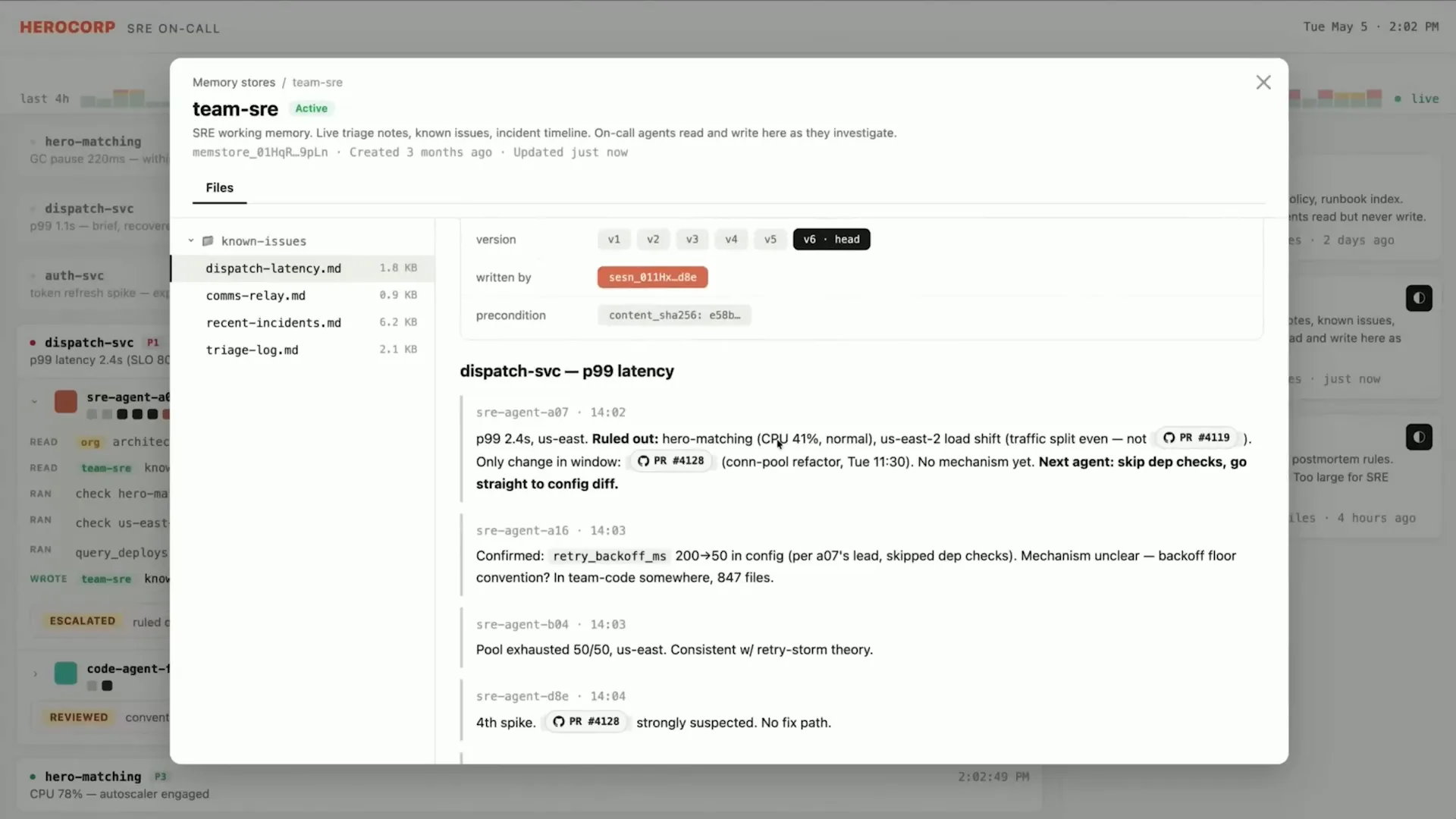 | The shared memory store can be accessed by subsequent sessions. |
Slide 48 — 17:22 (watch)
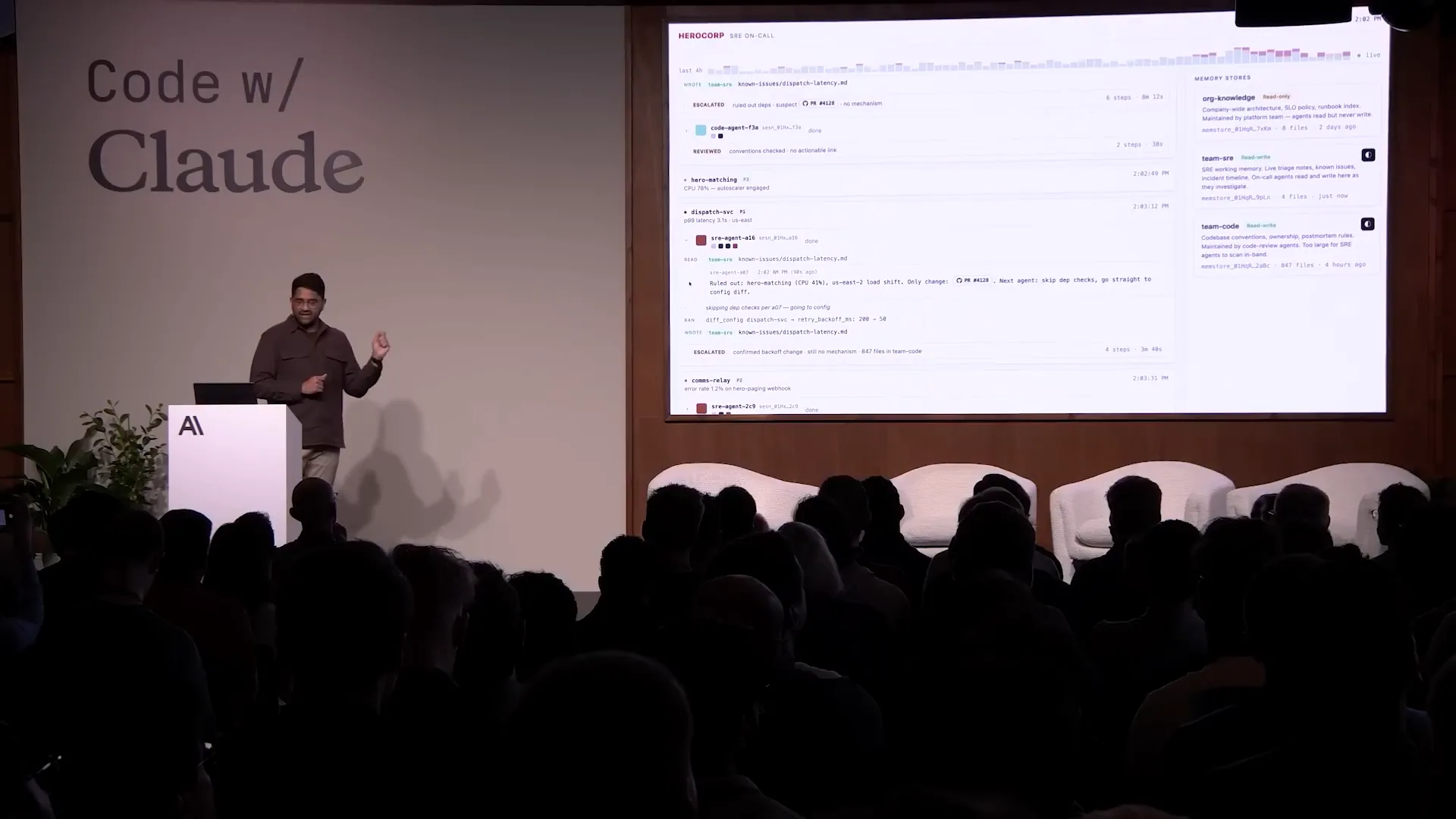 | When a similar issue arises, the downstream session is aware that a fix is in progress and can act accordingly. This is an impressive pattern. |
Slide 49 — 17:38 (watch)
 | Having been an SRE in my career, I can attest that this approach effectively coordinates across all agents. This exemplifies cross-session memory in action. |
Slide 50 — 17:54 (watch)
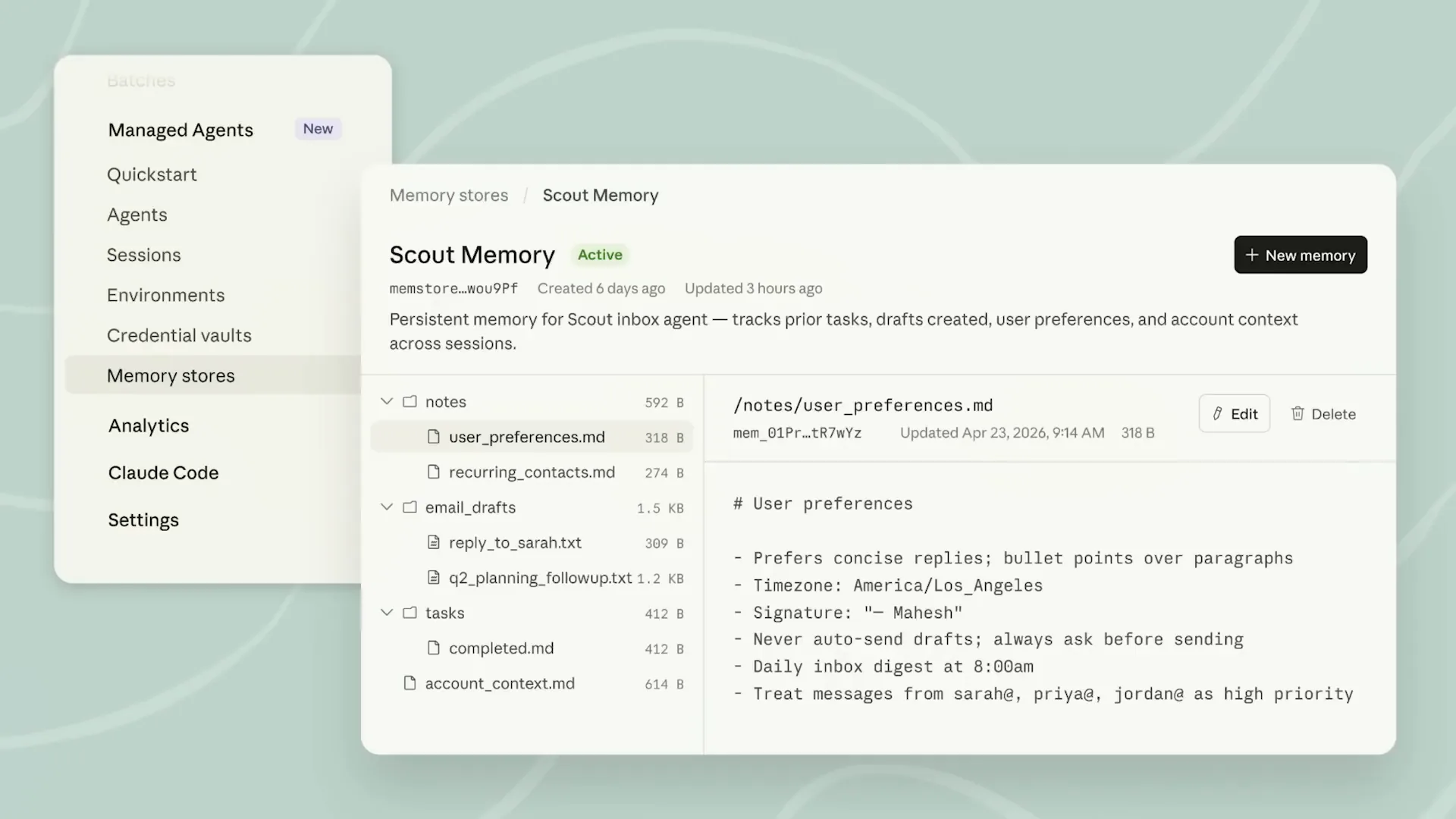
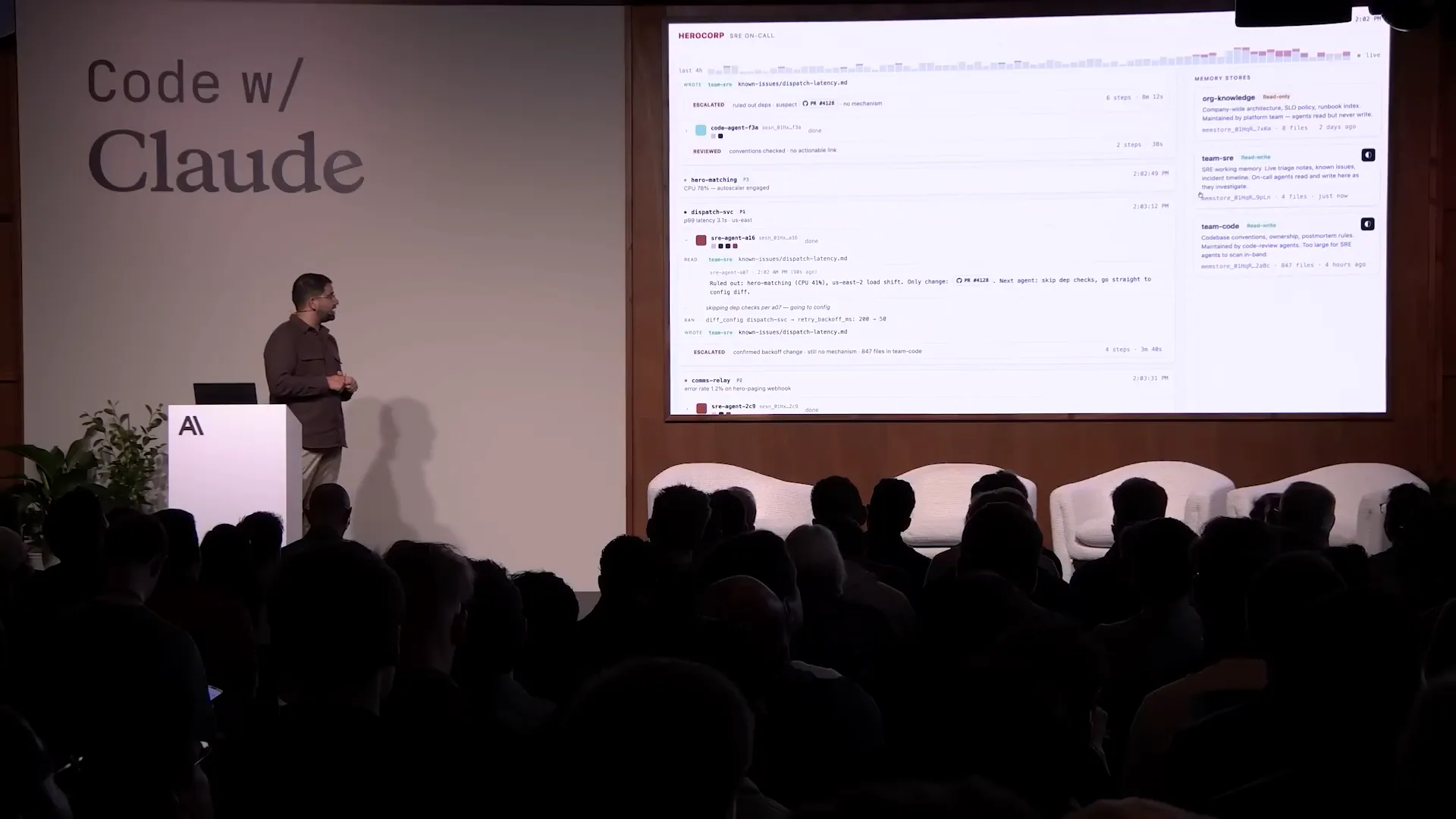 | For enterprise applications, an important aspect is audit logs and history. With memory, you can access the complete version history. |
Slide 51 — 18:14 (watch)
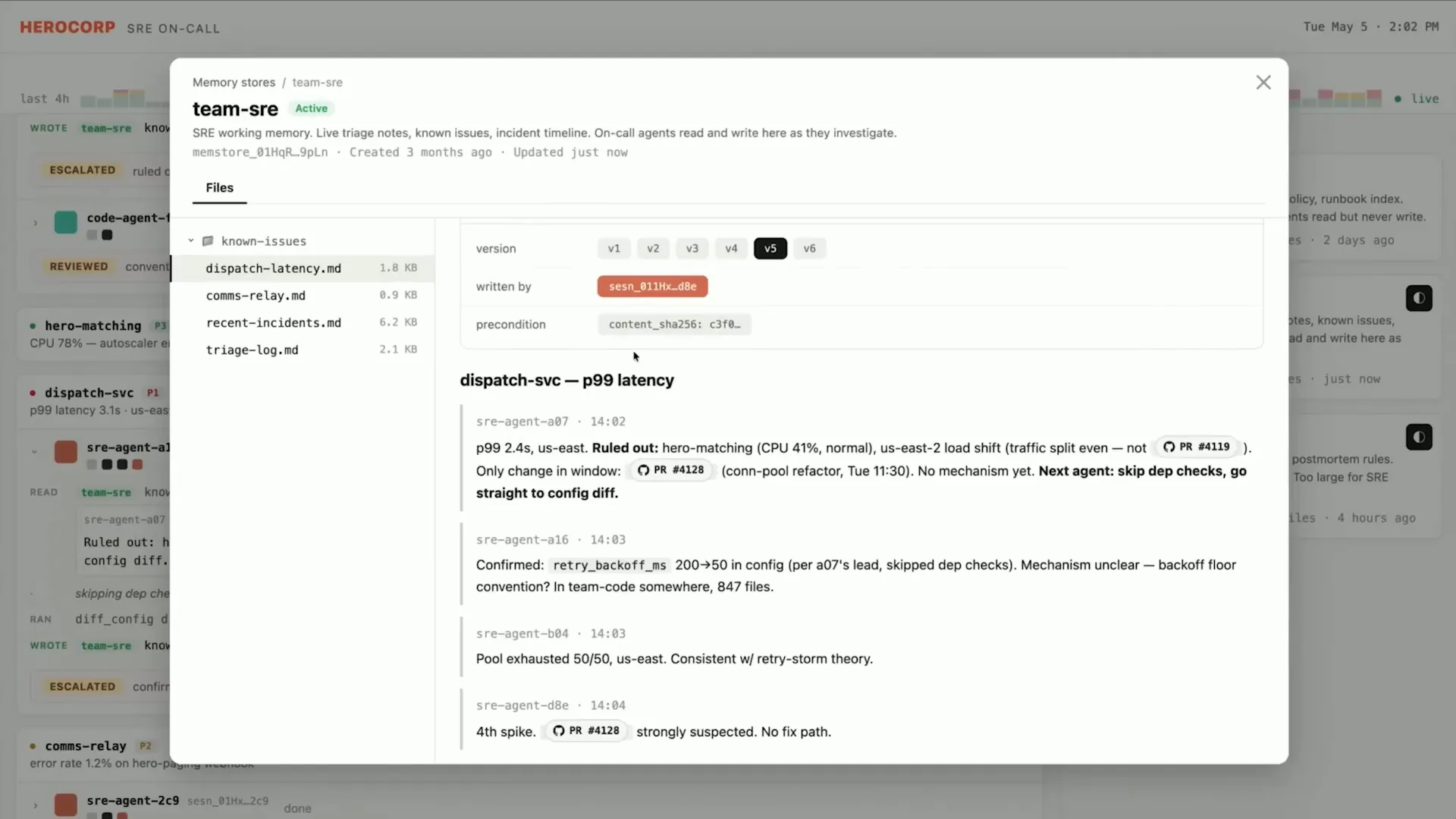 | You can switch between different versions and attribute the writes to specific sessions. Additionally, the optimistic concurrency model ensures that agents do not overwrite each other's writes. Now, let's switch over to the Cloud console. One moment. There we go. |
Slide 52 — 18:34 (watch)
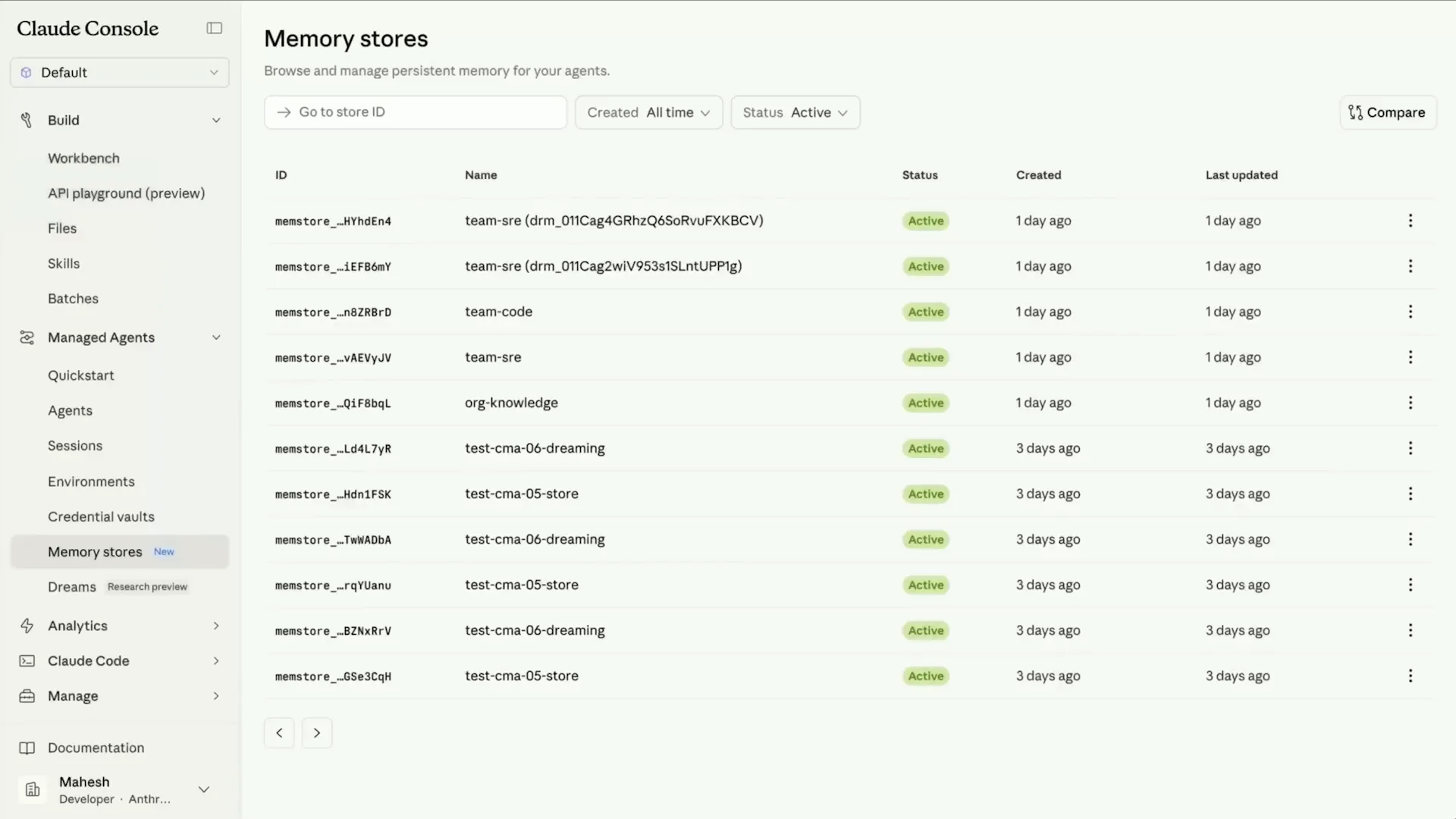 | Here we see the list of underlying memory stores used in the application. Let's go over to our team SRE memory store. |
Slide 53 — 18:42 (watch)
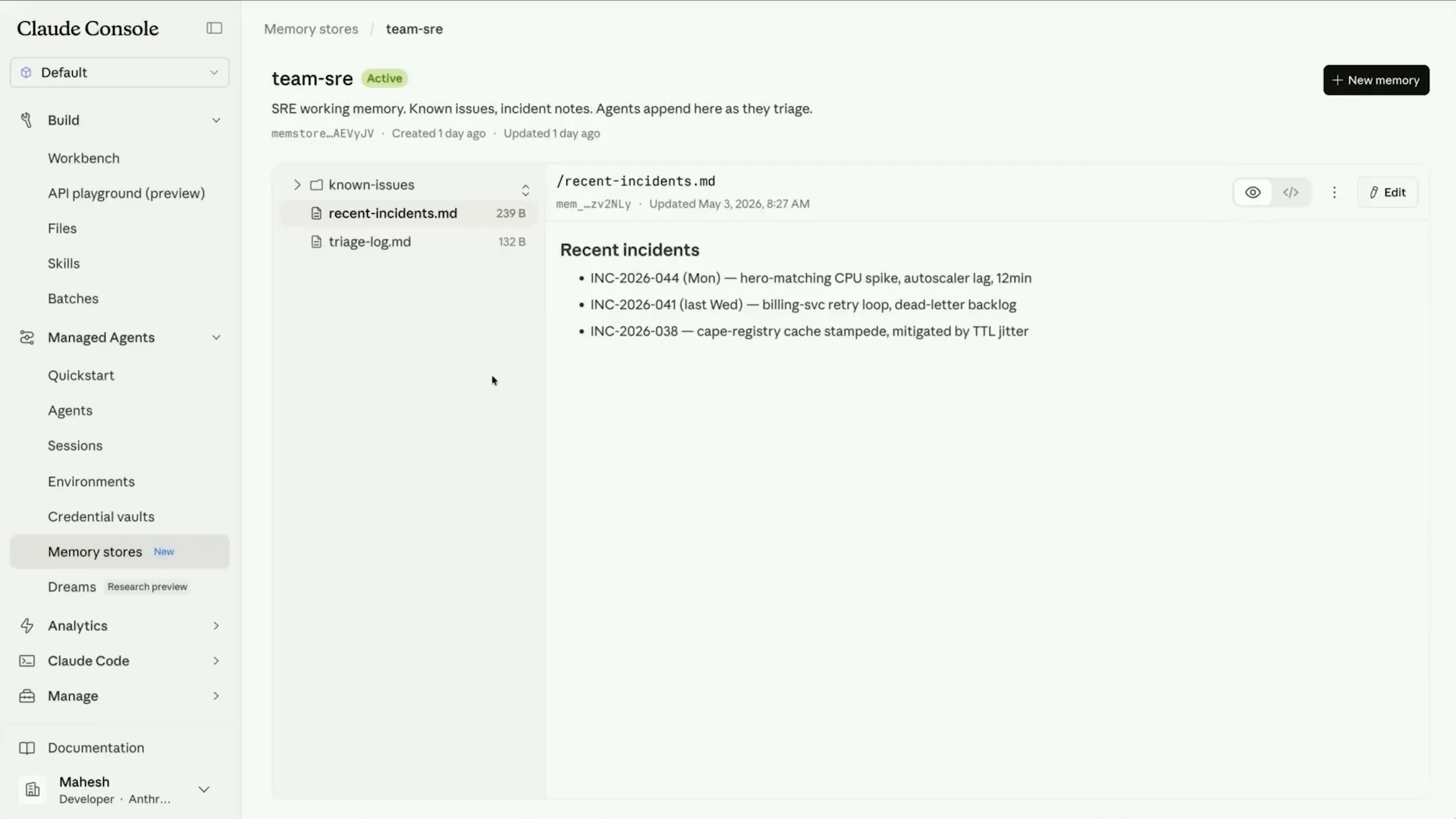 | You can see the underlying files that were populated there. Now, let's head over to the dreams tab. |
Slide 54 — 18:48 (watch)
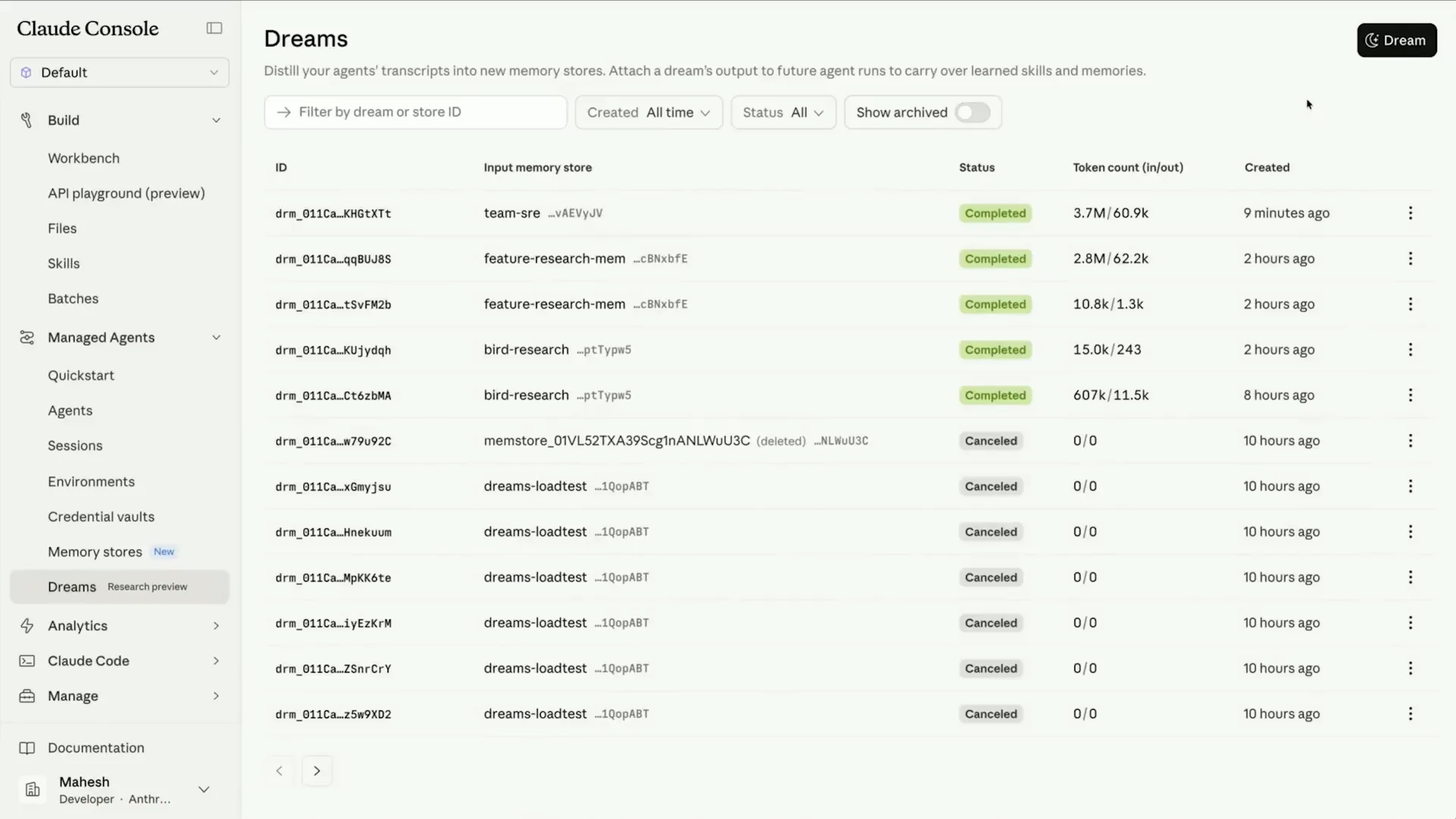 | We will now kick off a dream. |
Slide 55 — 18:56 (watch)
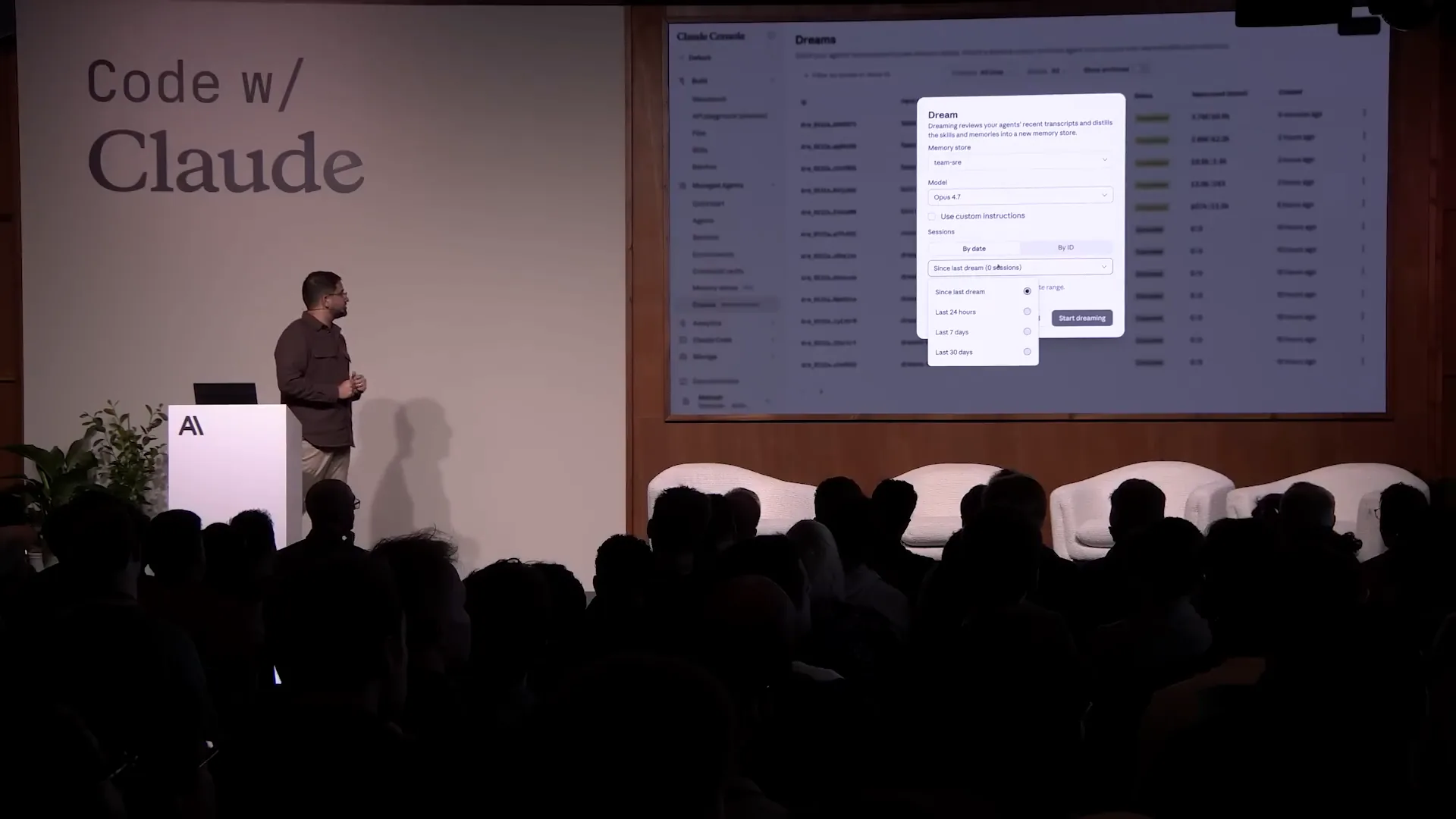 | This can be done via the API or the UI. We will select the team SRE memory store and choose a batch of sessions from the last seven days, which amounts to about five sessions. |
Slide 56 — 19:06 (watch)
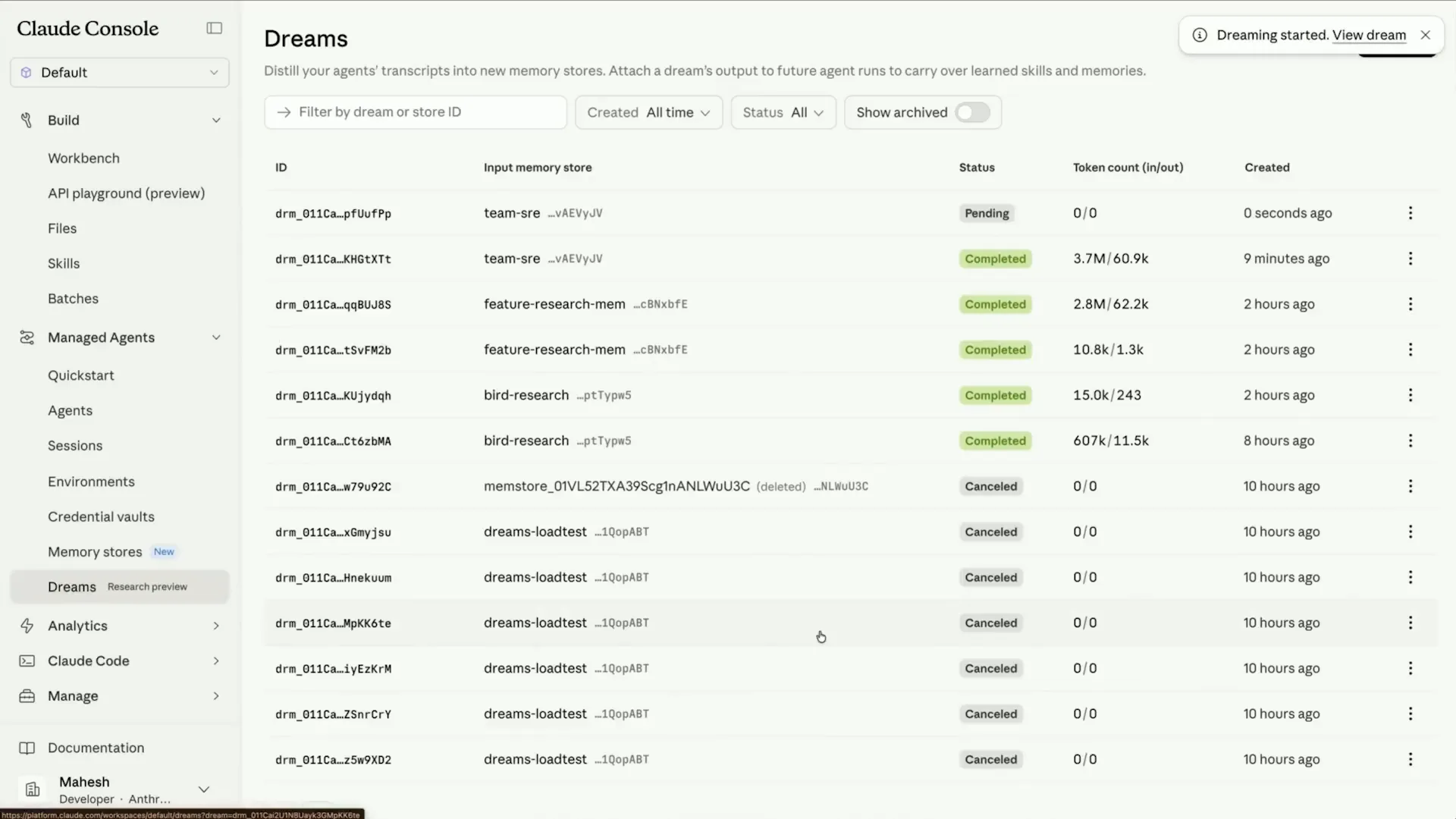 | We will now start the dreaming process. As it begins, you can observe it making progress. |
Slide 57 — 19:12 (watch)
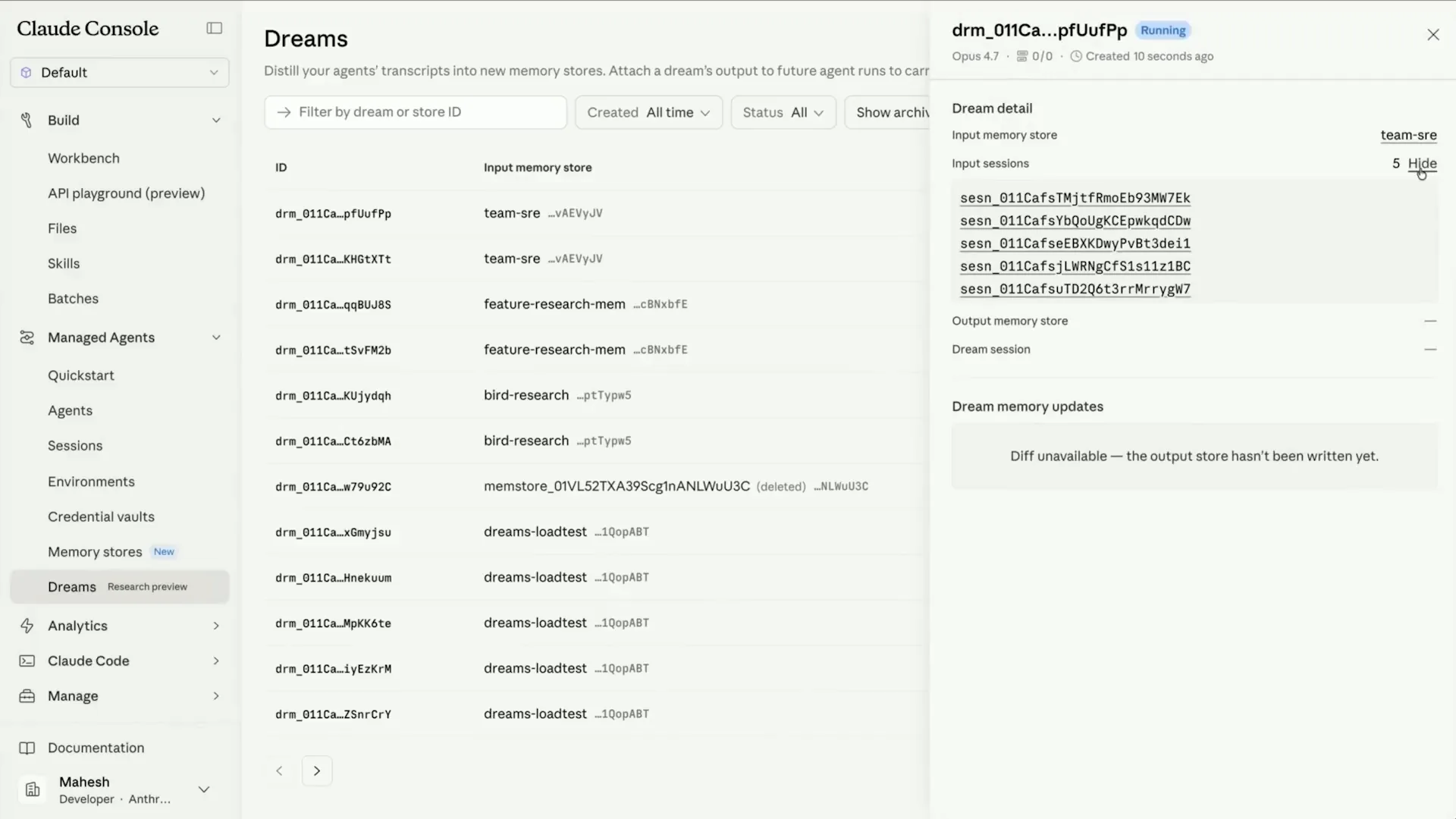 | In the dream, there are five input sessions, and an output memory store is being compiled. |
Slide 58 — 19:24 (watch)
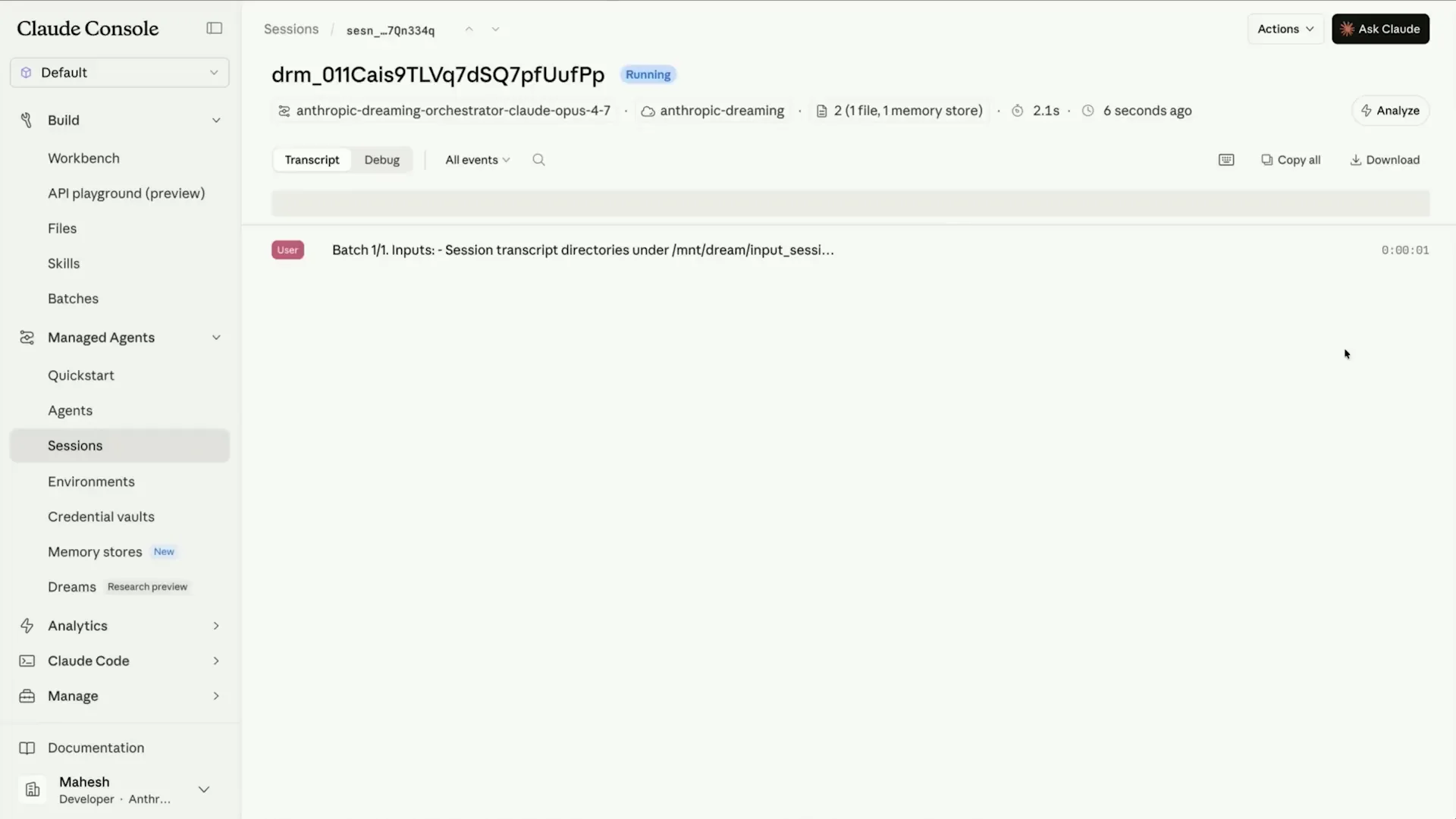 | You can open the dreaming session, which is an important feature built on Cloud managed agents. It spins off a series of subagents to analyze transcripts in parallel and maintains the same user experience as the other managed agents. |
Slide 59 — 19:40 (watch)
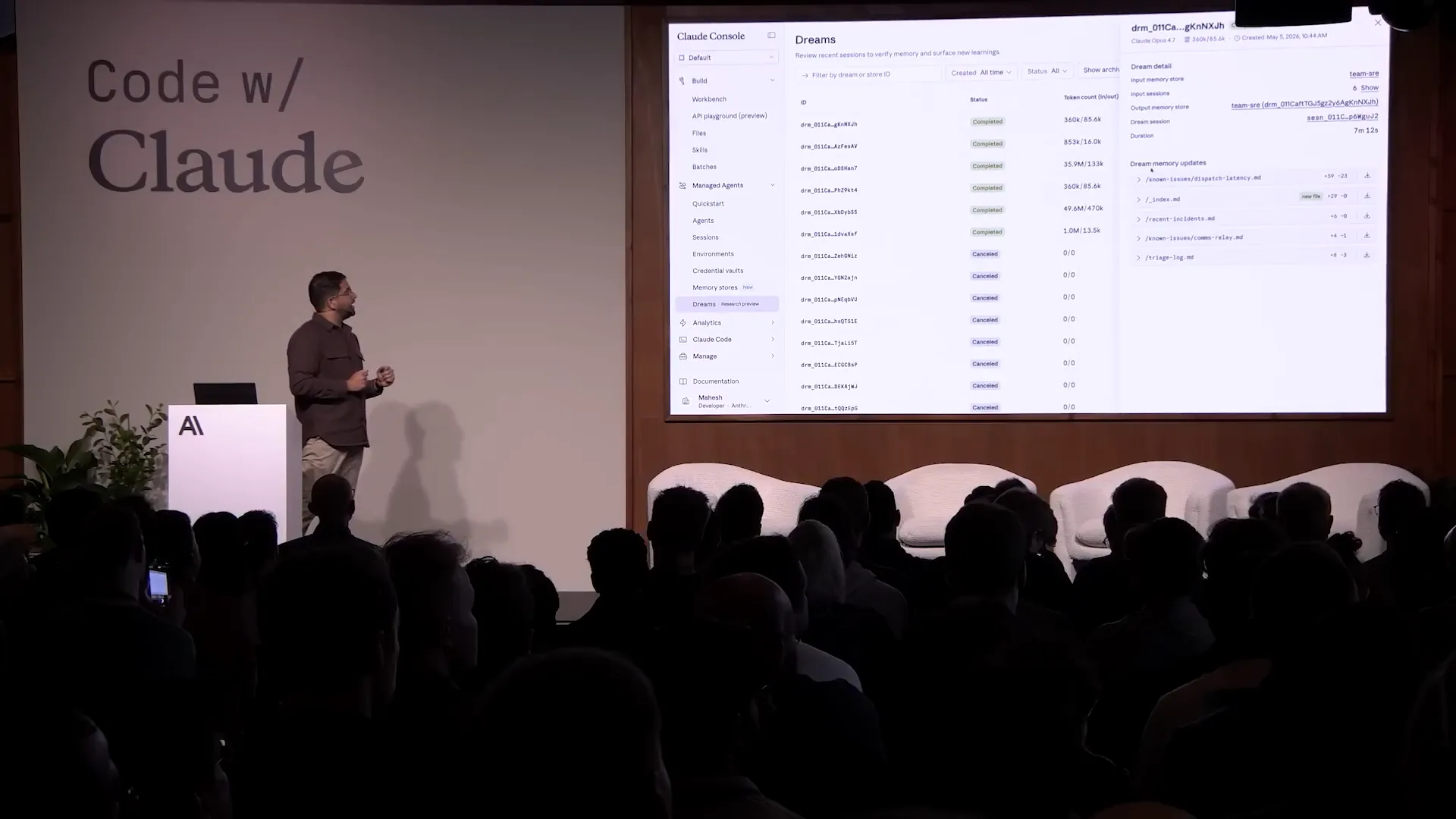 | We'll fast forward to a completed dream session, where you can see the differences in the memory store updates. |
Slide 60 — 19:50 (watch)
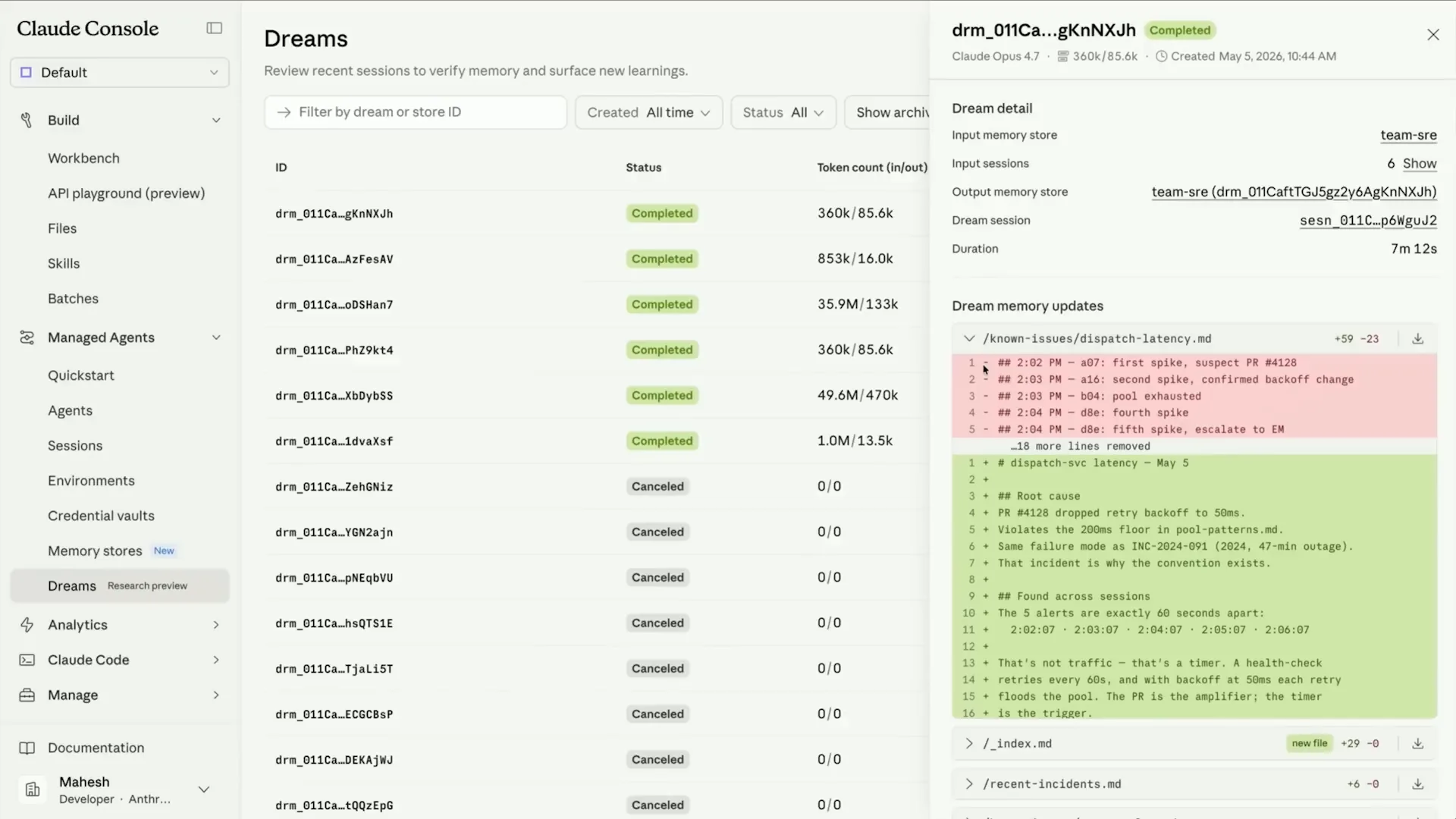 | In this example, we observe a common pattern across sessions and agents where an alert is triggered 60 seconds after a CPU event. |
Slide 61 — 20:02 (watch)
 | This pattern recurs consistently. |
Slide 62 — 20:06 (watch)
 | It starts to discern that there may be an issue with the retry behavior. |
Slide 63 — 20:20 (watch)
 | The dreaming process records and updates memory, allowing the next agent that encounters this pattern to act on the information. |
Slide 64 — 20:30 (watch)
 | It also updates the triage log in a more holistic manner, rather than simply serving as a rote record of all the events that occurred. |
Slide 65 — 20:34 (watch)
 | That's memory and dreaming in action. Now, let's return to the slides. |
Slide 66 — 20:44 (watch)
 | In this demo, we demonstrated how to build a production agent that utilizes memory and dreaming for self-improvement. |
Slide 67 — 20:54 (watch)
 | This year is going to be significant. |
Slide 68 — 20:58 (watch)
 | We will see agents operating over increasingly longer timescales, such as days. |
Slide 69 — 21:06 (watch)
 | Continuously building upon and improving their understanding of the world is critical to unlocking that capability. |
Slide 70 — 21:16 (watch)
 | Memory systems will play a significant role in enabling this behavior. I encourage you to explore this further. I'm excited to see what everyone creates with it. |
Slide 71 — 21:32 (watch)
 | I'll be outside if you have more questions. Thank you. |