44 slides extracted.
Slide 1 — 0:08 (watch)
 | I'm Nupur, and I work with Qodo. |
Slide 2 — 0:18 (watch)
 | At Qodo, we conduct agentic reviews. |
Slide 3 — 0:26 (watch)
 | I have a background in DevSecOps, coming from an industry where everything is deterministic. In that environment, pipelines run and if they crash, we fix them. Now, I am working with agents in a space where nothing is deterministic. |
Slide 4 — 0:42 (watch)
 | In the past few years, I have learned where and how agents fail and what insights can be drawn from these experiences. Today, I will share some of these learnings with you. |
Slide 5 — 0:58 (watch)
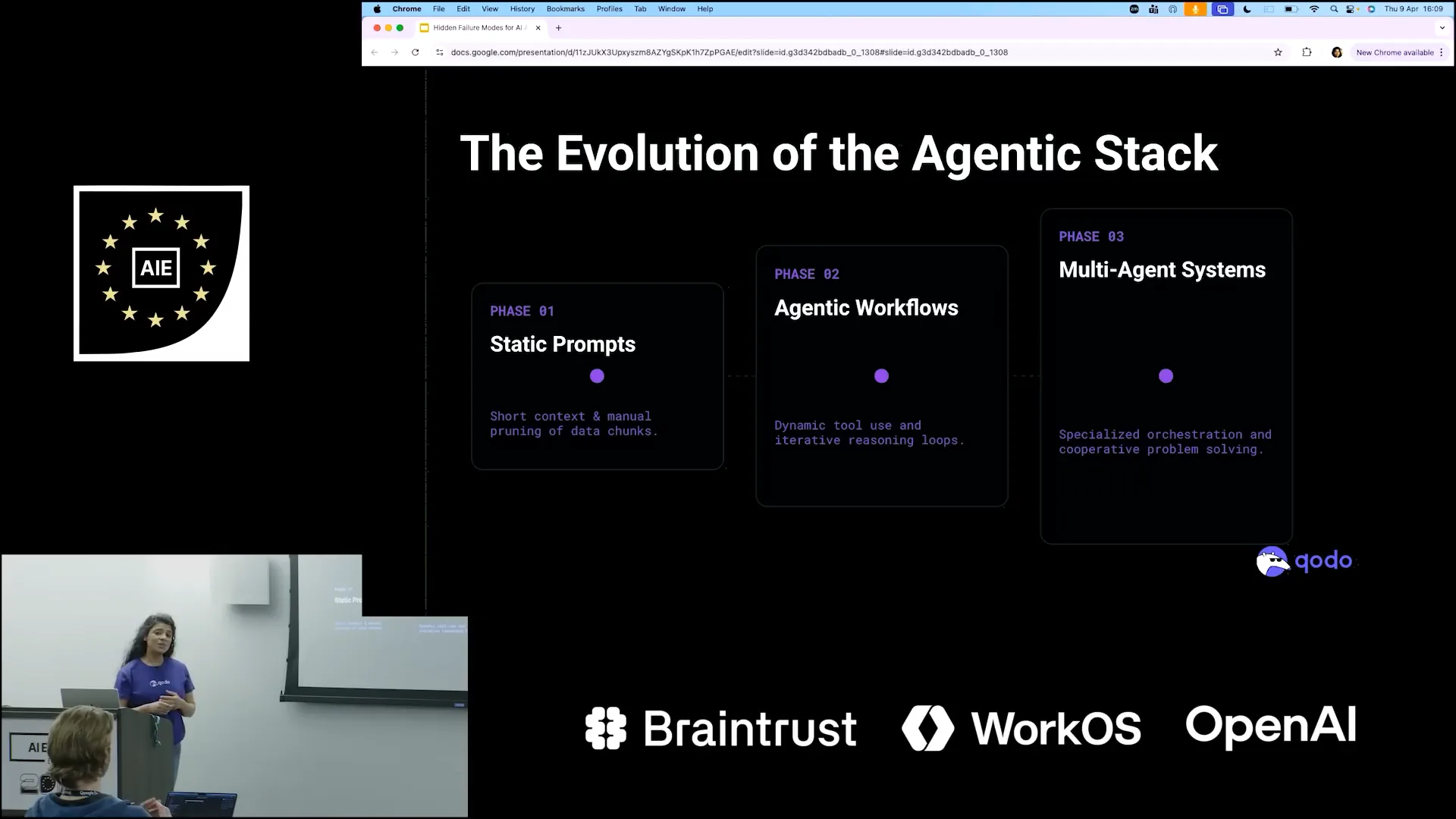 | The evolution of agents began with static prompts, which utilized a 4K context window. We aimed to include everything we considered important for the AI models to process and generate results. |
Slide 6 — 1:40 (watch)
 | Initially, it was our responsibility to instruct LLMs on what to focus on. If we provided incorrect inputs, the results would be inadequate. We then considered that increasing the context window size could improve outcomes by allowing for more inputs, leading us to develop agentic workflows. We created agents equipped with tools, such as a search tool, to explore documents and execute commands. However, this created a loop where the tool continuously sought more inputs, unsure of when to stop. To address this, multi-agent systems have gained popularity, enabling multiple agents to collaborate on tasks. For instance, a security agent can identify security concerns, a review agent can evaluate tools, and a coding agent can address issues. |
Slide 7 — 2:26 (watch)
 | The more tools you have, the more issues arise. Not every agent understands the context, leading to clashes in their interpretations, which prevents you from achieving the desired results. |
Slide 8 — 2:56 (watch)
 | What can we learn from this? Context itself is not the issue. Models are increasingly capable of handling large amounts of context and data. However, this does not guarantee that the results will be intelligent or that they will prioritize important information. Current LLM models exhibit a pattern where they consider the initial and final inputs but often disregard the context in between. They focus on the starting and ending points to generate results, neglecting the intermediate context. |
Slide 9 — 3:48 (watch)
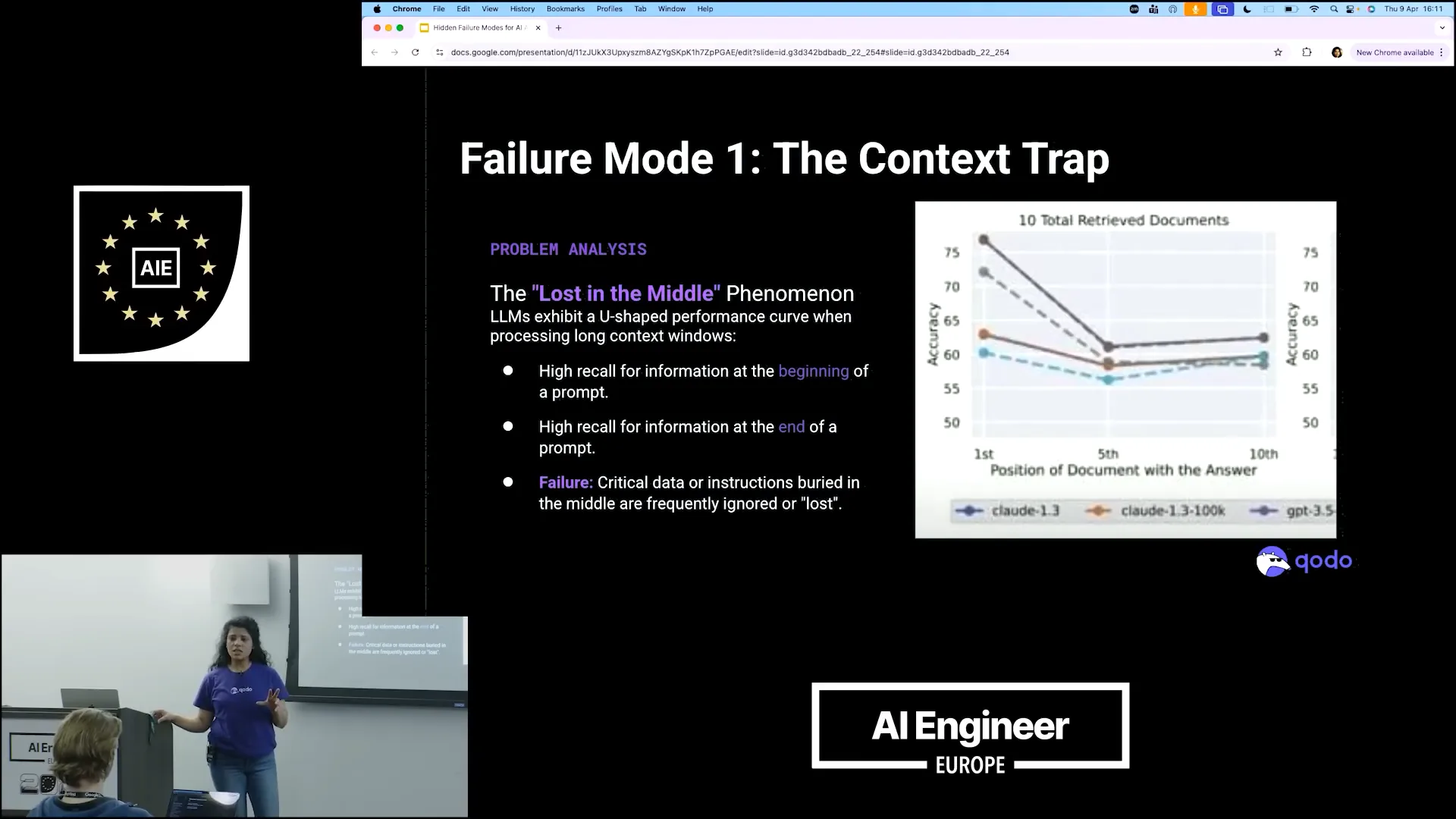 | This resembles a U-curve where elements from the beginning and end are relevant, but the in-between context is overlooked. We are actively working on this issue and benchmarking our findings. When we create agents, we assess whether the provided context influences the results. We are employing a multi-agent architecture for various tasks, such as code reviews. For each task, we assign it to an agent and request the outcome. During code reviews, we explore whether we can provide the entire context, such as the complete codebase, to improve results. However, we observe that the initial prompt or goal remains the primary focus throughout the process. |
Slide 10 — 4:24 (watch)
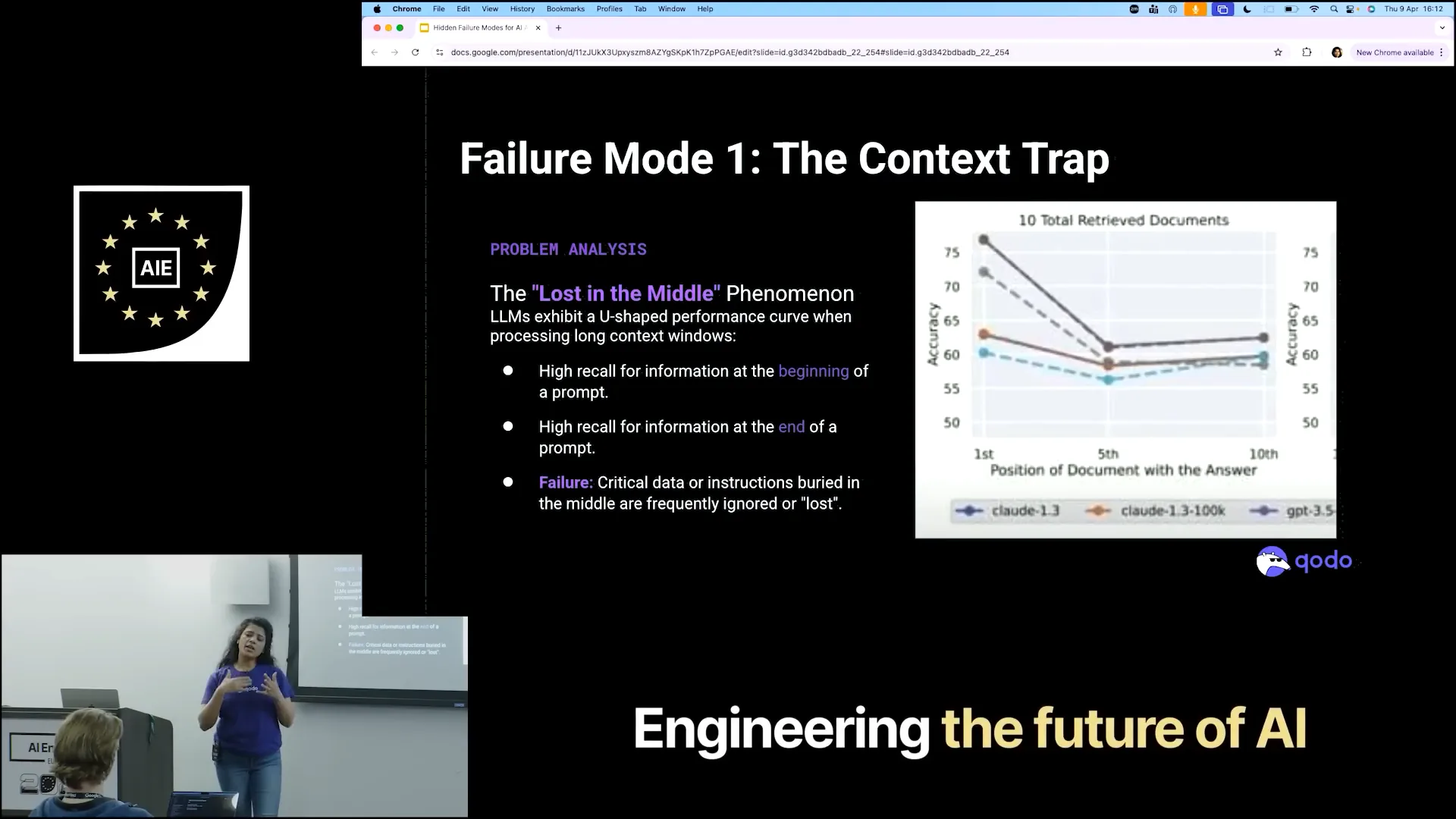 | When we provide input at the end, that input is in focus. However, the surrounding context, such as JIRA tasks or MCPs, can complicate matters. LLMs attempt to eliminate these extraneous details and make sense of the information independently. |
Slide 11 — 4:54 (watch)
 | To address this issue, we create strategic solutions for context optimization instead of simply dumping all information into the models and expecting them to discern what is important. We begin by evaluating how to improve the context for the model. Currently, many solutions exist, and "context engine" has become a buzzword; everyone wants to develop one. However, a context engine functions like a bouncer. It guides the high-speed car, indicating what is more important. |
Slide 12 — 5:48 (watch)
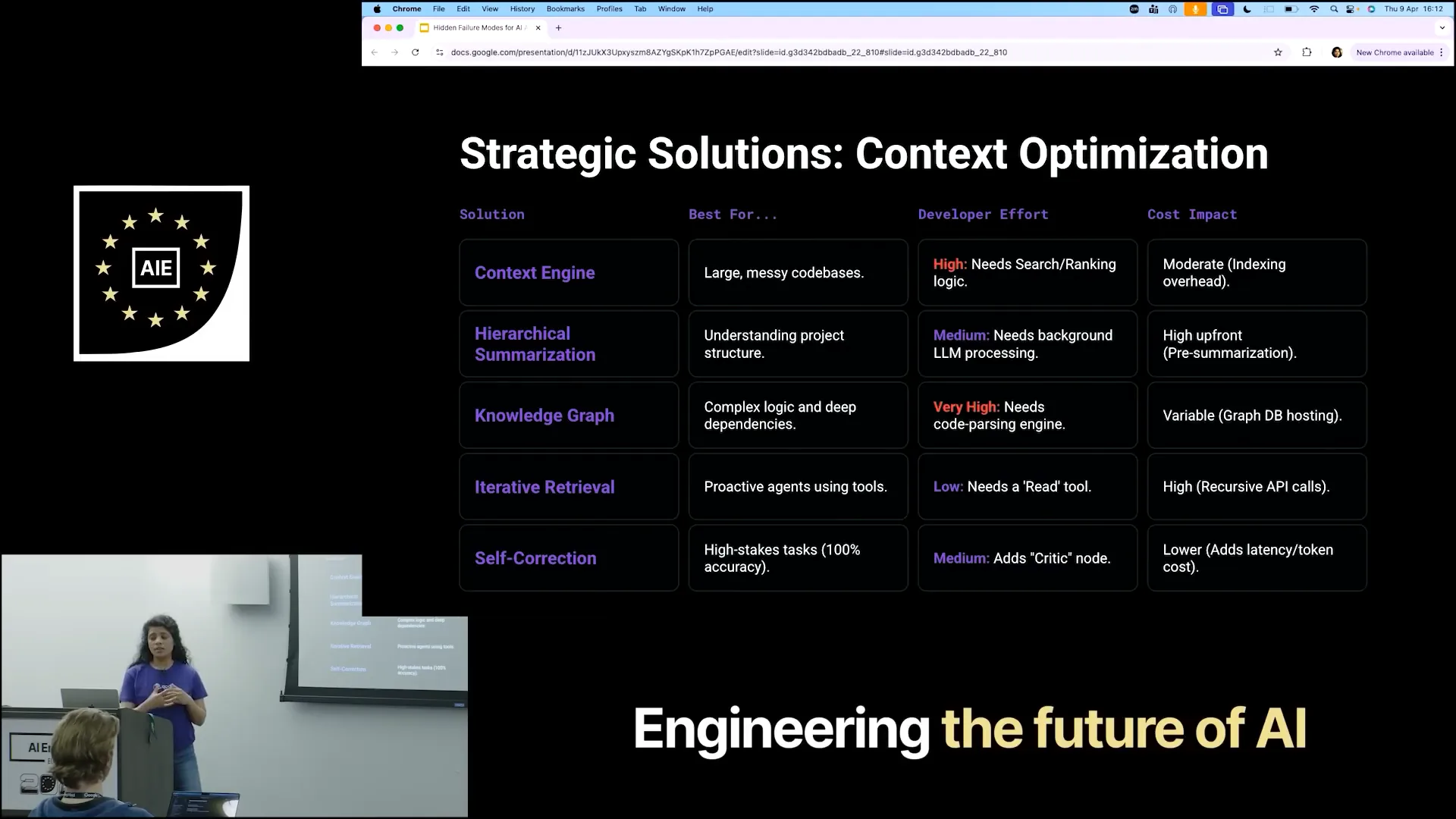
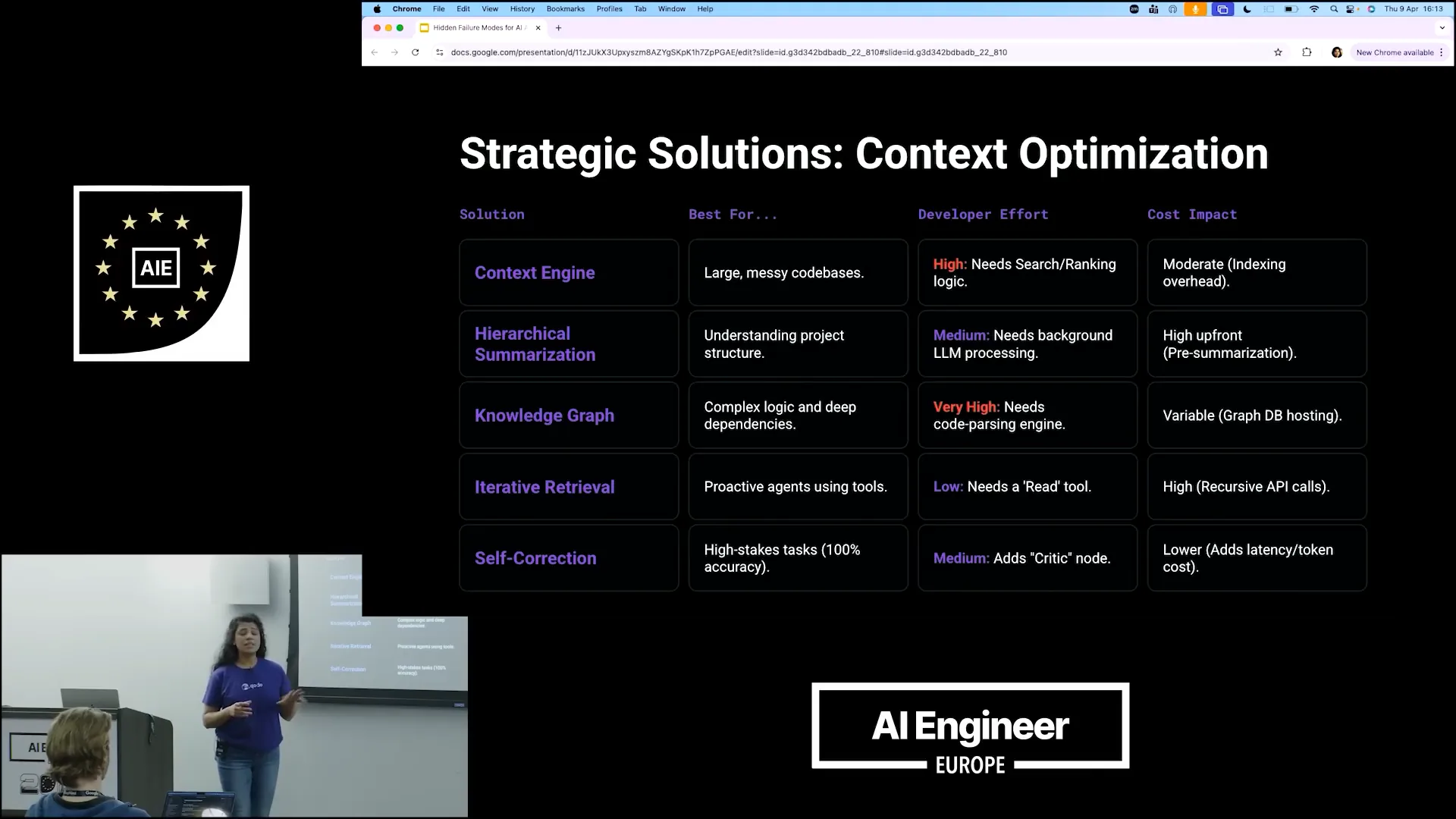 | Creating a context engine is beneficial for managing a large, messy codebase. It establishes a search pattern and ranking logic, allowing the system to prioritize tasks based on importance. While indexing requires moderate effort, scaling becomes challenging with hundreds of repositories, as mapping and indexing can slow down and make it unpredictable to develop an effective context engine. Instead of heavily investing in a context engine, there are alternative methods for agents to gain context. One such method is hierarchical summarization, where summaries are generated for each file and folder. This allows agents to quickly assess the relevance of content without needing to sift through everything. |
Slide 13 — 6:48 (watch)
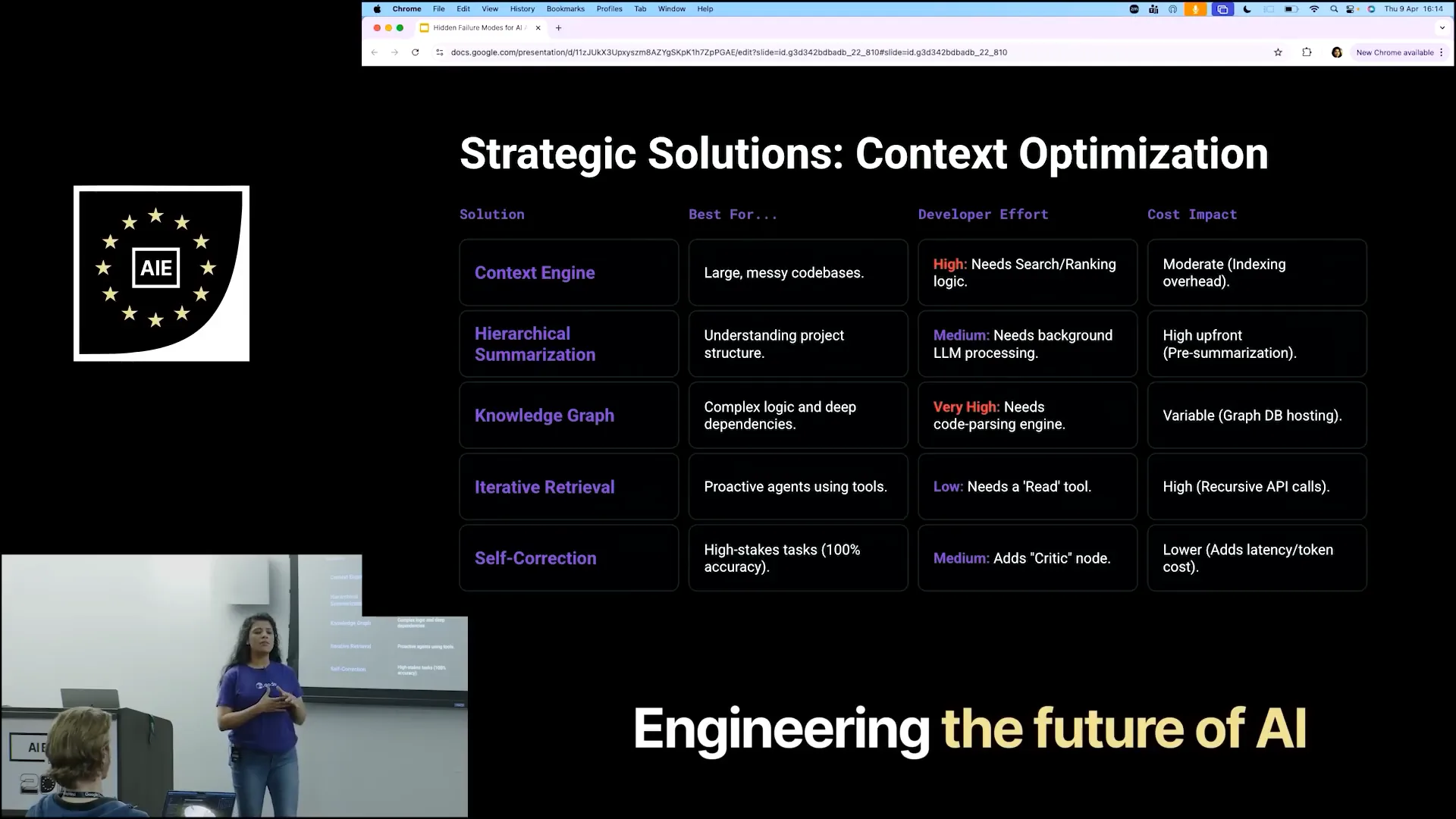 | Implementing this approach requires significant LLM processing. Each time a file is created or modified, some agents must generate a mapping for that change, resulting in a high upfront demand for LLM processing. An alternative is to use a knowledge graph. While knowledge graphs can be complex, they are highly effective for managing logical dependencies. For instance, if one file affects another, which in turn impacts additional files, you can create a graph to represent these relationships. However, the initial input required from developers is substantial, and it can be time-consuming to establish. Nevertheless, when dealing with complex logic or dependencies across multiple repositories, this method proves to be very effective. |
Slide 14 — 7:24 (watch)
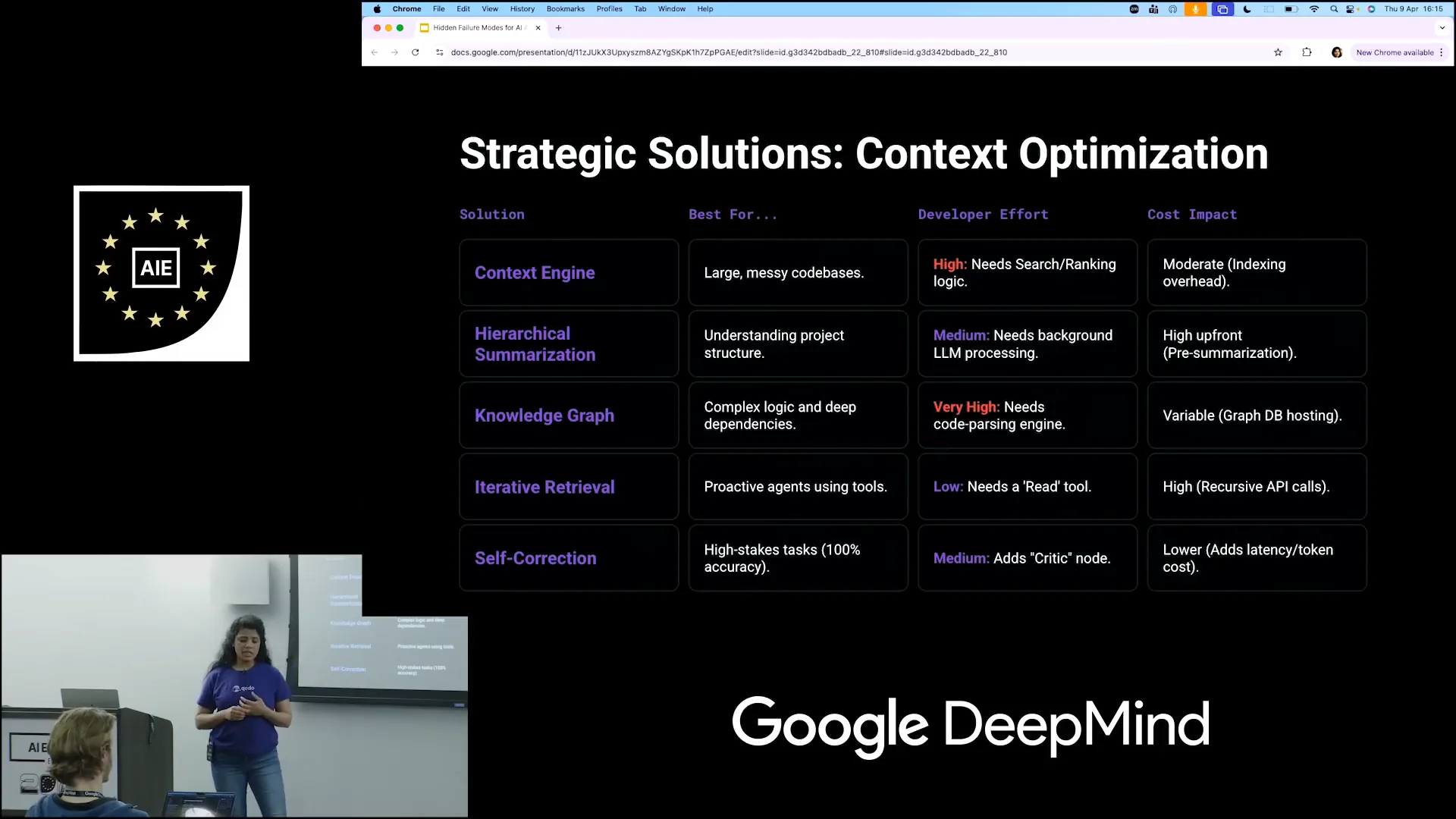 | For most tasks, especially if you're not a product company but are building agents for your own processes, iterative retrieval is highly effective. Instead of creating a summary, it generates an index, similar to a library card, which you provide to your agents to indicate the topic. |
Slide 15 — 7:40 (watch)
 | If that resonates with you, you can examine the code to find the results. While there are significant cost implications, you do not need to invest a lot of energy. |
Slide 16 — 7:56 (watch)
 | The input required from developers for LLMs is minimal, yet it yields better results. Additionally, there is an option for self-correction, where the LLM performs a task and a critic node evaluates its relevance to the initial goal. |
Slide 17 — 8:16 (watch)
 | If the context is lost, you can ask the agent to retry the task, as indicated by the critic node. This process introduces some latency due to the need to rerun the agents, but it does not require significant initial input from developers to create a solution. |
Slide 18 — 8:52 (watch)
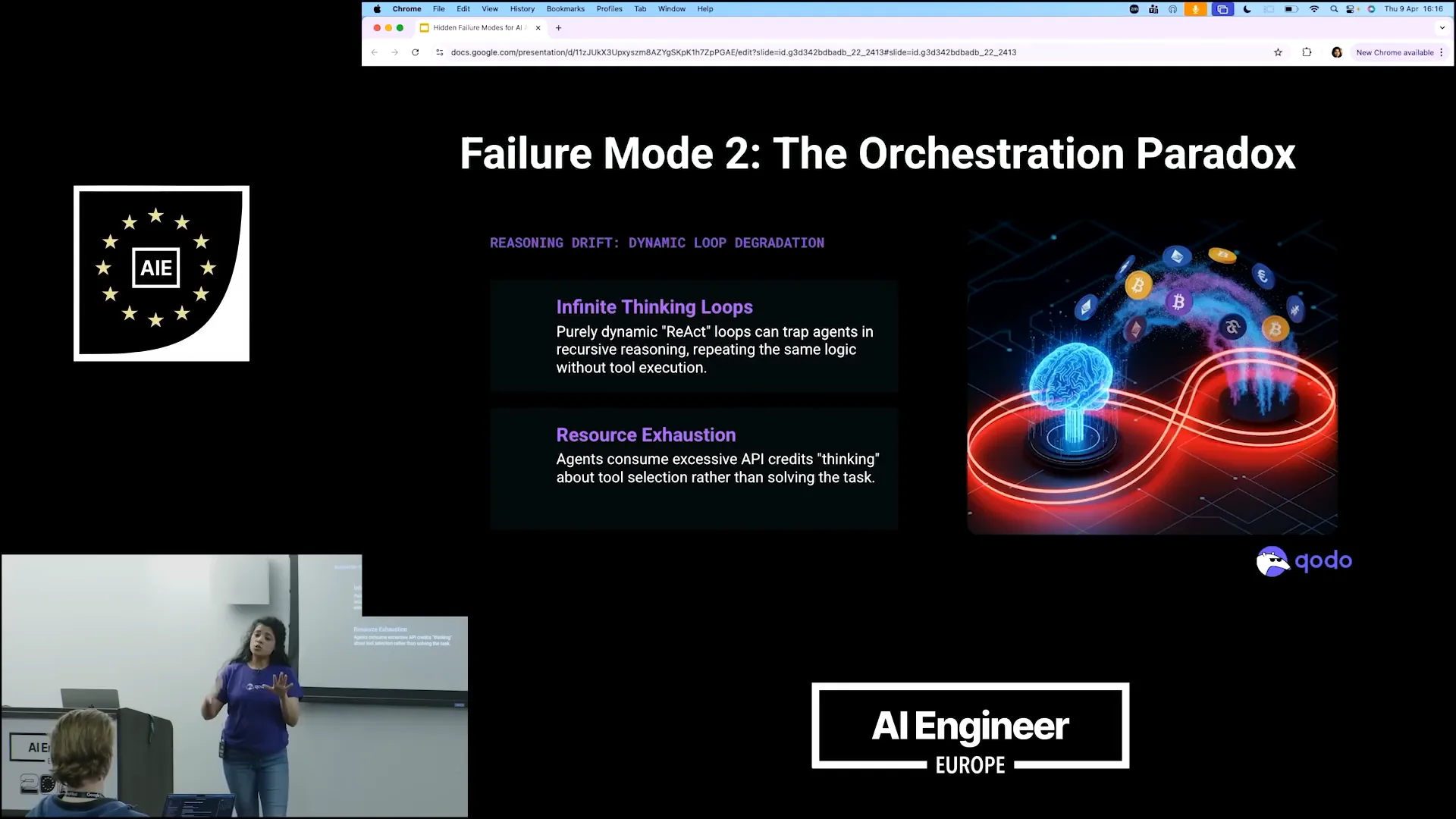 | Another challenge that arises when creating these agents is the orchestration paradox. As LLMs become increasingly sophisticated, they tend to overthink their tasks. Instead of focusing on solving the problem, they spend time considering which tools to use and researching better methods. This leads to a cycle where they jump from one approach to another, wasting API tokens on exploration rather than execution. Consequently, they enter a research mode instead of actively addressing the problem at hand. |
Slide 19 — 9:26 (watch)
 | For example, when using Opus, users often seek the best method repeatedly, challenging themselves to find alternatives. This results in a loop of trying different approaches rather than taking action. |
Slide 20 — 9:56 (watch)
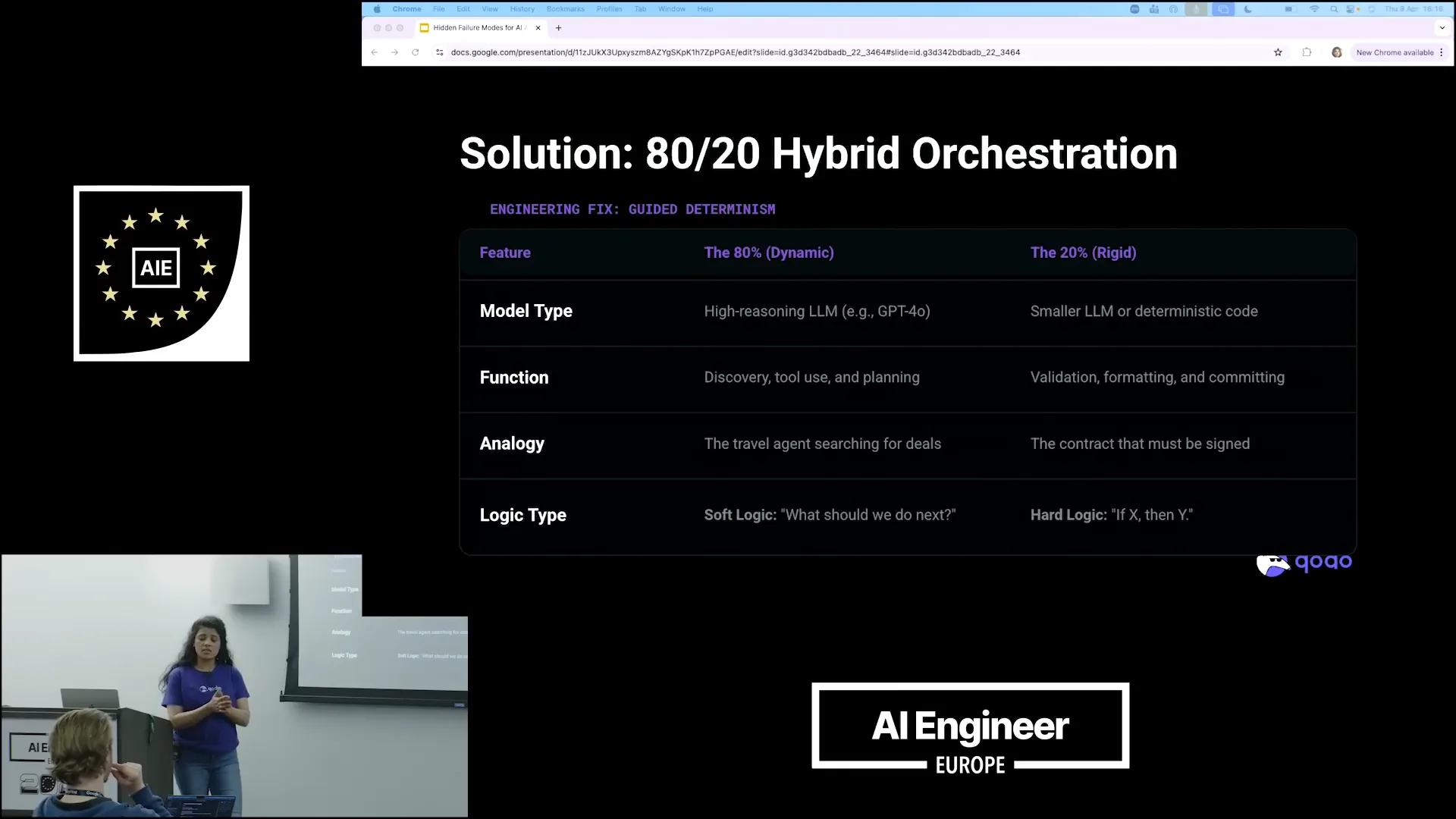
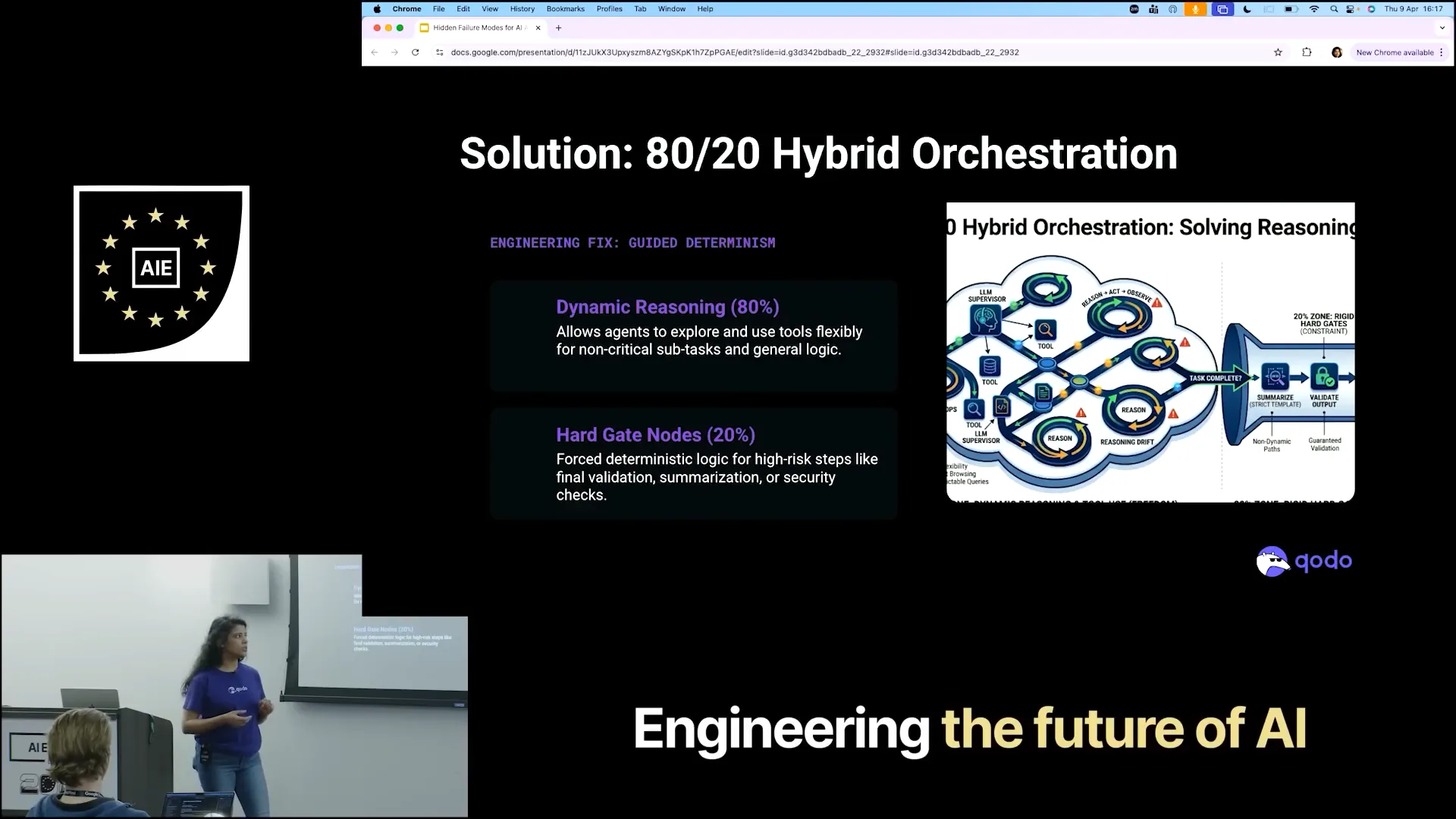 | To resolve this, we employed an 80-20 hybrid approach, which I believe is one of the most effective solutions to the infinite loop problem. Our teams allow the agents to research for 80% of the time, giving them the freedom to explore and innovate. However, for the remaining 20% of the task, which requires final validation and summarization, we impose stricter guidelines. This portion is more deterministic and involves clear criteria that must be met. |
Slide 21 — 10:22 (watch)
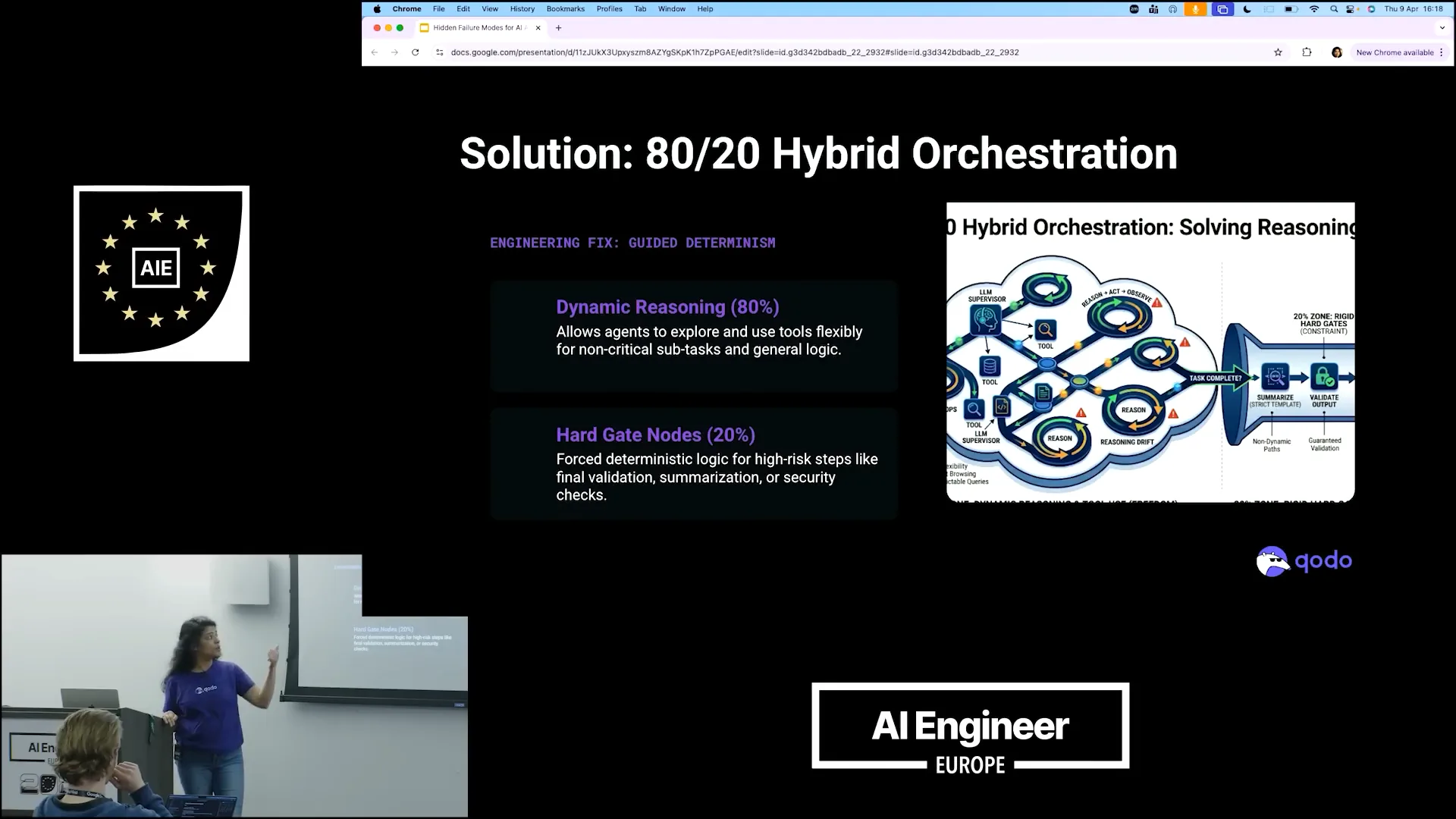 | For example, if I receive X results, I want Y. This approach is more deterministic, allowing us to narrow down the research from the 80%. |
Slide 22 — 10:52 (watch)
 | The 80% tool can still enter infinite loops, but we have mechanisms to address this. Some organizations implement counter mechanisms, where after four or five iterations, they must proceed with the last results. Others use timeout counters, where after five minutes, they work with the most recent decision and can revisit it if the results are unsatisfactory. While you can limit the 80%, it is important to note that for tasks like discovery or tool selection, the 80% research models are quite effective. However, when it comes to summarization or evaluating the research obtained, the focus shifts. |
Slide 23 — 11:46 (watch)
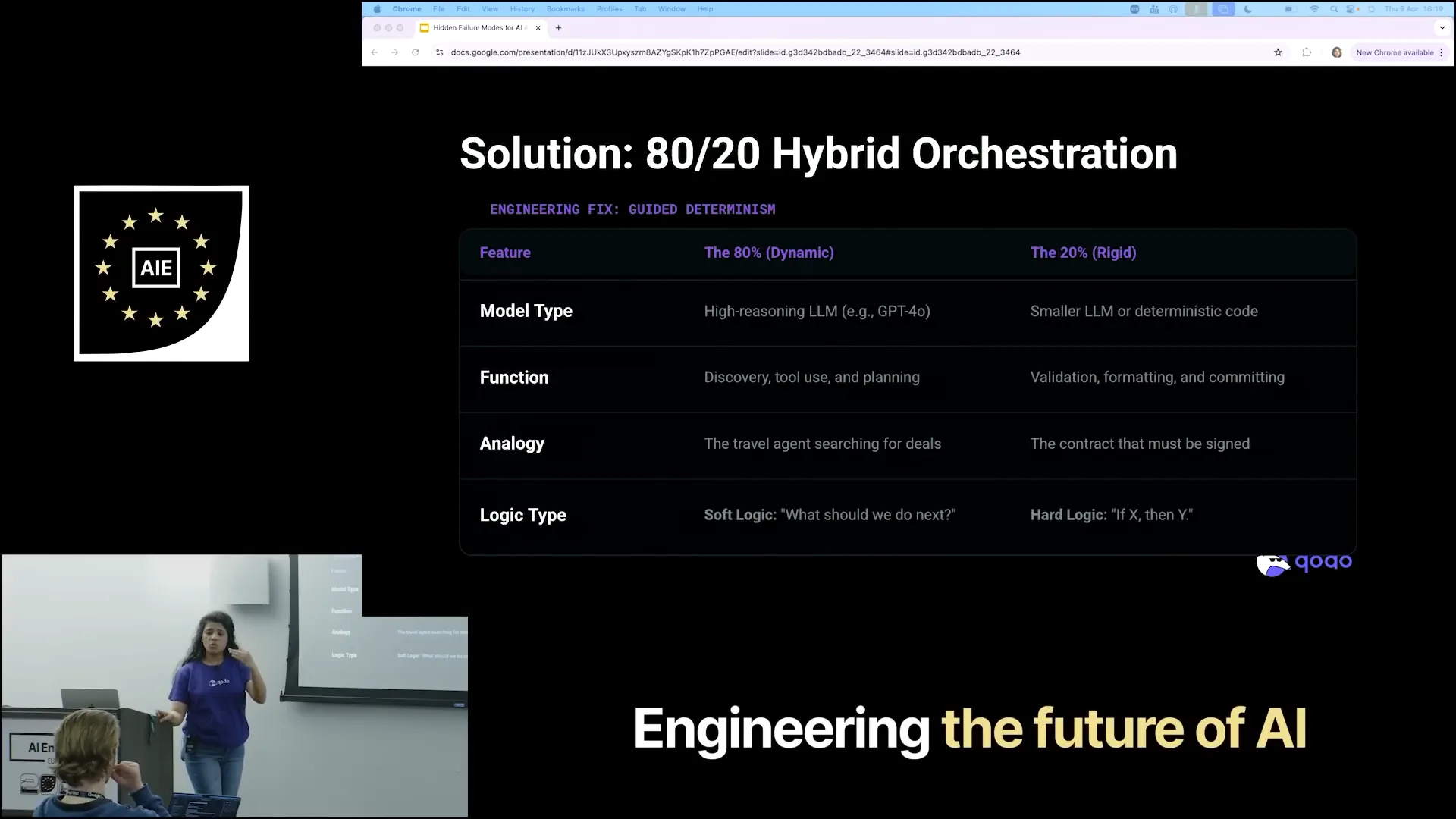 | To generate a result, the 20% models are highly effective. Typically, the 80% models require high reasoning capabilities, but this is not necessary for the 20%. The 20% tasks are deterministic and focus on delivering what is needed. For instance, the critic node we discussed does not require extensive research or analysis; it simply needs to understand the goal and the desired outcome to provide a summary. Additionally, when considering the next possible action based on the results, the 80% dynamic models can help determine what to explore next. However, it is essential to identify the proper results that the user is seeking from the 80% models. |
Slide 24 — 12:18 (watch)
 | Those kinds of decisions can be made by the 20% model. |
Slide 25 — 12:46 (watch)
 | As the context grows, teams often believe they can accomplish everything with a single agent due to the large context window. They assign various tasks to the agent, such as testing and reviewing, thinking that the shared context will yield comprehensive results. However, this can overwhelm the agent with inputs, causing it to lose sight of the original task. For example, if you assign four tasks, the agent may excel at two while neglecting the other two. This leads to great results for some tasks, but others may be overlooked entirely. |
Slide 26 — 13:46 (watch)
 | We have a concept called mixture of agents, which is where you hear a lot of buzz about multi-agent architecture. Instead of creating one large agent, we develop specialized expert agents that excel at specific tasks. Each agent generates its own ideas or results, and we need to ensure that these results can be combined coherently. For example, if I ask one agent to find the best hotel, another to find the best location, and a third to find the best flights, I might receive conflicting results. One agent may suggest a hotel in Greece, while another finds a flight from Amsterdam to Portugal, leading to a situation where the results do not align logically. |
Slide 27 — 14:22 (watch)
 | For this purpose, there is a concept called a judge agent. Its role is to gather all the results and determine if they can be integrated coherently. |
Slide 28 — 14:34 (watch)
 | Now, you are leveraging the strengths of different agents to obtain the best results from each. The judge agent helps combine these results into a coherent whole, rather than presenting a collection of disparate outputs that do not make sense together. |
Slide 29 — 14:42 (watch)
 | We have implemented a similar approach. |
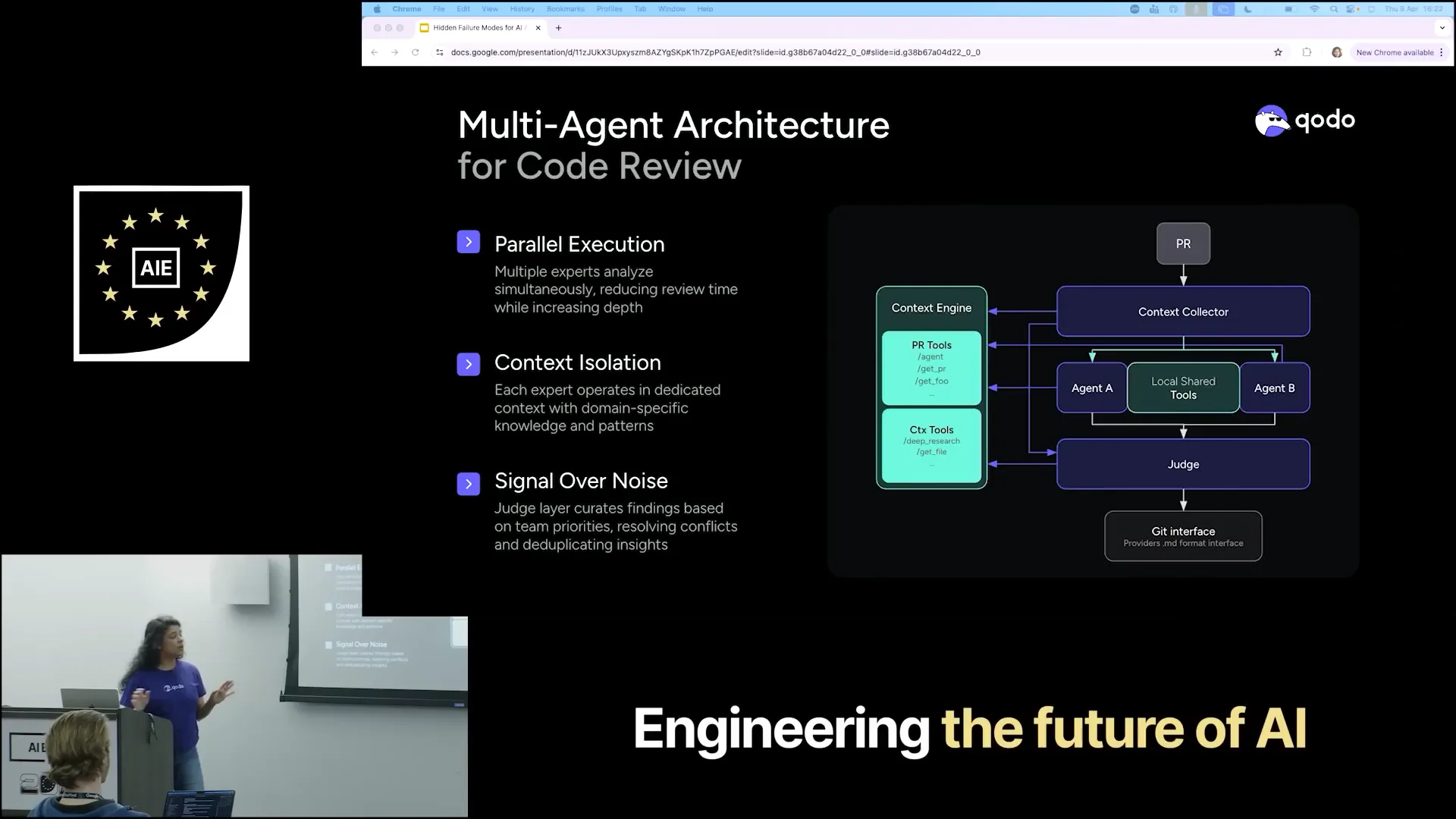
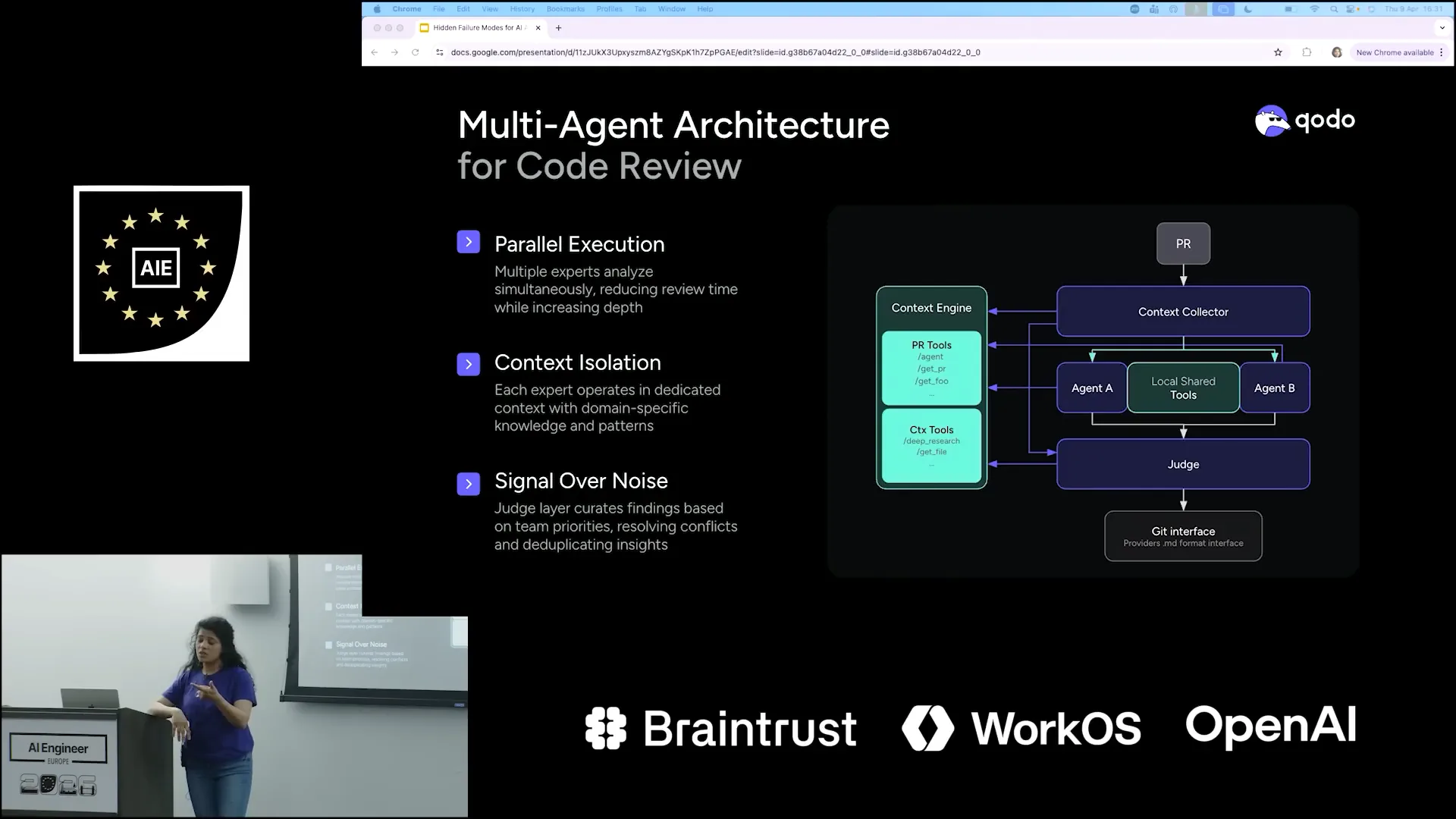
Slide 30 — 14:54 (watch)
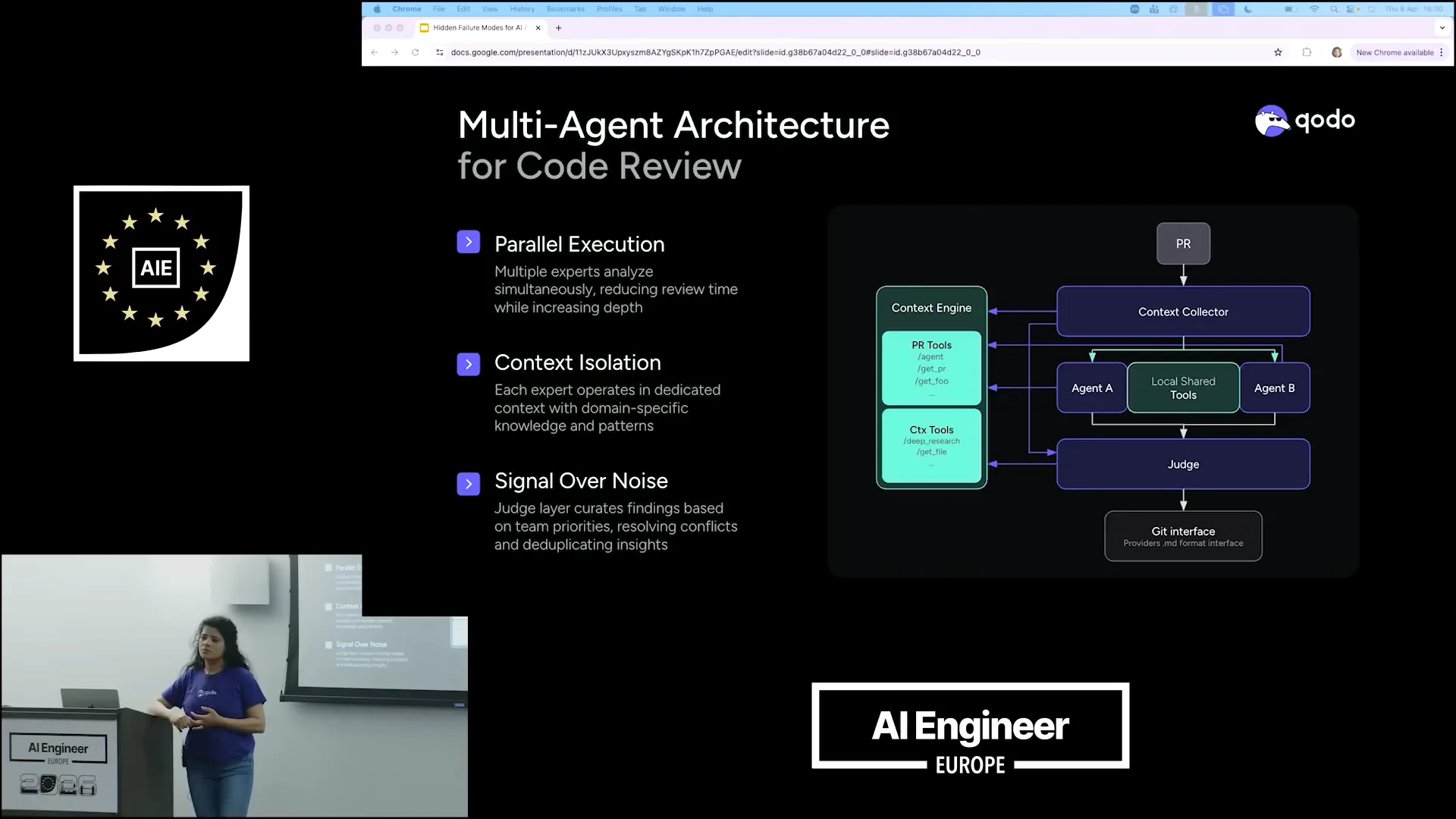
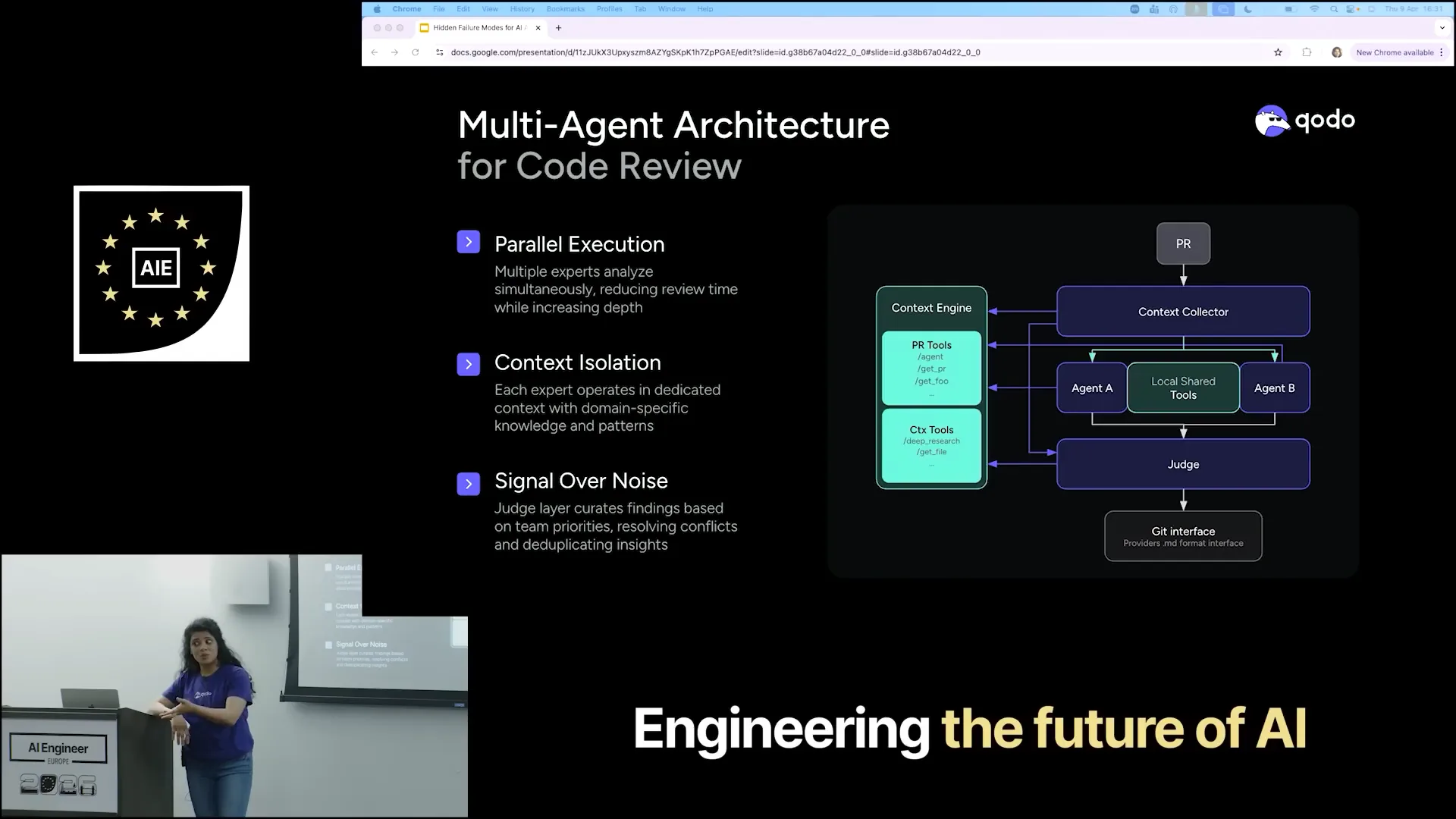
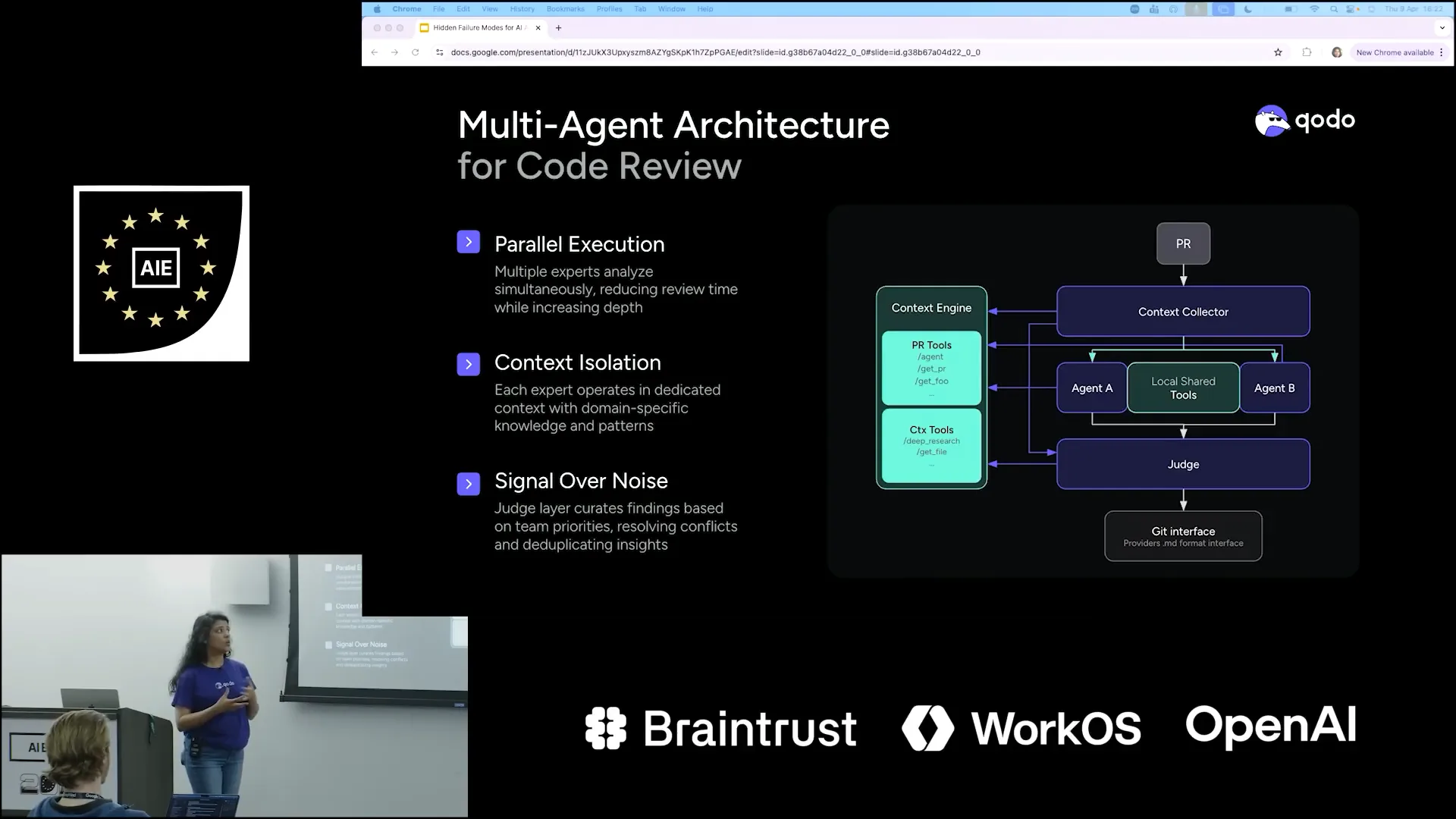 | This is our architecture, Qodo's architecture, where we use the same formula for code reviews. |
Slide 31 — 15:12 (watch)
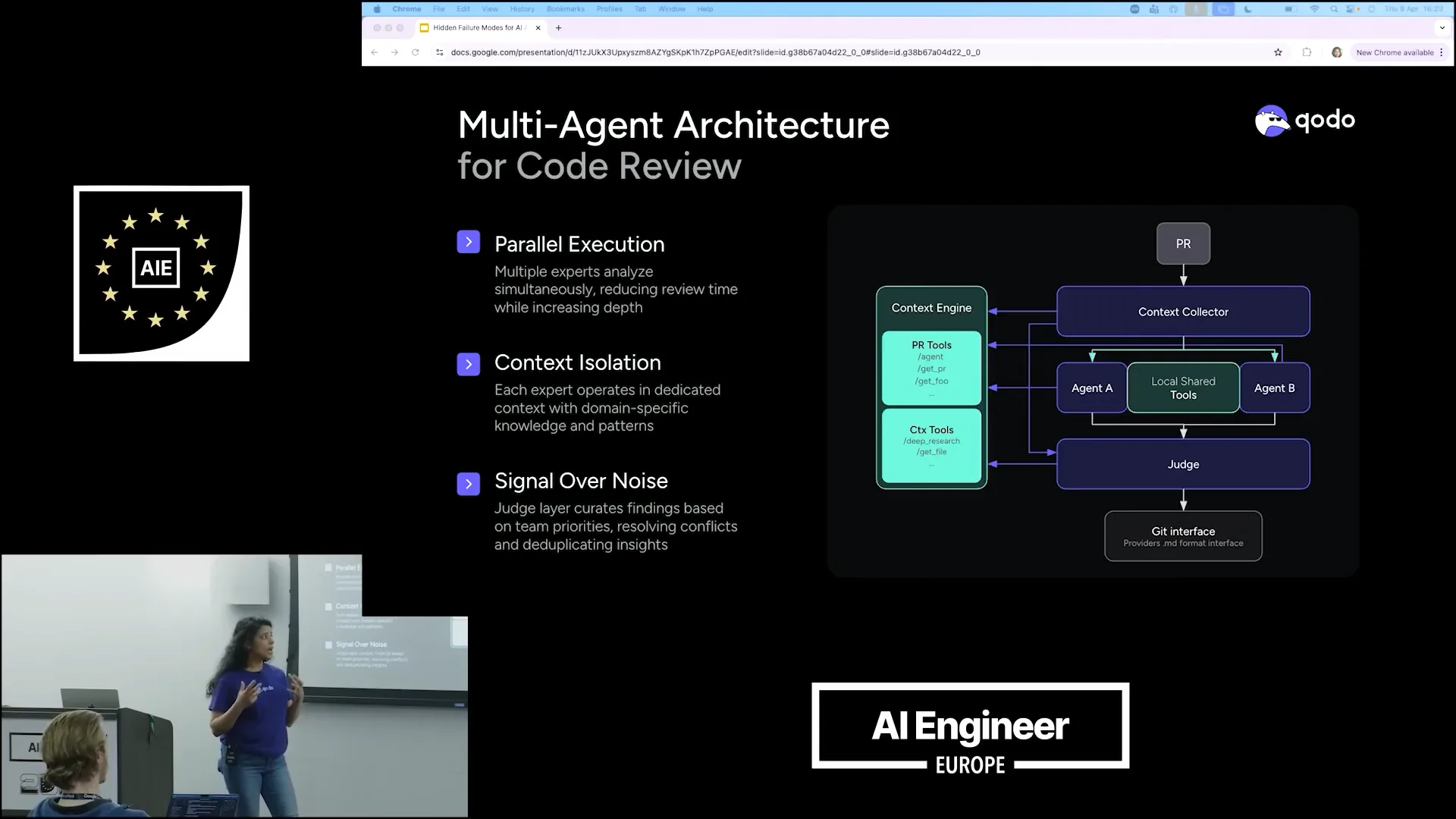 | As part of a PR review, we have a context collector that gathers context from the PRs, the context engine, and various tools. However, it does not immediately begin the review process. Instead, it bifurcates all the collected context and passes it on to different agents. |
Slide 32 — 15:28 (watch)
 | These agents specialize in their designated tasks. For example, one agent focuses on identifying security flaws, another on coding, and yet another on finding Jira issues. |
Slide 33 — 15:44 (watch)
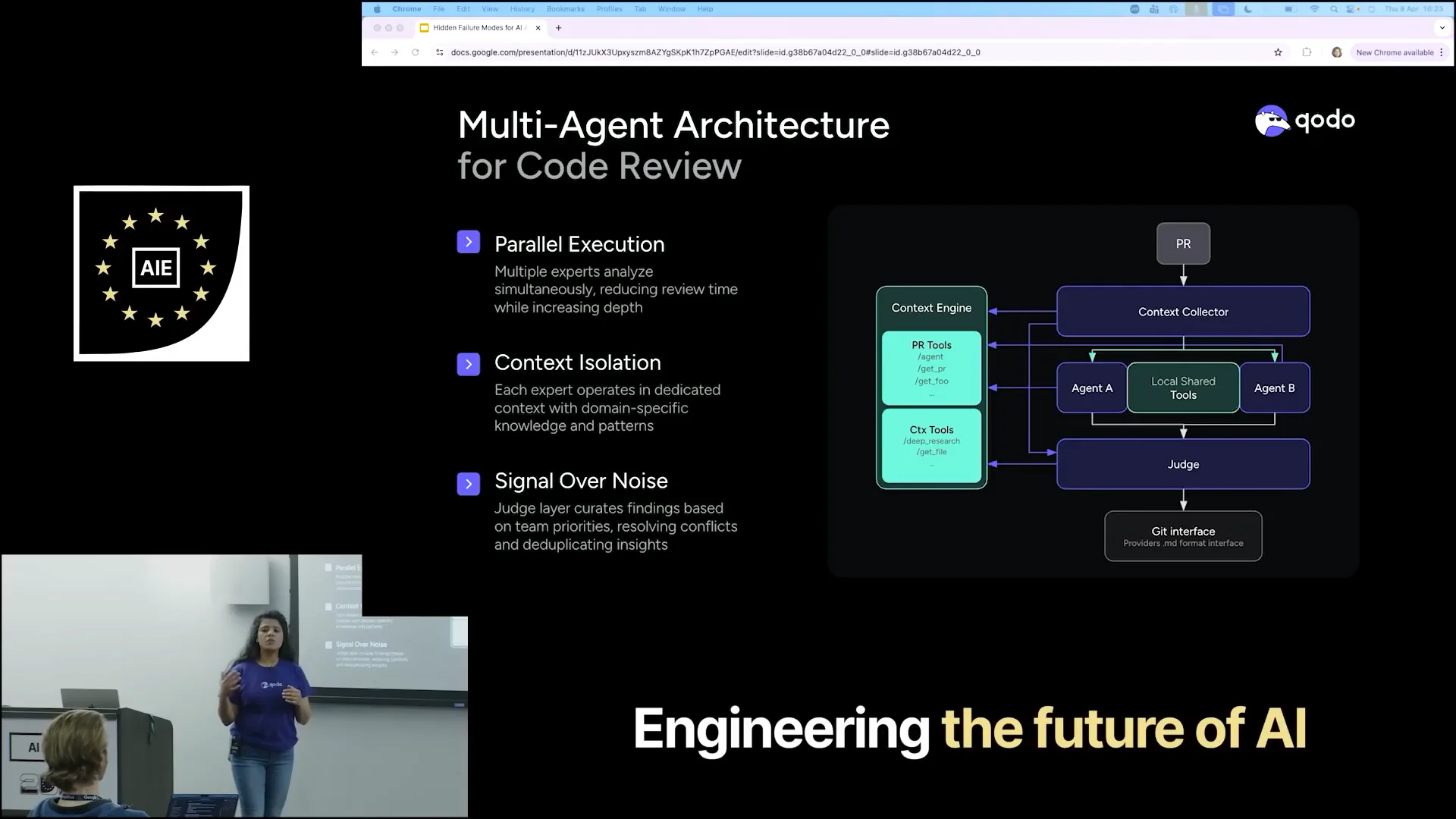 | Once all these agents return their results, a judge agent evaluates them to determine relevance. It assesses which of the provided results are interesting and checks against the context engine, reviewing the pull requests to identify how many of the ten items actually make sense for your needs. |
Slide 34 — 15:56 (watch)
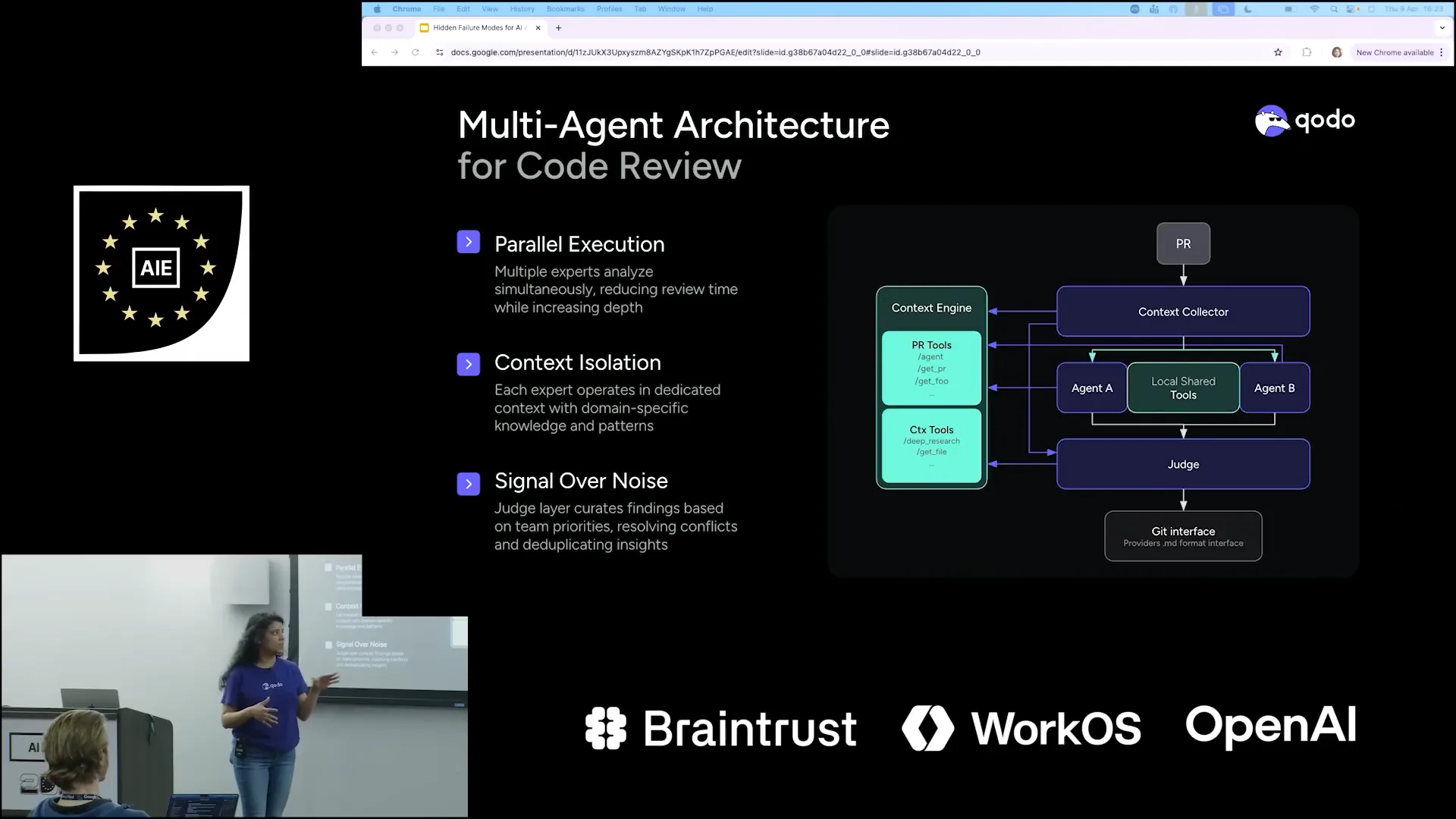 | Refining the results to ensure they are relevant to you. |
Slide 35 — 16:04 (watch)
 | That concludes my presentation. Thank you. |
Slide 36 — 16:14 (watch)
 | Any questions? Yes, how do you enable communication among the swarm? Are you referring to the agents? |
Slide 37 — 19:24 (watch)
 | You have agent A, agent B, and the judge. They communicate through a tool we developed using LangChain, which facilitates interaction and infrastructure for different agents. LangChain collects responses and integrates them into the prompt for the next agent. We aim to gather results and create a refined prompt for the subsequent agent. If there are multiple inputs, we have an agent dedicated to collecting results and enhancing the prompt for the next agent. Regarding calibration, when conducting a code review with an agent, it is essential to establish what constitutes good and bad practices. We perform calibration by assessing the context we have. For instance, when receiving code reviews, the LLM does not inherently know what is significant for your specific workflow. Different industries, such as healthcare, retail, and finance, may utilize the same Java framework in varied ways, with different aspects being crucial for each. To address this, we provide two options for guiding agents on their tasks. First, we index all your pull request (PR) history to identify when similar issues were previously encountered and compare them to the current version. This is done from a contextual standpoint. We analyze the changes made to the code and check for similar instances in the past. This context is transferred twice: once to the sub-agents for their analysis and again to the judge agent. The judge agent evaluates the 15 recommendations for a code review based on historical comments from reviewers and developers, determining which suggestions are worth presenting to your developers. This process is applied to every agent. As you noted, we do not share context between agents; each agent operates with a specific context. We focus on providing only the most relevant information to each agent, utilizing a context engine to filter out unnecessary data. However, this raises a question about bridging gaps between agents. For example, if you have a code quality agent and a specific coding review agent, each operates autonomously with limited information. While this approach works for straightforward tasks like checking for linting or test implementation, it may fall short for more complex architectural decisions that require a broader perspective, such as security considerations. Historically, code reviews involved senior engineers who understood the codebase and could provide insights based on their experience. Security experts would assess potential vulnerabilities, while compliance auditors would ensure adherence to standards like ISO or SOC 2. In the past, specialized knowledge was crucial in these areas. Now, when context is provided, it includes specific security and architectural concerns. We can implement a similar strategy with agents, allowing architects and compliance personnel to input their guidelines, enabling agents to verify compliance with those standards. |
Slide 38 — 22:44 (watch)
 | The context collector has comprehensive knowledge and provides relevant context to the agents. This means you essentially require your customers to upload specific documents. If these documents are not shared, the system will yield significantly different results. |
Slide 39 — 23:02 (watch)
 | Exactly. This requirement varies by organization. Some organizations state that they do not operate under any rules or regulations and prefer an out-of-the-box solution. |
Slide 40 — 23:18 (watch)
 | This also means you shouldn't expect the agents to identify something very specific to your work unless we have a certain pull request (PR) history. The PR history plays a crucial role in determining relevance, even when you don't provide additional context. However, I'm not convinced that PR history is the best source; it can be one of the sources, but not necessarily the only one. |
Slide 41 — 23:34 (watch)
 | There are various sources to consider, such as PR history and your resources. These can be among the sources you use. |
Slide 42 — 23:48 (watch)
 | My question is, how much weight do you assign to each source? Ultimately, you need to make a decision, similar to what a jury does. |
Slide 43 — 25:02 (watch)
 | New documents for engineering and architecture principles can be compared to your version. They may be completely out of balance, depending on various factors. From one perspective, it can be difficult to decide, but obtaining context from multiple angles, such as pull request history, is crucial. When you indicate importance in the compliance portal, it adds weight to the feedback. We categorize feedback into errors and recommendations, which influences its perceived value. Each time a developer accepts a suggestion, it gains weight for future recommendations, while rejected suggestions lose weight. This involves indexing and managing these weights. One method of indexing is tracking whether developers accept recommendations. Another method is analyzing past issues to see if developers implemented suggested changes. For instance, some developers may hard-code their API keys despite being advised against it. This highlights the system’s role in guiding best practices. There are also rules that, when provided, will be highlighted regardless of developer preference. Additionally, if a reviewer agrees that there is an issue and the developer has ignored it multiple times, the reviewer may assign less weight to future feedback. |
Slide 44 — 26:20 (watch)
 | Thank you. |