25 slides extracted.
Slide 1 — 0:18 (watch)
 | Please welcome to the stage Nick Mayhew, product engineer at Metaview. |
Slide 2 — 1:18 (watch)
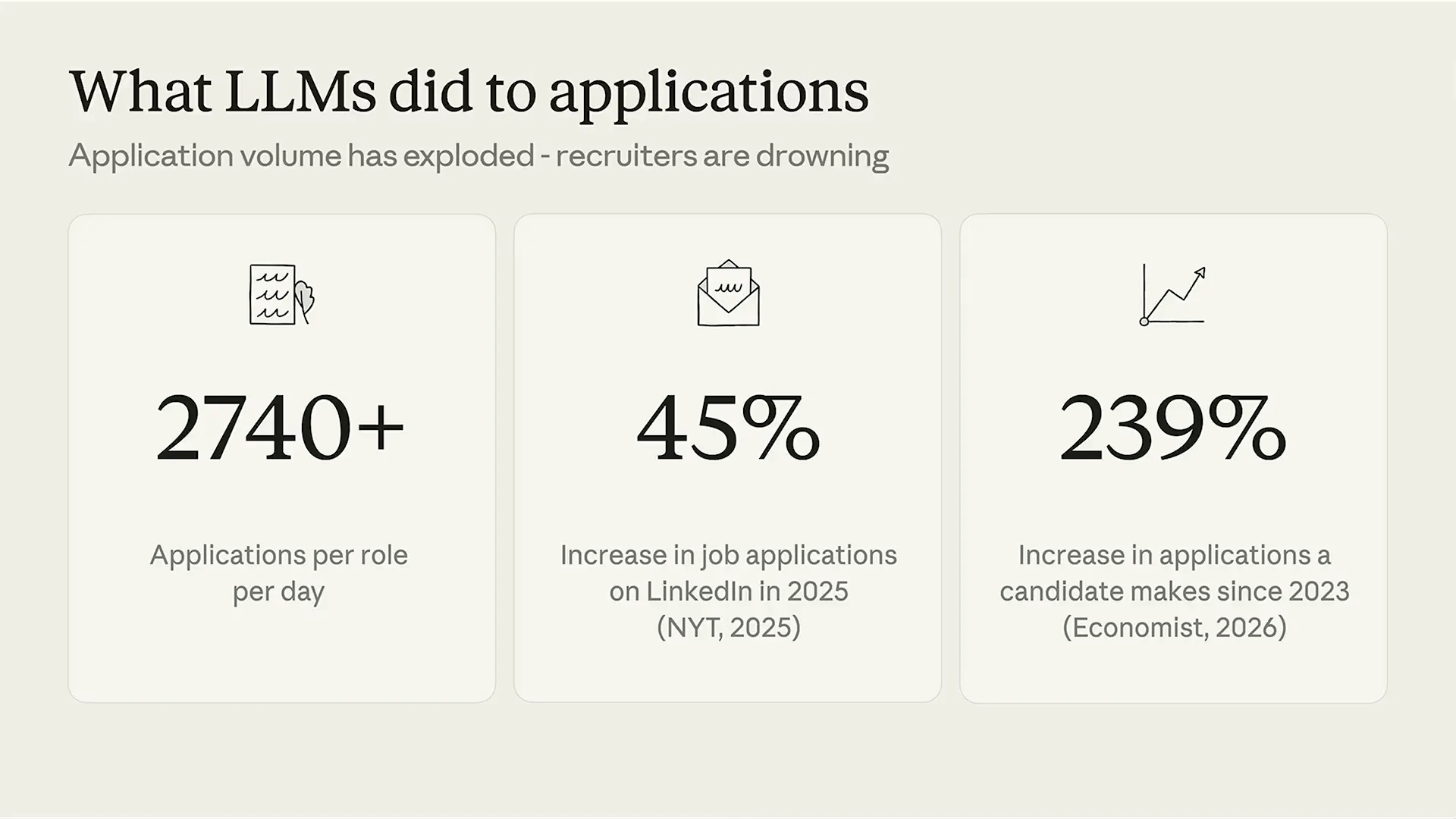 | Good afternoon. It's a pleasure to see you all today. I will discuss how Metaview uses self-improving prompts in application review. For those unfamiliar with Metaview, we build AI-native recruiting software, and application review involves examining candidate CVs and cover letters to determine who to interview. To understand our approach, it’s essential to recognize the current landscape. Since 2023 and the rise of large language models for everyday consumers, we have seen a significant increase in job applications. AI has lowered the barrier to entry for candidates applying for jobs. For example, one of our clients received 2,740 applications for a single job within 24 hours, a trend more common for remote and junior positions. Additionally, the average response to application questions, such as “Why do you want to work at Anthropic?” or “Why do you want to work at Metaview?” has increased by roughly 50% in the last two years. This change is not due to candidates retaking GCSEs and learning verbose writing; rather, it is the result of LLMs assisting them in crafting their answers, which has significantly increased the volume of applications recruiters receive. Given this situation, recruiters need assistance. As a product manager, the first step is to interview stakeholders to develop a system that can help manage the workload of these applications. When speaking with hiring managers or founders, they often list requirements such as five years of back-end experience—criteria that many in this room have seen numerous times on job applications. However, a problem arises almost immediately: when hiring managers review the first set of CVs, they may suddenly express a desire for candidates with start-up experience. |
Slide 3 — 2:34 (watch)
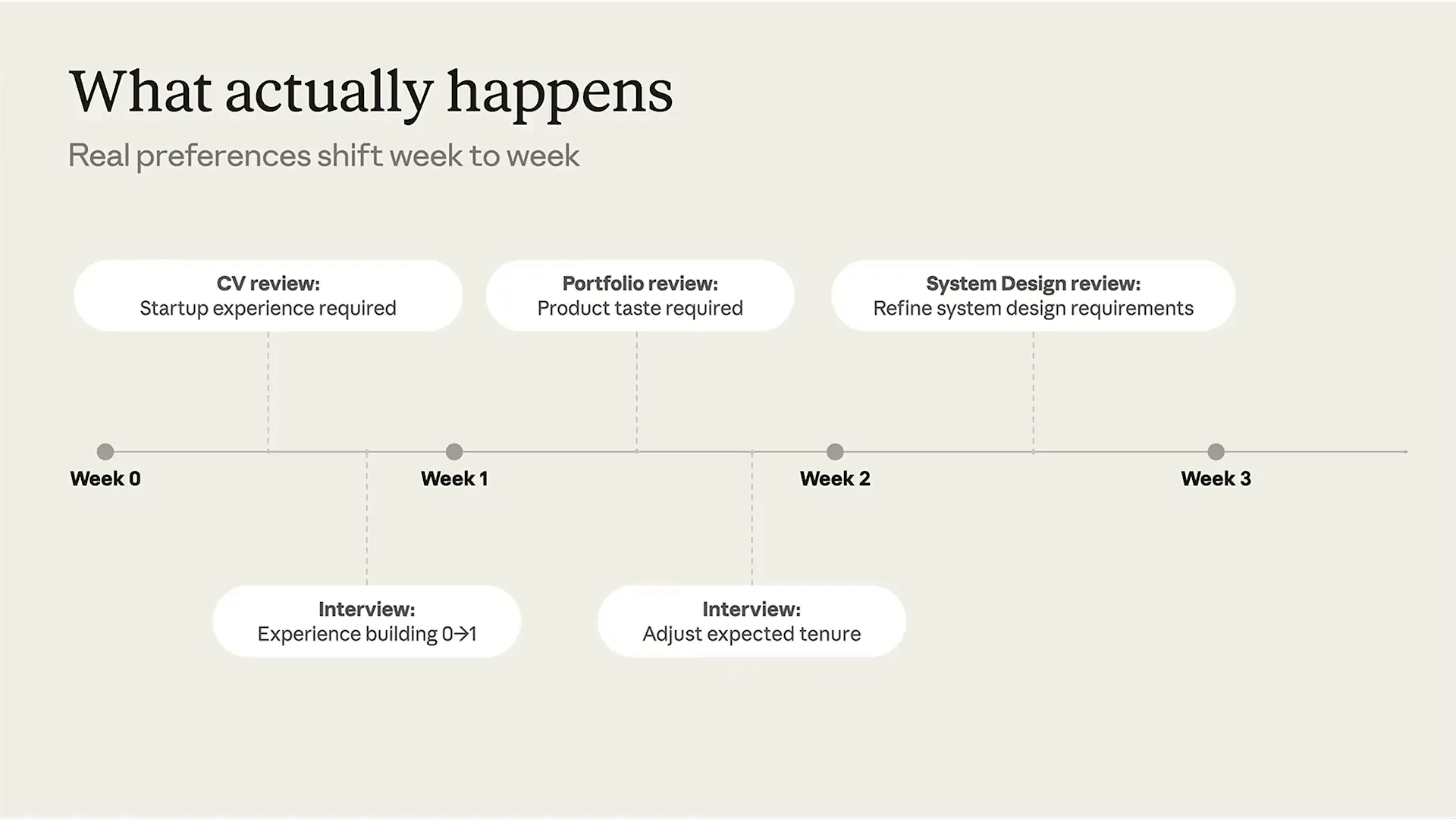 | You go back and rewrite the entire evaluation process. When you reach the first interview, the feedback changes: the interviewer states that the candidate must have zero to one experience, which was not a requirement two days ago. |
Slide 4 — 3:28 (watch)
 | You continuously refine your evaluation systems, and the key takeaway is that any user-based decision, where user judgment is paramount, will see evolving preferences. Therefore, the prompts you create must also evolve. User preferences change, and to keep them at the center of decision-making, your systems must adapt accordingly. Ensure that your prompts reflect this evolution of preferences; do not treat it as an afterthought. Instead, make it a foundational aspect of your system. At MetaView, when a candidate applies, we first redact their information, removing names, emails, phone numbers, and other personally identifiable information. This allows us to evaluate candidates based on experience, skills, and qualifications, matching them with an ideal candidate profile (ICP). The ICP is similar to an ideal customer profile; it outlines what we seek in a role and who we aim to hire. We use the redacted candidate information to generate an evaluation aligned with the ICP. This process is crucial, especially in high-risk areas where human judgment is central. Our system acts as an apprentice, assisting in the evaluation process rather than making final decisions. |
Slide 5 — 4:04 (watch)
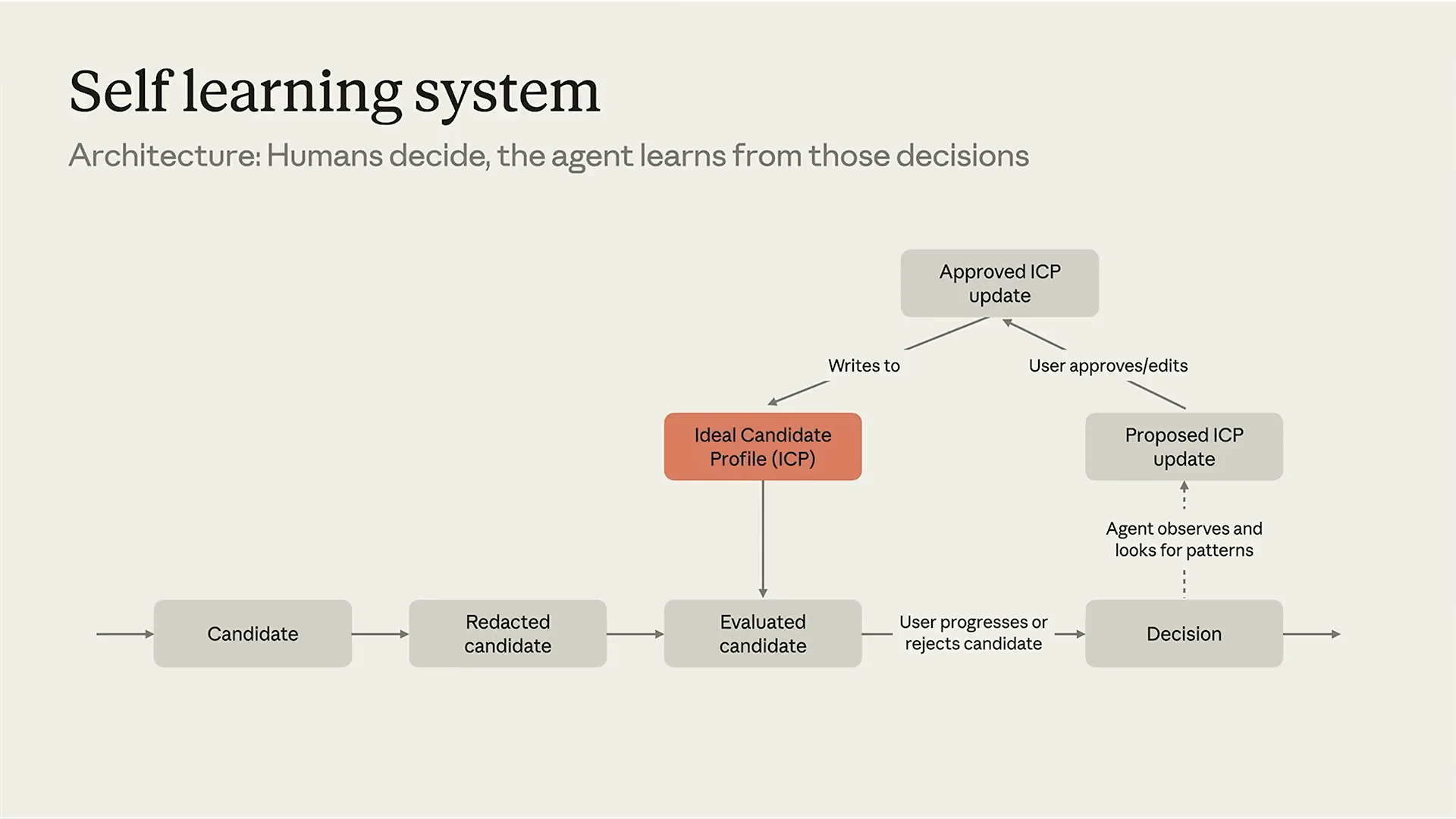 | Your system is designed to learn and assist with the labor-intensive task of reviewing thousands of applications. However, it is not responsible for making decisions. Instead, as an LLM-based system, its role is to aid in identifying key factors, such as whether the applicant has worked at relevant companies, possesses the appropriate experience, and has utilized the right technologies. This is where your judgment is essential, along with the user's judgment, which ultimately determines whether to progress or reject a candidate. |
Slide 6 — 4:46 (watch)
 | They decide whether to progress or reject a candidate, keeping them at the forefront of the process. |
Slide 7 — 5:42 (watch)
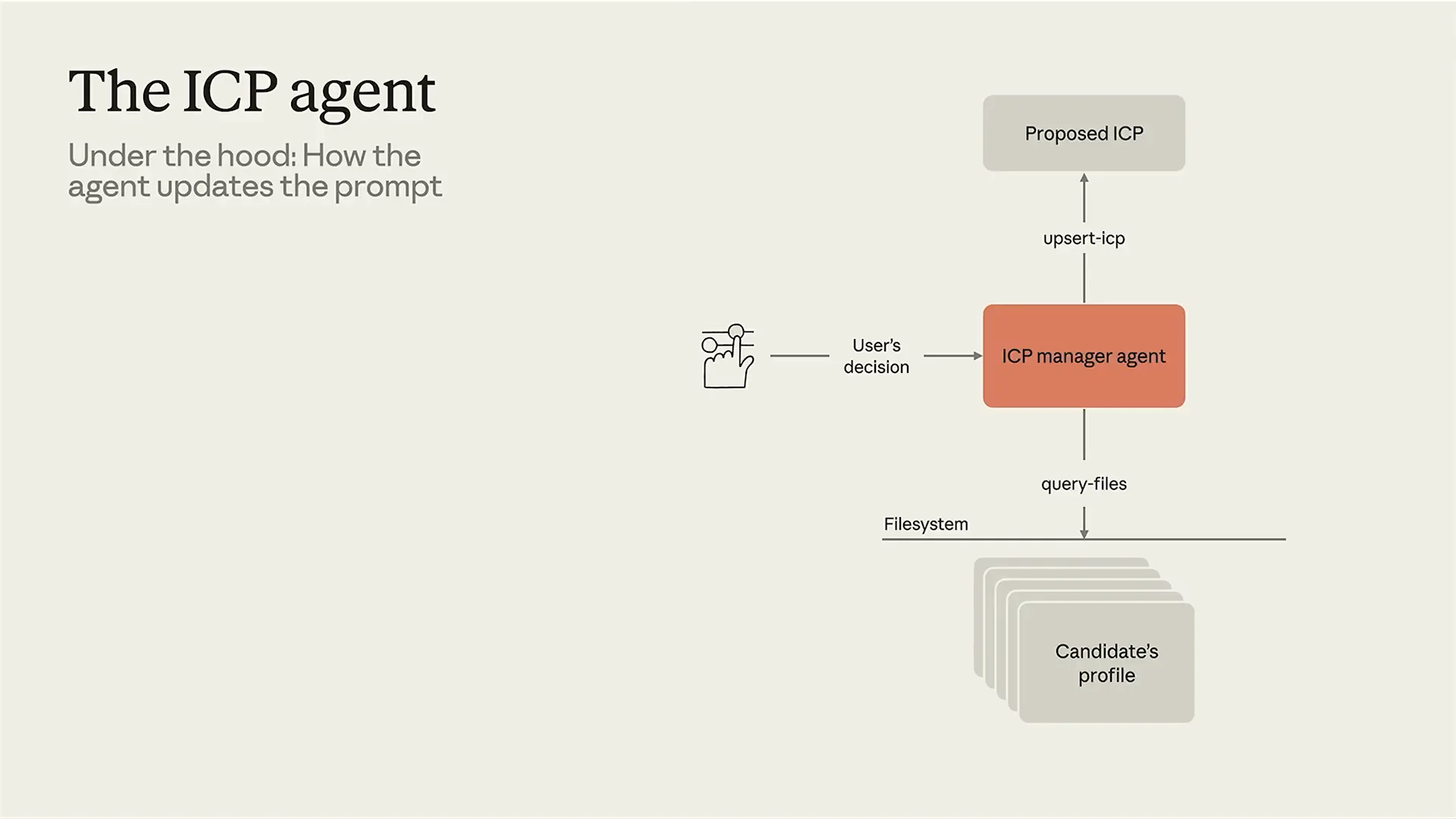 | To learn from user decisions, we can implement an agent that observes their patterns. This agent tracks any progressions or rejections of candidates, allowing us to identify trends and refine the ideal candidate profile. The ideal candidate profile, or ICP, is our self-improving prompt. To understand how this works, let's delve into the ICP agent, which consists of three main components. First, we have user messages, which encompass all user decisions. This includes every time a user progresses or rejects a candidate, any feedback they provide, and any manual edits made to the ideal candidate profile. Initially, we built this system, and while it produced a decent proposed ideal candidate profile, we quickly learned that user feedback is always relative to what they have just seen. Agents require the right context, and here, that context includes the candidates’ redacted profiles. To address this, we developed a specialized tool called query files. Although we initially tried using Bash and standard grep, unstructured data can be challenging to search effectively in a file system. Our tool can analyze candidate profiles and interpret relative feedback. For example, if a recruiter states that a candidate lacks sufficient Python experience, we can reference the past redacted resume to clarify what “too little Python” actually means. |
Slide 8 — 7:20 (watch)
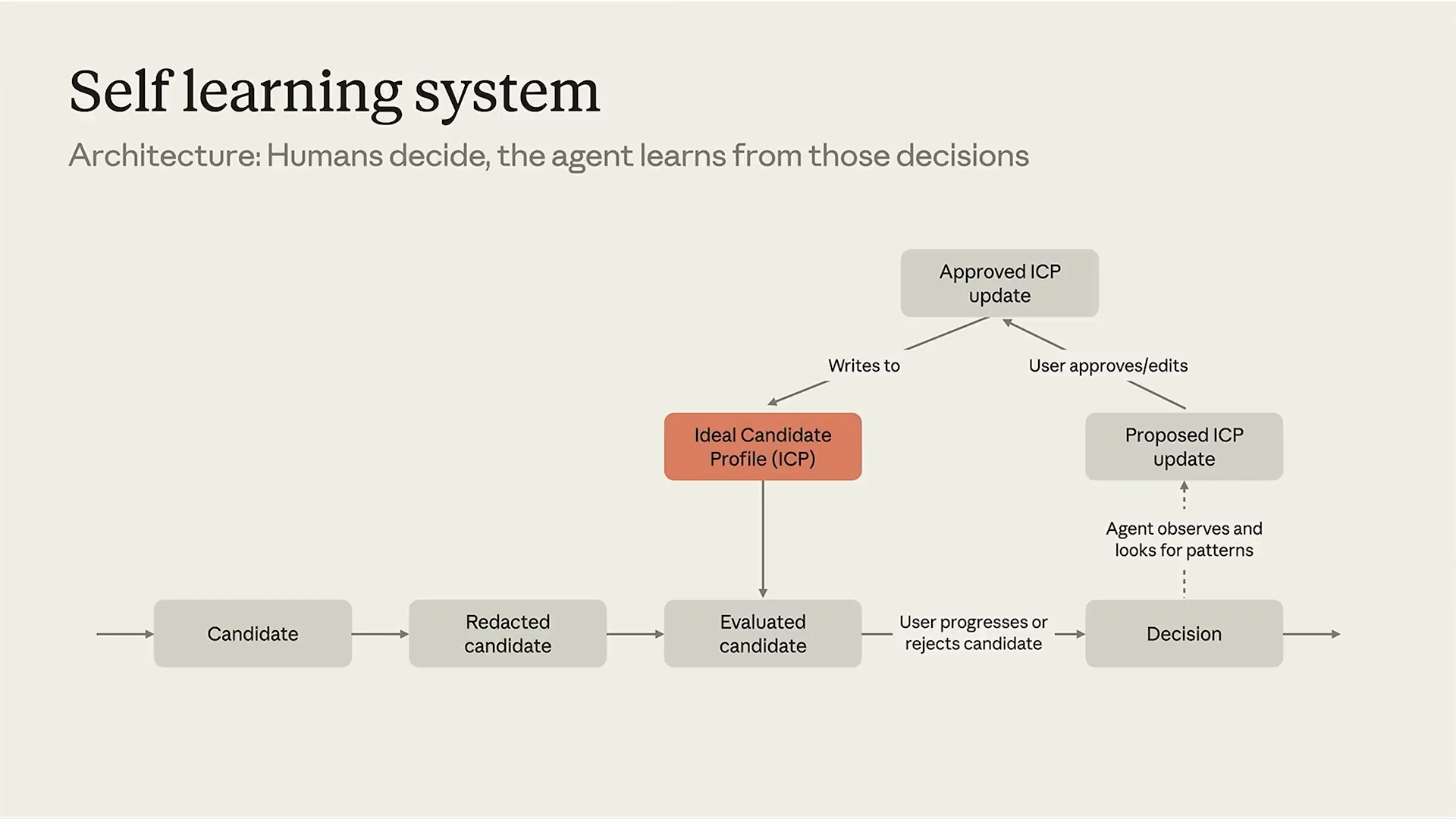 | What does it mean to be too junior? We can build that context, which feeds into the Ideal Candidate Profile (ICP) manager agent. This agent has one primary function: to keep the ideal candidate profile prompt up to date and monitor what candidates are being evaluated. This is the core of the system. Recently, we’ve had discussions suggesting that this entire process could be streamlined into a single agent. However, I want to explain why we maintain a workflow with an agent on top. When processing thousands of applications daily, we cannot afford to submit everything to a single agent. While it would be appealing for developers to create a maximal agent, there are business considerations. Companies like Anthropic or Google receive hundreds of thousands, if not millions, of applications each year. They require a system that efficiently manages token usage, which is why we have a workflow in place, supported by an agent to evaluate progressions and rejections. So, what does an ideal candidate profile actually look like? This is something we should all understand by now. It consists of marked-down documents. We do not use weightings, if statements, or flow charts. There has been valid criticism of relying on keyword matching in resumes to determine what constitutes a good resume. This approach does not effectively evaluate a person or candidate, and we do not advocate for such systems. Instead, we should leverage what LLMs excel at: natural language processing. |
Slide 9 — 8:26 (watch)
 | Allow candidates to reason in prose rather than flowcharts. Here, you can see an example in our demo of what an ideal candidate profile looks like. It is simply a text document that describes who you're looking for, rather than specifying that 30% of the weighting should be on certain keywords. Allow users to express their needs in natural language, and the system will better reflect their priorities. Candidates do not think in terms of weightings, flowcharts, or if statements; they describe their qualifications in normal language. Therefore, we should leverage their strengths. Since we are at an Anthropic talk, it's worth noting that we frequently use Anthropic models for this purpose. |
Slide 10 — 9:02 (watch)
 | One of the reasons we use Claude models is that we face an interesting dilemma in candidate review. While benchmarks on software evaluation are useful, our primary concern is whether we can analyze a resume and discern what is genuine and what is not. |
Slide 11 — 9:32 (watch)
 | One of the biggest problems with evaluating CVs is the presence of excessive fluff. Many candidates claim to have accomplished more than they actually have. If you use a model from other frontier labs, it may take these claims at face value, leading to inaccurate assessments. For example, it might conclude that someone successfully created a large language model in their garage without further scrutiny. To address this, we need a model that can reason critically, which is why we use Haiku and Sonnet. Haiku is employed for our evaluations, processing thousands of applications daily with specific input token limits. Sonnet is used for its ability to identify patterns in less constrained tasks, where latency is less of a concern. |
Slide 12 — 9:56 (watch)
 | We apply additional intelligence to identify patterns, moving beyond the constrained task of defining an ideal candidate profile and evaluating resumes. Now, let's explore what this looks like on the screen. |
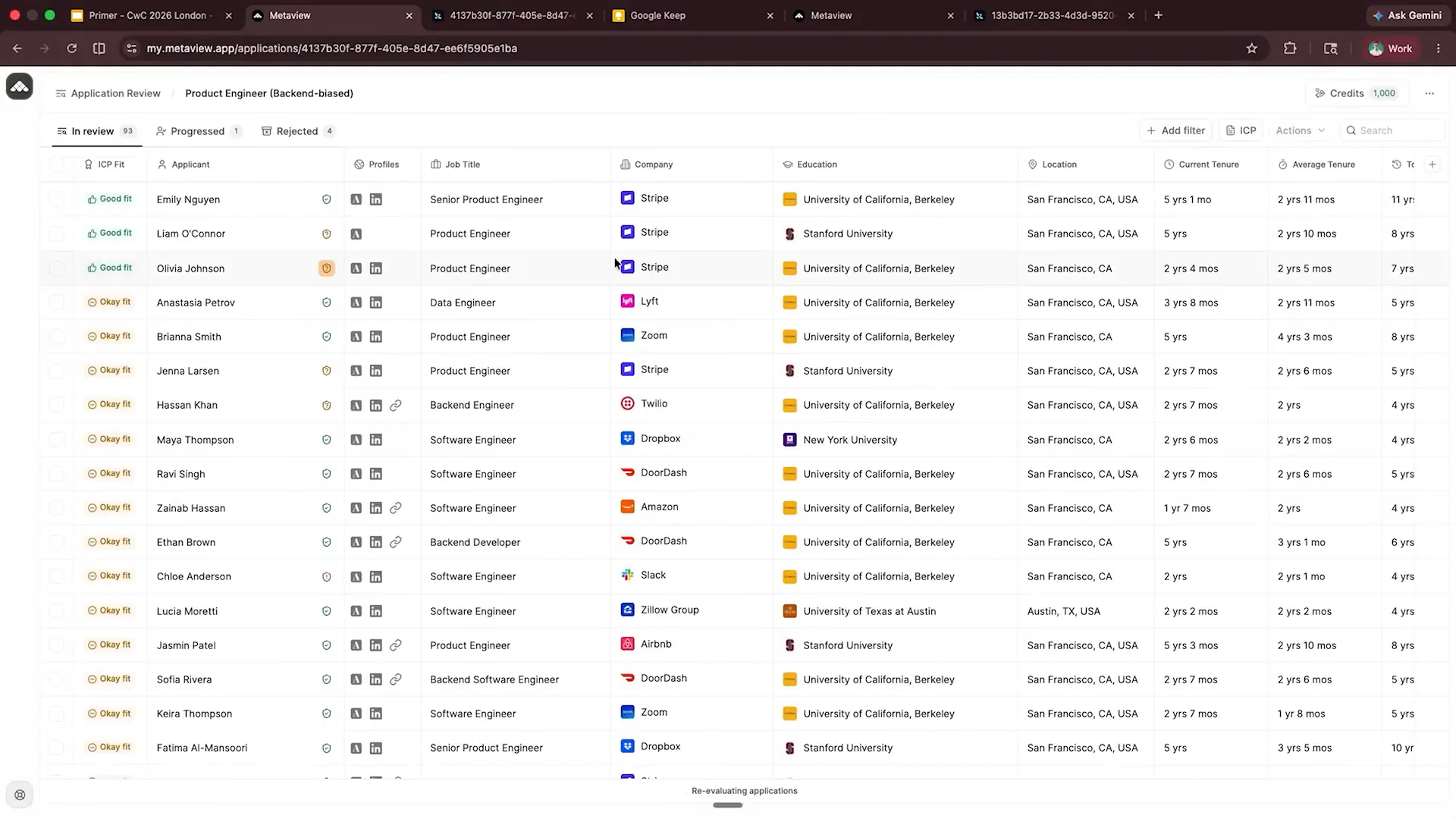
Slide 13 — 10:26 (watch)
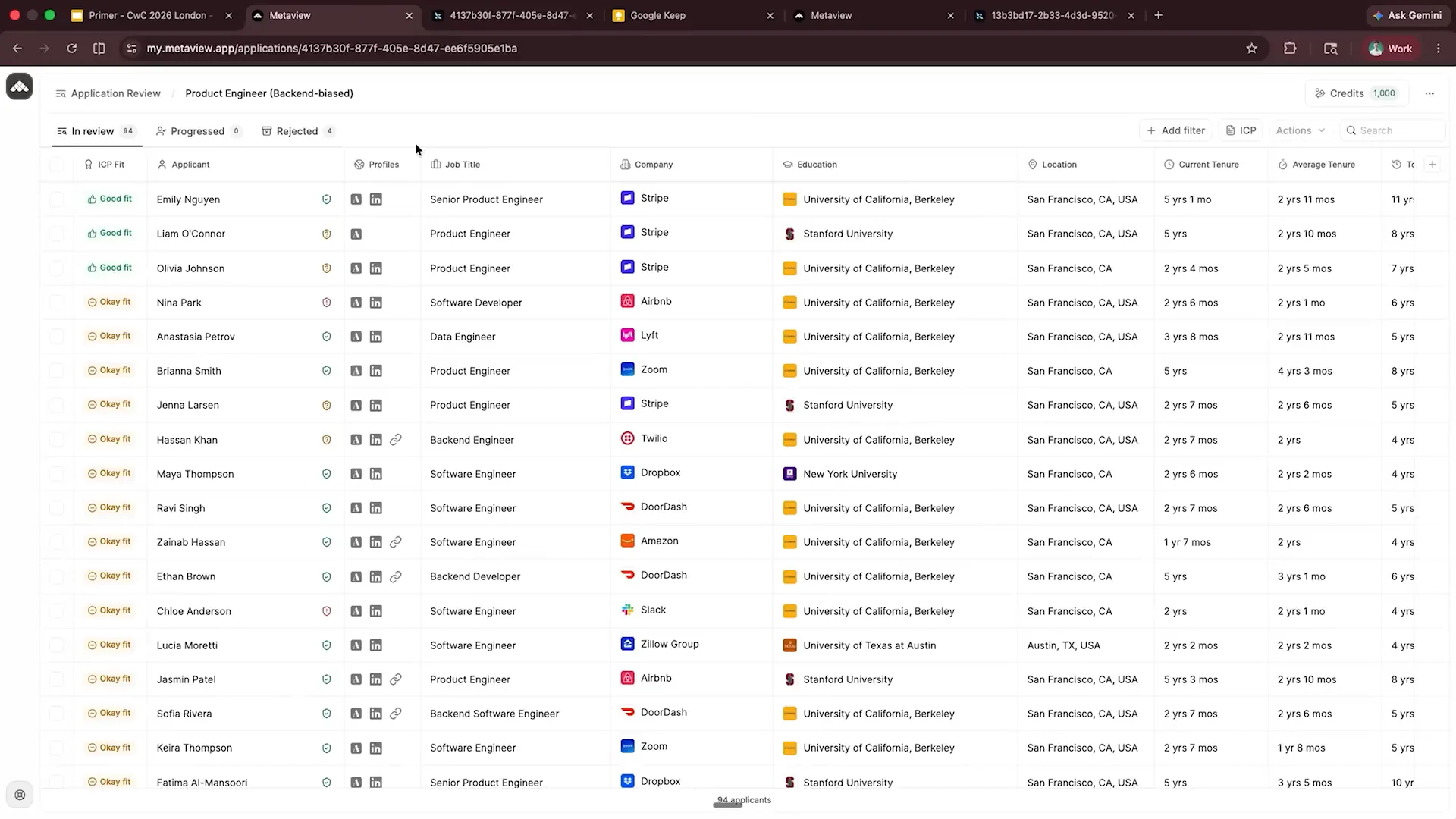 | Here we have the product engineer backend bias displayed. This is all dummy data, and as part of my role at Metaview, I know what I'm looking for. We can see several candidates listed along with their Ideal Candidate Profile (ICP) fit, indicating how well they match the profile. Candidates like Emily and Nina are good fits, while others are considered okay fits. This gives us a clear view of what an ideal candidate profile looks like. |
Slide 14 — 10:52 (watch)
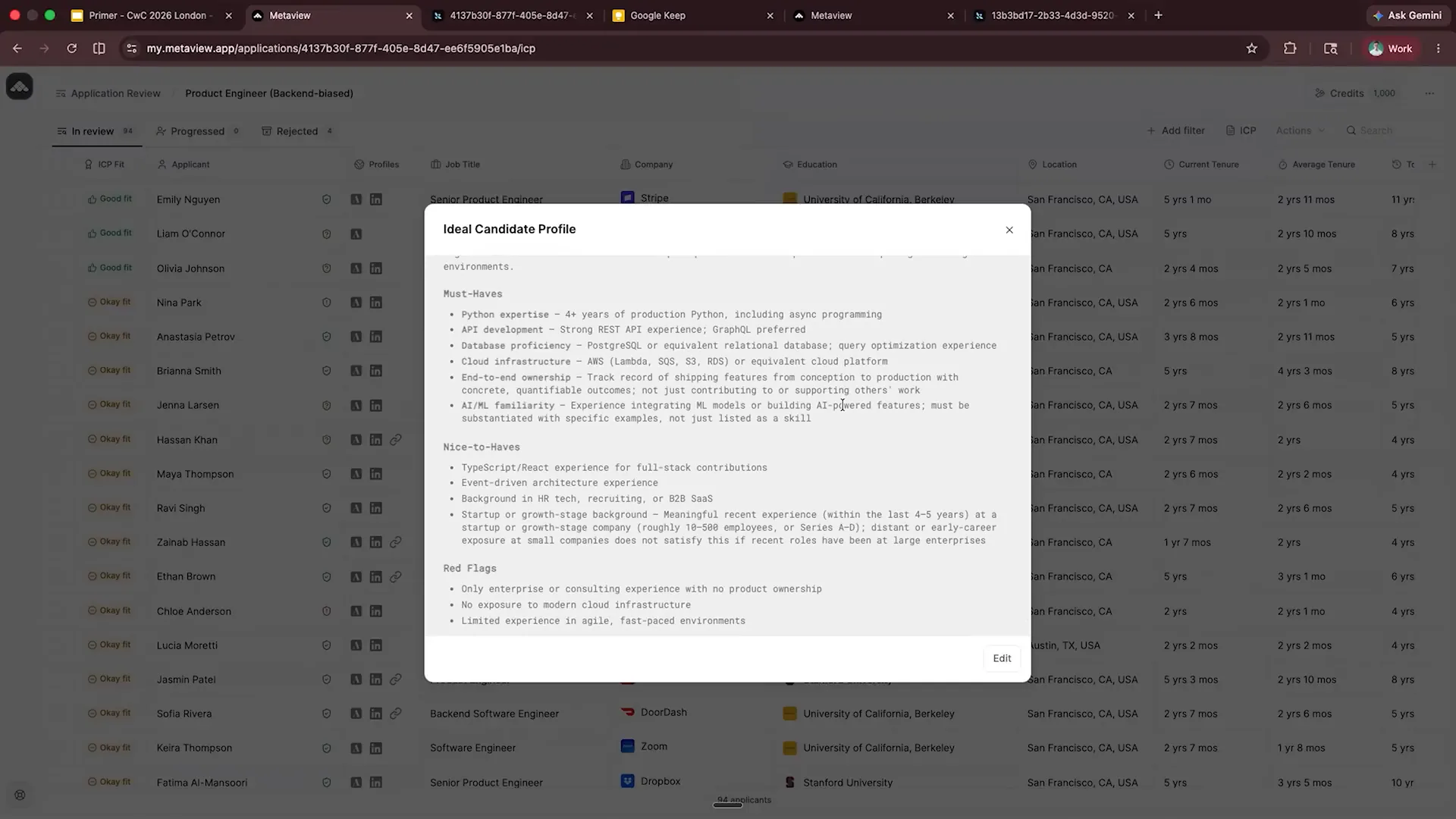 | This slide provides a role summary to give the agent the necessary context for evaluation. It includes must-haves, nice-to-haves, and red flags. We phrase it this way because many recruiters think in these terms, and we aim to reflect their practices. We utilize the same language and criteria found in their systems. For instance, upon reviewing the information, it appears that Nina is a strong candidate. |
Slide 15 — 11:22 (watch)
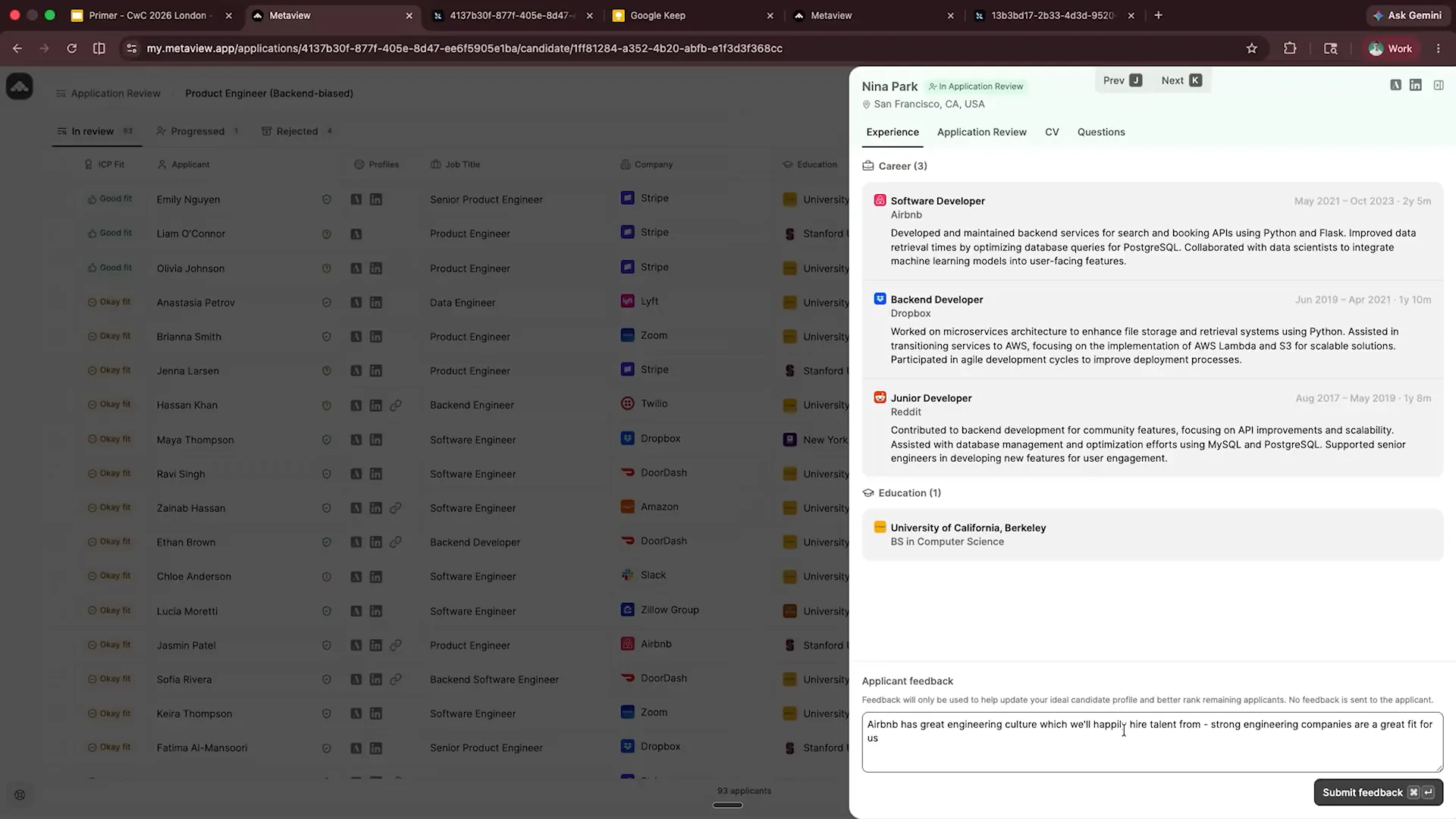 | Why is she just an okay fit? Let's consider that Airbnb candidates typically have great experience. We will progress this candidate and provide feedback. I’m copying and pasting here, noting that Airbnb has a strong engineering culture and is happy to hire talent from reputable engineering companies. Therefore, candidates from such backgrounds should not be just an okay fit for us. I submit this feedback and now switch over, hoping the LLM will perform as expected. |
Slide 16 — 12:02 (watch)
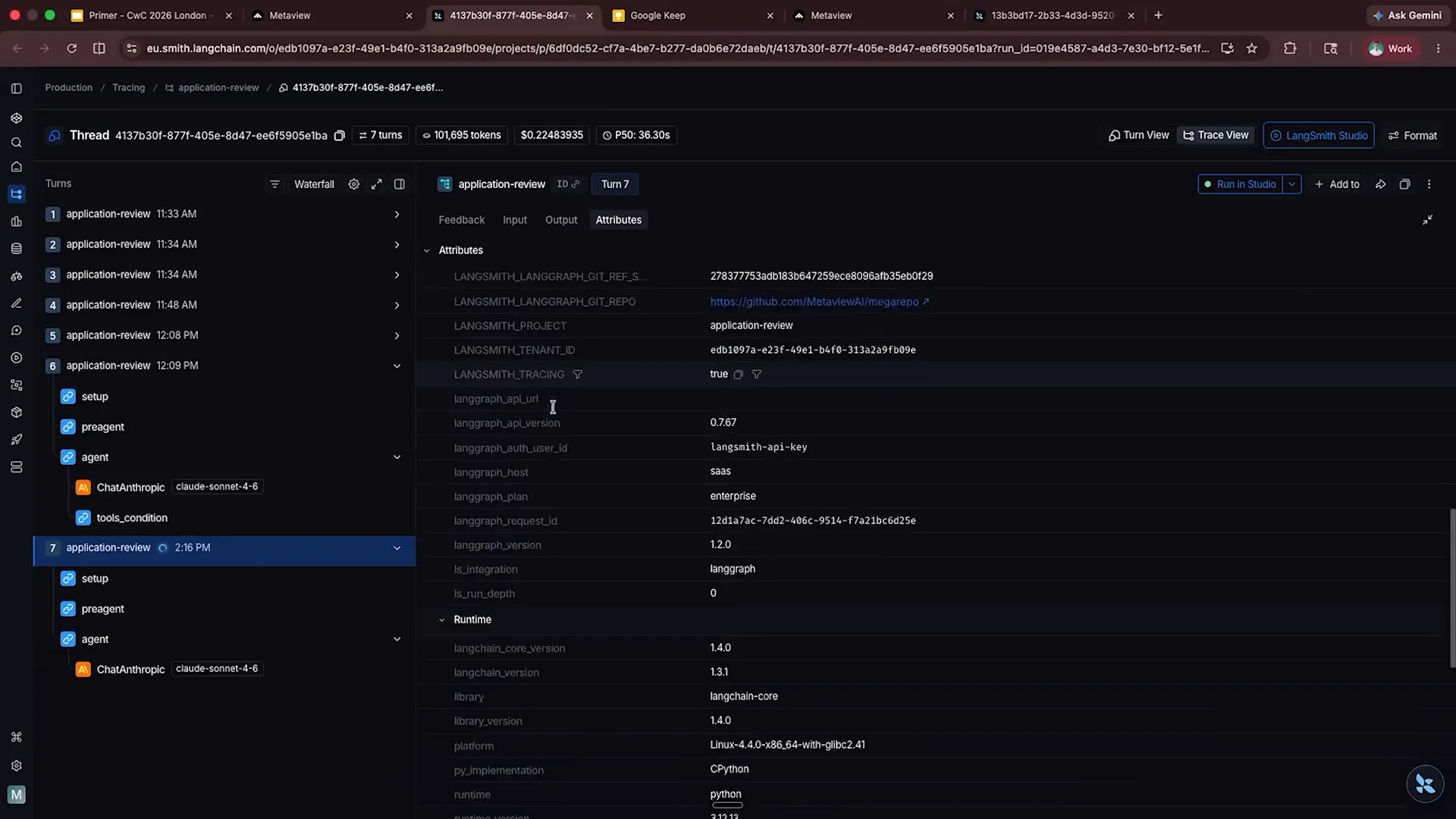 | This is LangChain, where we currently deploy our agents. We are having some discussions with our Anthropic representatives regarding managed agents, but I believe they will persuade me eventually. Here, we see that SONNET 4.6 has been called. Let's take a look at the input. This will take a moment. We can observe the user messages, and there was some testing earlier today. If I scroll down to the bottom, we see that Nina Park has progressed, along with the overall feedback and additional information on what we are looking for. I may need to refresh because LangChain streaming is not perfect. |
Slide 17 — 12:50 (watch)
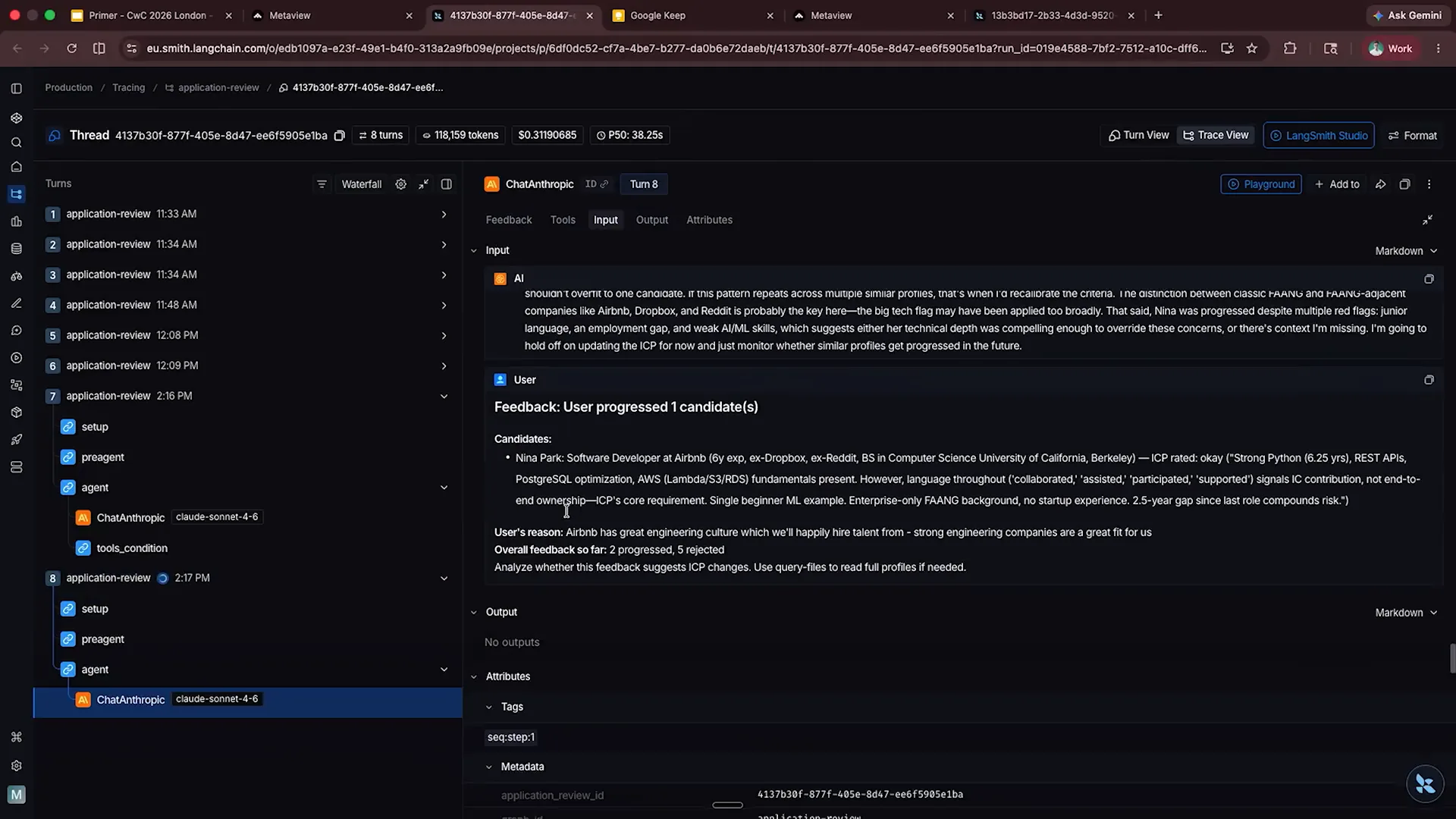 | This is the challenging part of any live demo: hoping that the system responds within the expected time frame. The process is running again, and we can see the user reason that has been submitted. We have overall feedback and additional information for the agent. The agent will then output the tasks it intends to perform and the tools it plans to use. We are currently waiting on SONNET, so I will return to that shortly and look at another example where we already have a suggestion. Here’s our sales associate role, which contains dummy data. |
Slide 18 — 13:26 (watch)
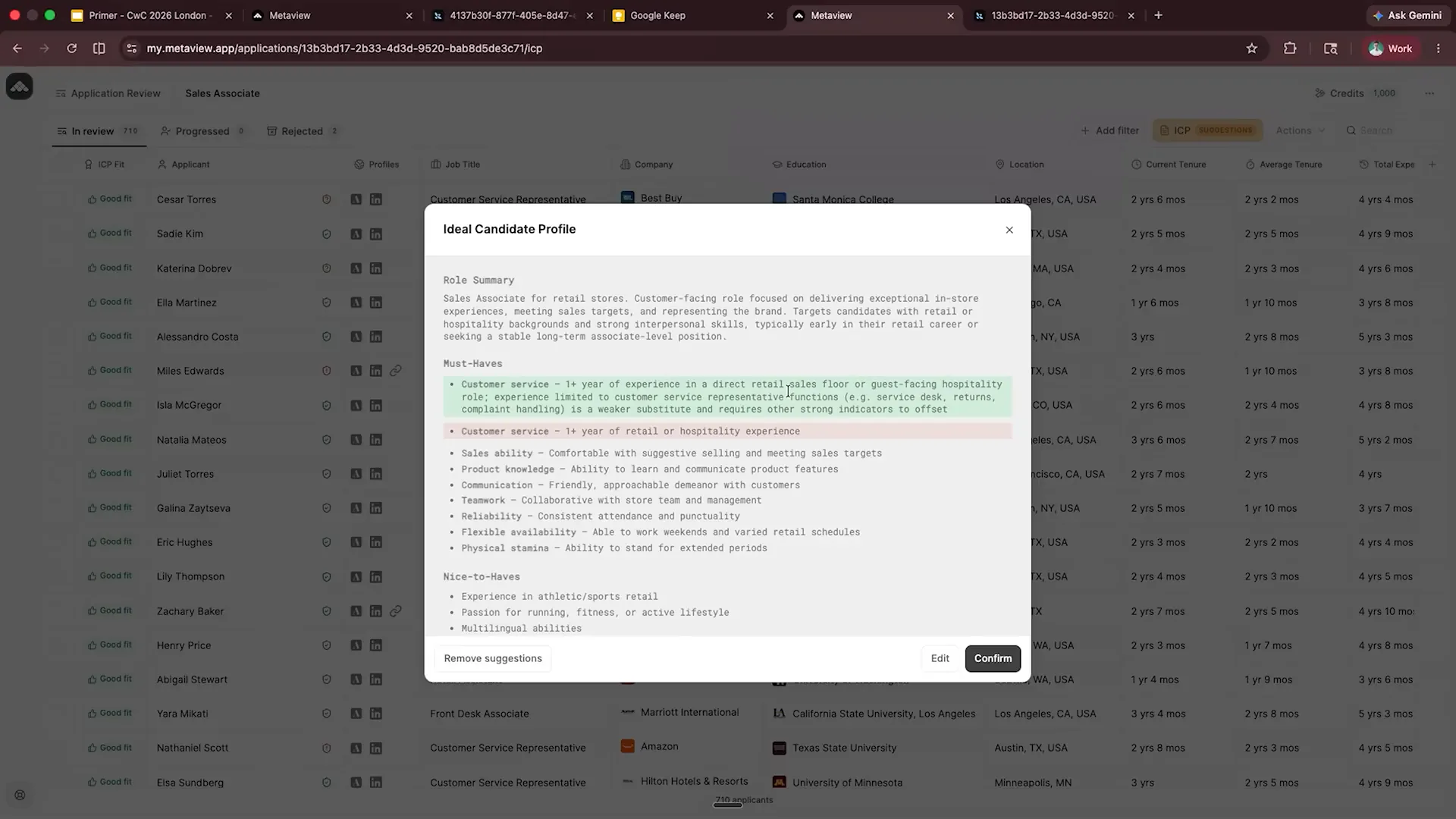 | Based on the feedback we've received, we've updated the Ideal Customer Profile (ICP). This new ICP reflects the changes made in response to user input. The green and red diffs illustrate that the agent has learned from our decisions. We can confirm or edit these changes ourselves, but let's preview and confirm them before re-evaluating the candidates. |
Slide 19 — 13:48 (watch)
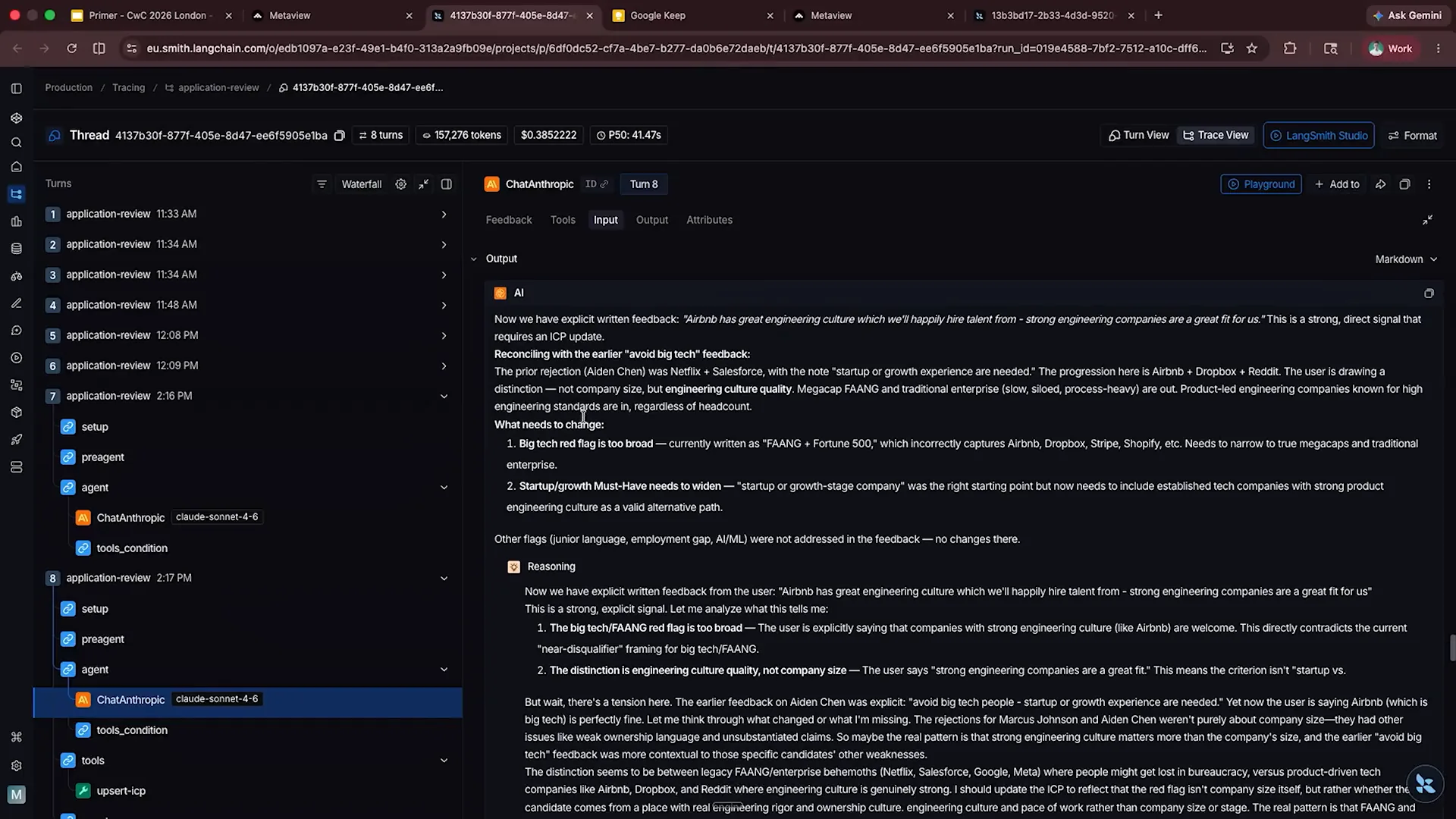 | Claude has responded with explicit written feedback, asking what to do next. It has provided its reasoning and decided to call the upsert ICP tool, which will update its ICP. If we return to the previous view, we will see this suggestion along with some changes. |
Slide 20 — 14:16 (watch)
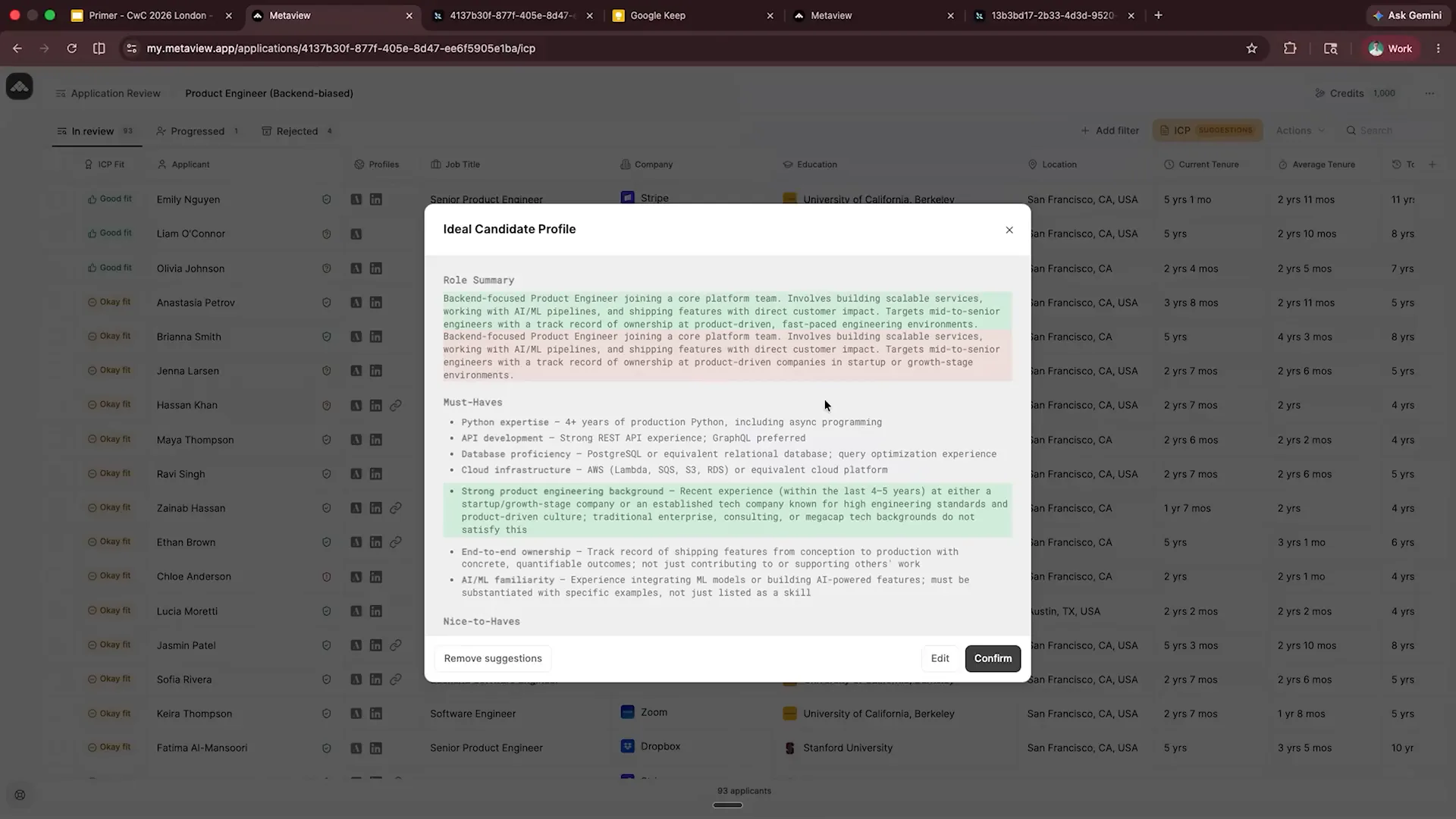 | The tool has made a significant change, particularly in emphasizing the need for strong product engineering backgrounds. As this process is scaled and executed quickly, it begins to learn from emerging patterns. This example is somewhat contrived; in practice, updating the Ideal Candidate Profile (ICP) cannot rely on a single piece of feedback. Instead, patterns typically emerge after analyzing around 100 to 200 pieces of feedback. This approach enables effective scaling and refinement of the ideal candidate profile, ensuring that re-evaluations accurately identify which candidates are the right fit and which are not. |
Slide 21 — 14:38 (watch)
 | I will begin by discussing the three main takeaways from this talk. While it might be entertaining to watch a re-evaluation of candidates using Haiku and LLMs, I will focus on the key points presented in the slides. |
Slide 22 — 15:28 (watch)
 | The first takeaway is that any evaluation system centered on user judgment must account for the evolution of user preferences. It is common to see systems designed with fixed requirements, assuming nothing will change. However, if you want users to be at the center of decision-making, you must recognize that their preferences will evolve. Incorporate this understanding into the foundation of your system rather than trying to add it later as an afterthought. The second takeaway is to use prose, not rules. Many presentations today have emphasized the importance of leveraging markdown language and allowing the agent to perform optimally. Embrace how users write and how the LLM generates text. Avoid reverting to flowcharts and if statements, despite the temptation stemming from our experiences in pre-LLM environments. The final takeaway, which is crucial, is to build guardrails into the architecture. Evaluation systems are increasingly integrated into our daily workflows, with LLMs being deployed in various contexts, from code reviews to financial crime detection and KYC processes. Attempting to add guardrails ad hoc at the end will not be effective; instead, design your system from the outset to learn from the user. |
Slide 23 — 16:14 (watch)
 | These systems are being implemented and utilized, but if you try to add guardrails ad hoc, it won't be effective. Instead, design your system from the beginning to be an apprentice that learns from the user, while never overruling them. |
Slide 24 — 16:26 (watch)
 | Make the user the master and the system the apprentice. Thank you for listening today. |
Slide 25 — 16:36 (watch)
 | Thank you very much. |