151 slides extracted.
Slide 1 — 0:16 (watch)
 | Can everyone hear me? Excellent. My name is Frank McSherry from Materialize, and today’s presentation is titled "Building Confidence in an Always-in-Motion Distributed Streaming System." When I initially typed the title, I wasn't thinking too deeply about it, but I've come to appreciate it. It effectively captures the essence of the topic, particularly the importance of the gerund form. This talk will focus on what building confidence means to me and, hopefully, to all of you. Importantly, building confidence is a process, not a product. You are never truly finished building confidence in something. |
Slide 2 — 1:54 (watch)
 | Building confidence is an ongoing process, not a finished product. It involves various elements that help you and those around you understand and evolve the work you're doing. I want to emphasize that what I share today is largely a collection of opinions, mixed with some technology discussions. You have the freedom to judge, assess, and reflect on whether you find these ideas exciting. Each talk today has been a personal journey, showcasing individual conclusions and paths. Take what resonates with you and leave what doesn’t, but I encourage you to consider these ideas thoughtfully rather than dismissing them outright. I also mentioned to Gary in the elevator that I have some strong opinions, which I decided not to include in the slides to avoid controversy. However, I can share that my organization has gained significant benefits from neurosymbolic AI. While I won’t delve too deeply into that, I believe that the processes I’ve found helpful for building confidence align well with the recent advancements in AI tools. These tools often focus on downstream applications rather than confidence building itself. If you get the confidence-building aspect right, it can lead to effective implementations. Now, let me share a bit about my background. I have experience with timely differential data flow, which involves distributed, scalable, data-parallel systems that can be complex and confusing. I’ll primarily discuss these systems today, using Materialize as a case study to explore what building confidence might look like in this context. Materialize has some unique and interesting features that I will highlight as we proceed. |
Slide 3 — 3:48 (watch)
 | Materialize is an intriguing system that I hope will inspire you to see its unique aspects. It operates in a nonstandard way, particularly through incremental view maintenance using SQL. This means it keeps your queries continually updated with sub-second freshness as your data changes. The challenges in this area of distributed systems are significant, especially considering the scale of data involved. Materialize has about a petabyte of deployed capacity, with data that is live and constantly changing, meaning any record could be updated at any moment. That said, I want to acknowledge my own limitations as a programmer. While I manage to get by, my skills are not exceptional. For instance, I don’t know how to use a debugger and I don’t particularly enjoy writing tests. However, it’s important to note that the team at Materialize includes many talented individuals who excel in these areas. |
Slide 4 — 5:58 (watch)
 | I want to emphasize that at Materialize, we have many talented individuals who excel in areas where I may not. So, there's no need to worry about the potential pitfalls of our system. Confidence in a system doesn't solely stem from having a single skilled programmer; while that may provide temporary assurance, it's not a solid foundation for broader trust. To set the stage, we’ll begin with a demo of Materialize to establish context and vocabulary. I’ll outline three key points about building confidence, which will be marked with chili pepper emojis for easy identification. Materialize serves as a component in data infrastructure that mirrors data from upstream source databases, such as PostgreSQL, SQL Server, and MySQL, as well as from Kafka. It utilizes change data capture to bring this data into Materialize and propagate any changes through the SQL you write. This allows for integration of data from various sources, like joining dimension tables from PostgreSQL with fact tables from Kafka. The results are continuously up-to-date, targeting subsecond freshness, although this can vary based on the SQL you write. While we strive for optimal performance, we cannot correct poorly written SQL. However, every result from Materialize reflects the correct answer at a specific moment in time. If you have preferences for that moment, Materialize offers strict serializability by default, ensuring that you cannot achieve anything weaker than serializable isolation. The system uses standard SQL, making it accessible for users who may not want to engage with the complexities of distributed or streaming systems, yet still desire the benefits they provide. Now, let’s move on to the demo. |
Slide 5 — 8:06 (watch)
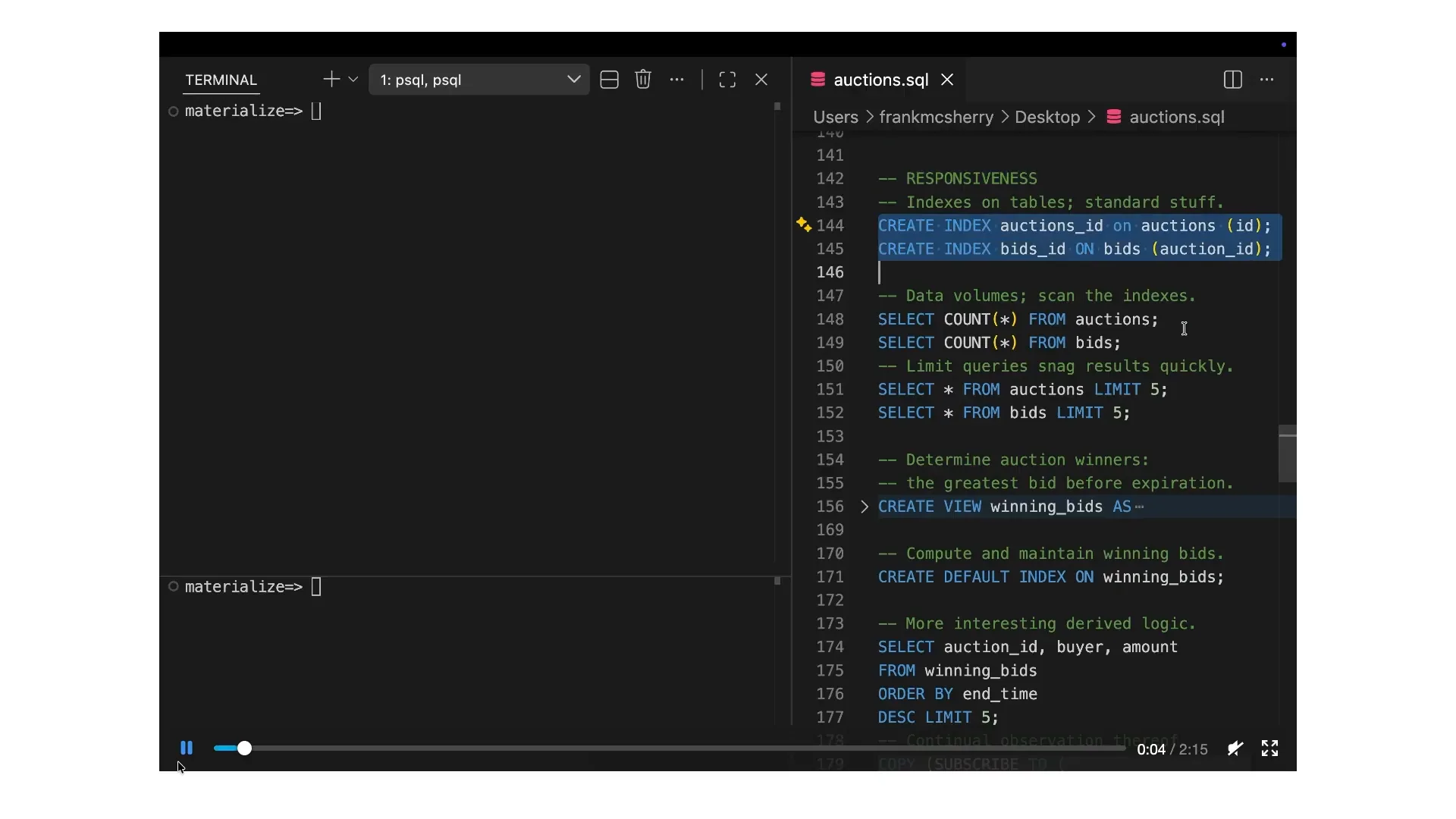 | You're going to see an amazing demo, and I'll narrate it to highlight key points in case some aspects are unclear. This screen provides a better view than the one further along, but I'll ensure to cover the main highlights. There are three key story beats in the demo that illustrate what Materialize does for you. The first is responsiveness. This is akin to a standard database where you can build indexes on your data. In our example, we have auctions and bids, and we will create indexes on them to quickly retrieve information. You’ll notice that the data comes back quickly. This demo is recorded from Virginia, while I am in New York, showcasing how data centers operate with multiple computers involved. We are pulling data from approximately 11 million bids, and the response times are impressive. However, this alone may not seem particularly exciting yet. |
Slide 6 — 9:20 (watch)
 | People have been indexing data for a long time, so there’s nothing particularly fascinating about that yet. However, Materialize takes a different approach by recognizing that most people don't want to look at raw data; data is often seen as boring and merely serves as input for more engaging business logic. For example, we have a winning bids view that combines auctions and bids through joins and aggregations to determine when an auction has closed and who the highest bidder was, based on bids submitted before the auction ended. This involves complex business logic to identify the auction winner. While optimizing indexes can help speed up this query, Materialize allows you to create an index on the results of this view, keeping them indexed in memory and continuously updated. In just a few milliseconds, we can retrieve the current results, which are live and changing. |
Slide 7 — 10:02 (watch)
 | It's admittedly synthetic data, but it's live and changing. I apologize for racing ahead in the demo to show you what's happening behind the scenes. |
Slide 8 — 10:42 (watch)
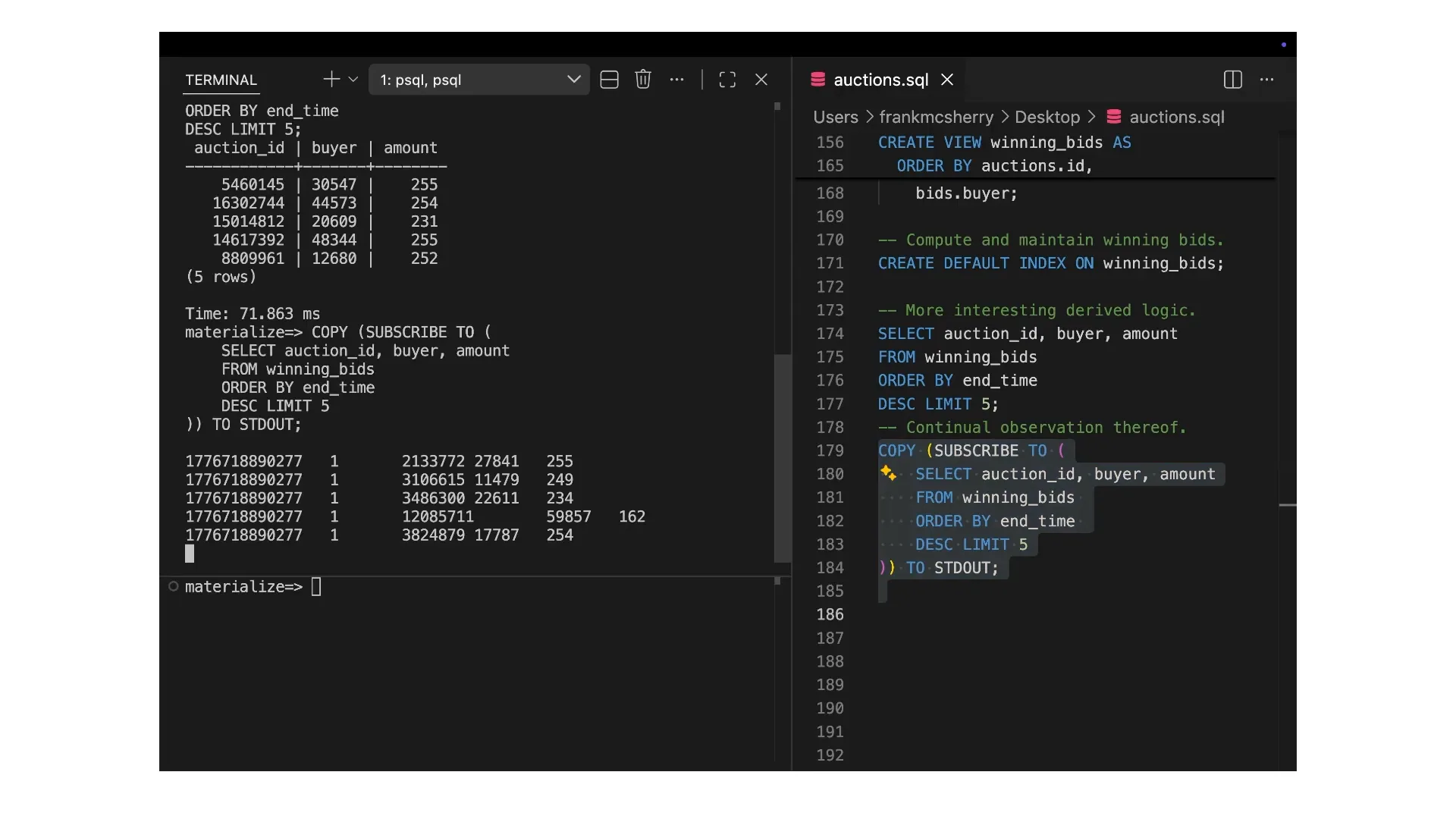
 | We are serving results, but behind the scenes, we maintain a continually evolving changelog. On the left-hand side of the screen, you can see timestamps in milliseconds since 1970, which is the standard way to represent time. The plus and minus signs indicate inserts and deletes, respectively, creating a changelog of the data. The first five elements in this list are plus ones, and this query is limited to five items, so only five entries are displayed at a time. If you examine it more closely, I can provide a deeper explanation offline if you're interested. The changes are coupled; plus ones and minus ones occur simultaneously when a record is inserted and another is ejected at the same time on the left-hand side. |
Slide 9 — 11:34 (watch)
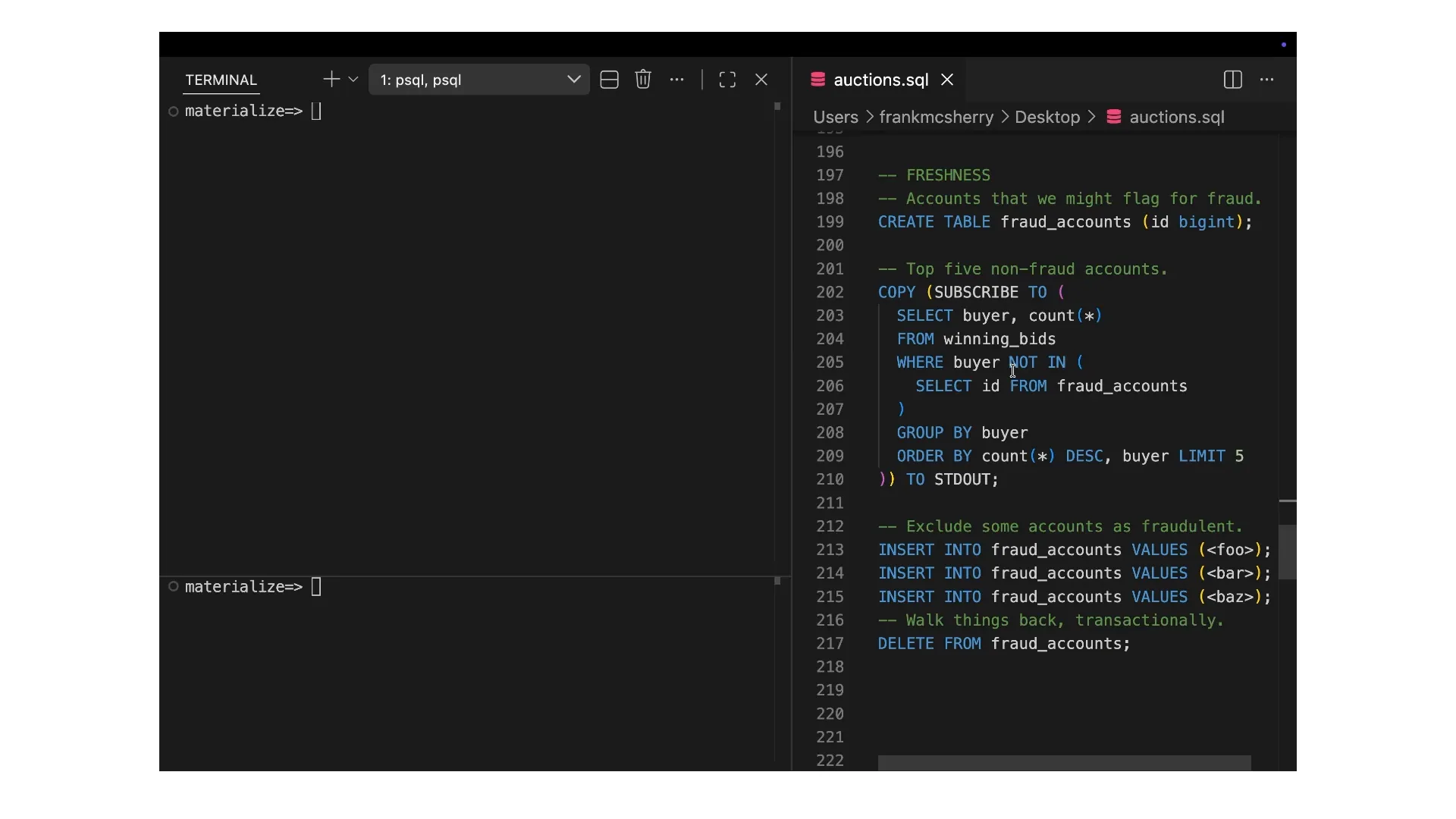 | This is essentially a very high-fidelity changelog of the system's activities. We will present this to you, providing a live feed of the business logic as it unfolds. This serves as the backbone of our technology, enabling us to transmit and communicate fresh data while maintaining correctness and consistency. The second key point is freshness. While the streaming data is impressive, it raises questions about delays. Is it five minutes behind? It's difficult to determine if the data is real or pre-recorded. I will show you another pre-recorded example where we interactively navigate the data. We will examine winning bids and identify the top buyers—those who are winning the most auctions. We have some concerns about potential fraudulent accounts, so we will introduce a new table for fraud accounts. Anyone in this table will be excluded from our list of big winners. Pay attention to how quickly this updates as we insert records into the fraud accounts table. |
Slide 10 — 12:44 (watch)
 | Do not count these accounts in our list of big winners. Watch how promptly this updates. In the lower left, we will insert some records into the fraud accounts table, which will trigger a change in the change log. Currently, the change log is static because we are viewing the top winners of bids by their account. It will change, but it is not live and updating. The individuals with seven and eight bids are not being overtaken by the most recent auction winners. We will take the account with eight bids, 55626, and add it to the fraud accounts. If you missed it, it was immediately removed from the list. The change that occurred was 55626 being excluded and 21259 being included. We will demonstrate this again to show that each time we add a new value to the fraud accounts, the change log updates immediately. |
Slide 11 — 13:10 (watch)
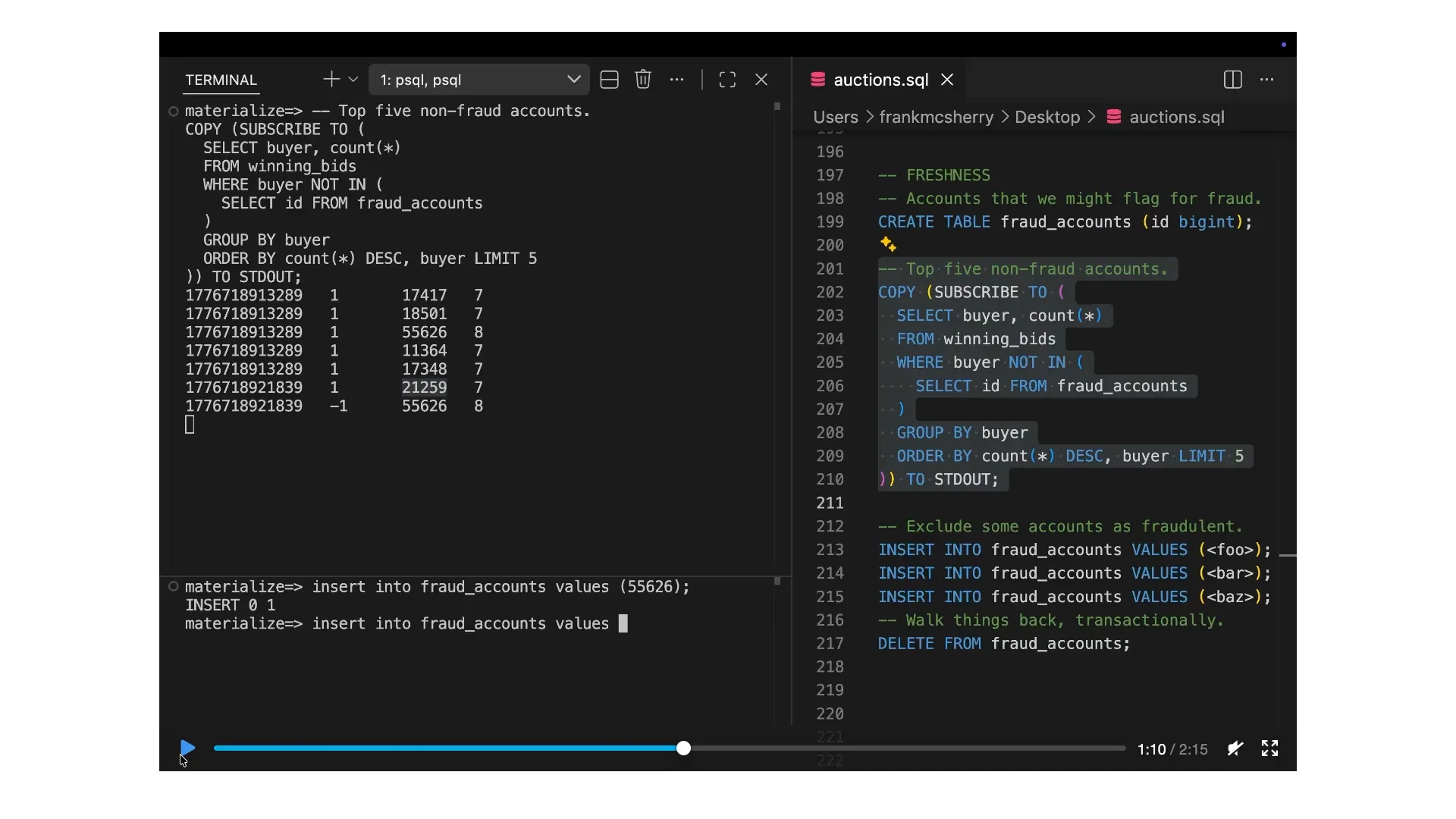 | Each time we add a new value to the fraud accounts, the change log updates immediately. If we decide this experiment was unnecessary, we can delete all three entries in the fraud accounts, removing any overrides. |
Slide 12 — 14:36 (watch)
 | It's a subtle but important point. We discard the most recently inserted element and revert to the original value of 55626. This is a transactional cutover from the end of our previous solutions back to the beginning. This leads us to the topic of materialize and consistency. In distributed systems, while updates can be fast and fresh, they often lead to inconsistencies. Numbers may not add up correctly because one process may complete faster than another. You could manage this concurrency issue yourself, but materialize aims to handle it for you. In our scenario, we have views of credits and debits: those who have won auctions need to pay (debits), and those selling items in auctions that have been won should receive credits. We’ve defined credits and debits separately and built indexes on them separately. Although they are currently running on the same machine, they could also run on separate machines. When we query the sum of all credits and the sum of all debits, they yield different results, which is unexpected. Ideally, these sums should be related and equal, just represented in two different ways. Given that the data is constantly changing, this discrepancy isn’t surprising. If we consider individual interactions with the data, changes can occur. However, when we combine the two sums—subtracting the sum of debits from the sum of credits—we find that the promotional material from Antithesis, or rather Bookbash, indicates zero slop. |
Slide 13 — 15:44 (watch)
 | I did not realize when I put this demo together that we have a column here for slop, and it is zero. It will always be zero. We will run this query a few more times. |
Slide 14 — 16:04 (watch)
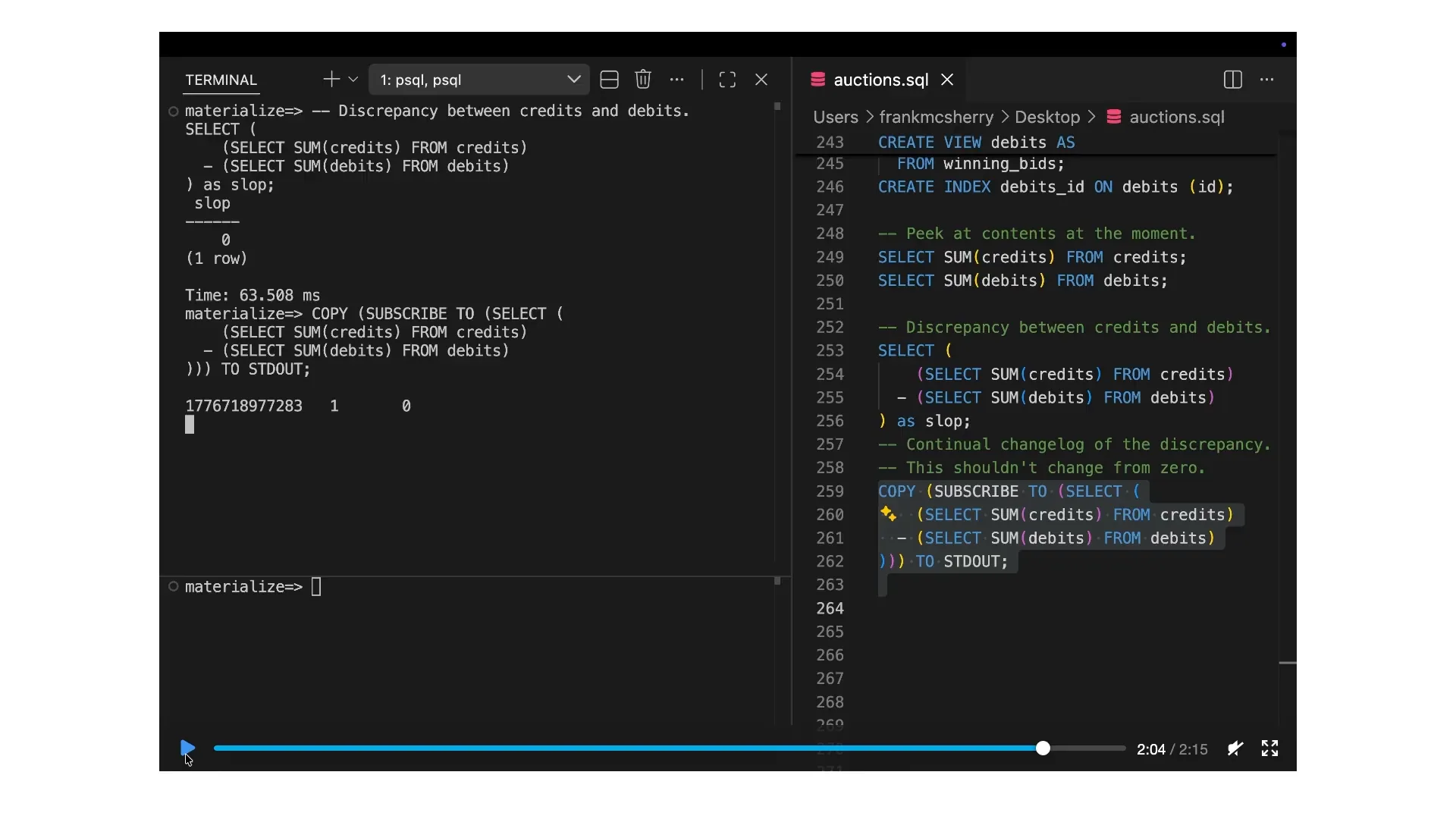 | The value is always zero, and I am so confident in this that we will set up a subscription to show the full changelog. I initially thought I needed to pause it, but it turns out that I don't need to. The changes will never occur. At this point, there is a single record with a value of zero. That's the answer, and let's observe it for a little while. |
Slide 15 — 16:28 (watch)
 | If this ever changed, it would be a P0 level bug at Materialize, indicating a fundamental correctness issue with the underlying infrastructure. Fortunately, I stopped the recording before that happened. |
Slide 16 — 16:42 (watch)
 | The goal of this presentation is to pique your interest in how to build confidence in the correctness of the information produced by Materialize. We aim to ensure that you can rely on the answers provided. Materialize's motto is "time to confident action," which emphasizes the importance of quickly delivering information that enables you to make decisions that are difficult to reverse. |
Slide 17 — 17:10 (watch)
 | First, let's determine if this is spicy. Systems that function effectively do so for a reason. This is crucial; they don't simply work because extensive testing was conducted. You need a clear rationale for why the system is designed to work. |
Slide 18 — 17:38 (watch)
 | Tests are a helpful part of ensuring that your implementation aligns with your intended reasons, but they are not the source of confidence. They contribute to absolute tests and the overall confidence narrative, but the foundation of confidence comes from a clear rationale. I view this as an abstraction that explains why things should work. |
Slide 19 — 18:28 (watch)
 | This quote is often used by practitioners who enjoy poking fun at the divide between theory and practice. As someone who started as a theoretician, I can relate. While you can read about theories, the distinction between theory and practice becomes evident in real-world applications. This is particularly true in the physical sciences; if your theory of gravity doesn't align with practical observations, your theory is flawed, and you need to revise it. However, computer systems, especially distributed systems, operate differently. We create practices, and if our constructed practice doesn't align with the theory, the system may still be incorrect. There isn't a universal truth dictating how a distributed system must function; it could simply be poorly designed. I want to acknowledge my early experiences at Microsoft Research in Silicon Valley, a distributed systems lab that brought together theoreticians and practitioners. They believed that any gap between theory and practice indicated an area needing improvement. I gained valuable insights as a naive theoretician who would use various distributed systems and question their behavior. The practitioners would often agree with my observations, not because I had deep knowledge of computers, but because my expectations were valid, and the systems should have behaved as anticipated. Therefore, narrowing the gap between the expected behavior and the actual performance is crucial for establishing and building confidence. |
Slide 20 — 19:30 (watch)
 | Materialize's reason for using virtual time is significant. I must pause here because I did not anticipate that many of you utilize virtual time. This concept, introduced in a 1985 paper by David Jefferson, is worth discussing. |
Slide 21 — 19:44 (watch)
 | The abstract presents two uses for virtual time. The first is in discrete event-based simulations, which many people are currently utilizing. The second use case is for concurrency control. |
Slide 22 — 19:56 (watch)
 | We will use virtual time for concurrency control. I will explain what that means, but the key takeaway is that it plays a crucial role in our system. |
Slide 23 — 20:02 (watch)
 | Materialize and its underlying stack function as a large-scale simulator. |
Slide 24 — 20:10 (watch)
 | It simulates computations that could occur instead of merely reacting to external stimuli. |
Slide 25 — 20:16 (watch)
 | It is performing a prescribed sequence of computations. |
Slide 26 — 20:20 (watch)
 | We previously observed this on the screen. |
Slide 27 — 20:30 (watch)
 | The backbone of Materialize consists of continually changing and evolving changelogs. These changelogs evolve only in the append sense, allowing us to learn more about our underlying data. |
Slide 28 — 20:40 (watch)
 | We represent them as triples, often with slight variations. In this case, we are dealing with time difference data, which we previously displayed on the big screen. |
Slide 29 — 20:44 (watch)
 | We have time stamps, plus or minus ones, and some record payloads. |
Slide 30 — 20:50 (watch)
 | As these collections evolve and grow in length, they provide a specific understanding of their contents at particular moments in time. |
Slide 31 — 21:00 (watch)
 | You accumulate all the changes up to the specified time, summing the depths for each piece of data. Any data with a non-zero depth is included in your dataset with that multiplicity. |
Slide 32 — 21:12 (watch)
 | It may seem unusual to add to a negative number, but it is entirely feasible. The backbone of Materialize is its continual changelog. |
Slide 33 — 21:16 (watch)
 | Is this just an accounting technique? |
Slide 34 — 21:20 (watch)
 | No, it's not just about writing things down and being done. |
Slide 35 — 21:28 (watch)
 | Materialize uses changelogs as the nouns, while the verbs act on these changelogs to transform them. For example, we have a changelog describing some input data, referred to as input zero. Someone might then decide to filter this data. |
Slide 36 — 21:44 (watch)
 | This could represent a collection of data about people, where the filter specifies that we want to retain only those individuals whose ages are even. |
Slide 37 — 22:02 (watch)
 | There is a computational problem when given an input changelog with explicit timestamps, including additions and deletions of data. The filter operator must produce a corresponding changelog in its output as if time were frozen at every moment. It integrates the input, identifies the collection, retains only those individuals whose ages are even, and then differentiates the output to find the changes needed to reproduce it. This result is then included in the output of the filter. |
Slide 38 — 22:22 (watch)
 | You can apply this to various types of operators, such as map, join, and reduce, which are fundamental to data parallelism in computation. The exciting aspect is that due to the precise high-fidelity match between the input changelog and the output changelog, these components function like Lego bricks. |
Slide 39 — 22:30 (watch)
 | You can start connecting them easily. |
Slide 40 — 22:34 (watch)
 | If you filter input zero and then map a function onto input one, joining the two together and reducing them, it simulates the process of going through input one and input zero, freezing time at every moment, integrating the results, and then applying filter, map, join, and reduce before differentiating the output. |
Slide 41 — 22:46 (watch)
 | That property holds true regardless of your familiarity with distributed systems. |
Slide 42 — 23:04 (watch)
 | Even if you are not experienced with distributed systems, as a data scientist or business analyst, you can use SQL to assemble interesting and relevant data without worrying about correctness or the complexities of asynchronous computation. |
Slide 43 — 23:18 (watch)
 | This approach is very useful. The certainty regarding the equivalences between inputs and outputs allows for confident assembly of all components. |
Slide 44 — 23:26 (watch)
 | Moreover, the SQL plans themselves, and the computations at any scale, also compose effectively. |
Slide 45 — 23:38 (watch)
 | If you have a piece of business logic and someone else in an adjacent room has a different piece of business logic, both of you can execute your logic simultaneously. A third person can then take your results and combine them, ensuring consistency at all times. |
Slide 46 — 23:48 (watch)
 | It will always be as if the input data was taken, frozen, both pieces of logic were executed, and then the third person's logic was applied to produce the change log for the results. |
Slide 47 — 24:08 (watch)
 | This approach alleviates much of the complexity for users who want to perform data analysis using SQL or any other language. The goal of building confidence is significant; it is not solely based on speed or a complex locking discipline. |
Slide 48 — 24:24 (watch)
 | From a systems perspective, in large and complex distributed systems, we discussed determinism and non-determinism yesterday. One way to approach this is to recognize that Materialize resolves much of the non-determinism at the system's boundary. |
Slide 49 — 24:34 (watch)
 | Materialize allows you to perform many operations within the confines of the system. You can choose how to assemble these components, and they are largely deterministic at that stage. |
Slide 50 — 24:46 (watch)
 | The computation's result is determined by the resolution of these change logs at the boundary as data is brought in from PostgreSQL, MySQL, and other sources. While I initially suggested that the unfolding of the computation is deterministic, that is not entirely accurate. |
Slide 51 — 24:56 (watch)
 | From a system perspective, it effectively removes logical contention. |
Slide 52 — 25:12 (watch)
 | It eliminates complicated coordination and synchronization issues that could lead to multiple outcomes at runtime. This simplifies the challenge to a performance question: how to optimize speed. |
Slide 53 — 25:22 (watch)
 | While there is a potential for correctness issues, the design aims to prevent users from making mistakes. |
Slide 54 — 25:34 (watch)
 | A key distinction to address is between virtual time as a concurrency control mechanism and logical clocks. Many people are familiar with the concept of time and clocks, and they often think they understand logical clocks. |
Slide 55 — 25:48 (watch)
 | You're probably thinking of a vector clock or a Lamport clock. |
Slide 56 — 25:58 (watch)
 | The fundamental difference here is that virtual time is a prescriptive technique, while logical clocks are descriptive. Virtual time introduces structure and eliminates certain options. |
Slide 57 — 26:06 (watch)
 | The system now has significantly fewer degrees of freedom than before, which also simplifies its complexity. |
Slide 58 — 26:12 (watch)
 | Users of the system no longer have to deal with certain issues that could have arisen, which can be a relief. |
Slide 59 — 26:22 (watch)
 | Logical clocks, in my view, do not reduce complexity; rather, they transcribe it. |
Slide 60 — 26:38 (watch)
 | They remove ambiguity. While logical clocks indicate that certain events did not occur, this can be a relief. However, programming with logical clocks can be challenging. If I provided you with a logically clocked change log and asked you to derive the correct answer, you would need to understand logical clocks, which are quite complex. I wanted to highlight this distinction as it leads into the next topic about building competence. |
Slide 61 — 27:00 (watch)
 | I spent a lot of time thinking about my professional goals. Initially, I believed that my aim was to be perceived as a really smart person, showcasing my intelligence on stage. |
Slide 62 — 27:16 (watch)
 | Ultimately, what are computer scientists uniquely good at? Where do we truly provide value? |
Slide 63 — 27:24 (watch)
 | In my personal experience, effective abstraction has been a key strength. There are many opportunities for talented individuals in various fields. |
Slide 64 — 27:30 (watch)
 | One of our strengths is our ability to take complex systems and reduce their surface area, making them easier and more accessible for those who prefer not to engage with that complexity. |
Slide 65 — 27:42 (watch)
 | In mathematics, a 150-page paper can be met with enthusiasm, and a 200-page paper is often praised even more. |
Slide 66 — 27:50 (watch)
 | What we actually find is that none of our customers want to read anything that's 200 pages long. They prefer things to be simple, easy, and functional. My computer contains a lot of complex silicon that I do not understand. |
Slide 67 — 28:06 (watch)
 | The operating system is complicated. While its complexity is fascinating for those who want to explore it, I prefer to focus on delivering a presentation. It is powerful to conceal that complexity, allowing people to engage without having to worry about it. |
Slide 68 — 28:16 (watch)
 | It's not necessarily as interesting. Many of you may be thinking that you want complexity. |
Slide 69 — 28:24 (watch)
 | We aim to remove complexity for others, which is a key aspect of the service we provide. We often receive recognition and compensation for achieving this goal. |
Slide 70 — 28:38 (watch)
 | Virtual time is a great abstraction. While it can be challenging to implement correctly, it is not overly complicated. However, it is easy to misuse if not handled properly. |
Slide 71 — 28:50 (watch)
 | If someone gives you a collection of pieces, like Lego bricks, and asks you to build something, you likely wouldn't do anything reckless. You wouldn't use a hammer to smash them together or a blowtorch to melt the pieces. |
Slide 72 — 28:56 (watch)
 | The components fit together nicely and logically. |
Slide 73 — 29:00 (watch)
 | You obtain a result that you understand. |
Slide 74 — 29:04 (watch)
 | You may not fully understand how it works or why it produces the correct answer, but you appreciate that it does. It's a relief not to have to learn about distributed systems to use this effectively. |
Slide 75 — 29:22 (watch)
 | We will now discuss a few vignettes related to the abstraction of virtual time. This abstraction is beneficial not only for users but also for other system-building functions. |
Slide 76 — 29:32 (watch)
 | Several aspects are easy to materialize, but they are more straightforward than they would be in a complicated system that exposes all its internals. In such a system, careful handling is required for everything to function properly. |
Slide 77 — 29:38 (watch)
 | We can demonstrate active replication at the end of the previous section. |
Slide 78 — 29:46 (watch)
 | All forms of parallelism are generally relatively straightforward, though I hesitate to say they are easy. |
Slide 79 — 29:52 (watch)
 | Task parallelism is relatively straightforward, although it can be challenging to define. |
Slide 80 — 29:56 (watch)
 | If five people want to use the same changelog, they can proceed without hesitation. You'll receive consistent answers at the end. |
Slide 81 — 30:10 (watch)
 | Differential data flow is based on data parallelism, allowing workers to operate without continuous coordination. This enables them to work efficiently and focus on their tasks without confusion about what to do next. |
Slide 82 — 30:24 (watch)
 | Pipeline parallelism is a prime example of where virtual time excels. In a sequence of tasks A, B, and C, task B cannot start until task A has completed a portion of its work. |
Slide 83 — 30:34 (watch)
 | Virtual time records the intended start time for tasks, even if it takes a minute or so before they can actually begin. |
Slide 84 — 30:40 (watch)
 | Pipelining is not easy, but it is relatively straightforward. Queries, which are another form of interaction with the system, receive virtual times. |
Slide 85 — 30:52 (watch)
 | This approach provides serialization by default. The system maintains a total order on time, meaning that every request you make is associated with a specific time, and you receive the answer exactly as of that time. |
Slide 86 — 31:02 (watch)
 | If you have specific requirements for time, such as a minimum lower bound, you can achieve strict serialization. |
Slide 87 — 31:08 (watch)
 | A notable property is that you achieve something stronger than serialization: composable strict serializability. |
Slide 88 — 31:16 (watch)
 | By revealing these timestamps, multiple users can combine two strict serializable databases to create a third one. While this might seem straightforward, I prefer not to rely on that approach. |
Slide 89 — 31:32 (watch)
 | With virtual times, their structure is revealed in a way that allows for composition, enabling the creation of even more fascinating composed systems. |
Slide 90 — 31:44 (watch)
 | Errors in these systems often manifest as data. |
Slide 91 — 31:54 (watch)
 | An error does not interrupt the system or prevent you from performing an action. For example, if you encounter a divide by zero error, the system will indicate that an error occurred at a specific virtual time. If you remove that record from the input, the error will disappear at the exact moment you remove it. This behavior is quite useful. |
Slide 92 — 32:10 (watch)
 | Integrity constraints in streaming systems or cloud data warehouses are often unreliable because the timing of when data lands in the environment is unpredictable. Primary and foreign key relationships do not hold, so it's advisable to use left joins everywhere. However, systems like Materialize maintain these properties, allowing you to convert all outer joins to inner joins with confidence. |
Slide 93 — 32:24 (watch)
 | Finally, active replication, which I will demonstrate, effectively functions as deduplication. |
Slide 94 — 32:34 (watch)
 | In a scenario where multiple people are performing the same task, you only need one of them to provide the correct answer. Once that person informs you of the next item in your change log, you can proceed with confidence, even if one of the team members is unavailable. |
Slide 95 — 32:50 (watch)
 | As long as you have one person doing the work, it gets done. I had a few other examples, but the stories are valuable. When you simplify your processes, everything becomes easier. Some tasks are challenging. At the end of the talk, feel free to ask me about what was difficult, and I might have to navigate that question carefully. |
Slide 96 — 33:00 (watch)
 | Here’s a quick demonstration of active replication. |
Slide 97 — 33:20 (watch)
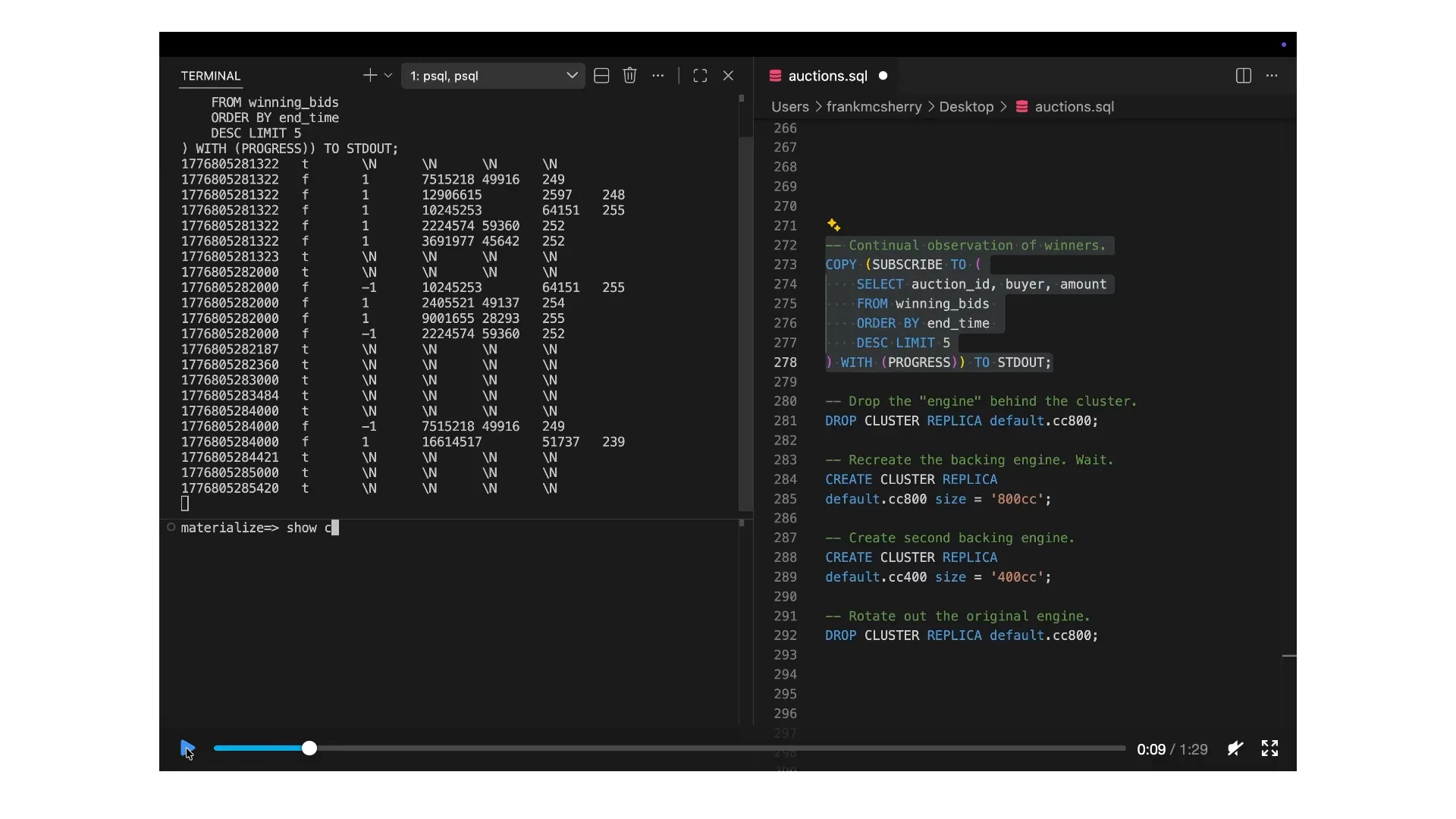 | We are performing the same operation as before, focusing on the winning bids. We'll use a modifier for this command to illustrate the presence of several nulls, indicated by the slash ends. This modifier ensures a steady heartbeat in the background, even if no changes occur. This ticking serves to remind the audience that time is progressing. We will include this feature because we plan to break some components and observe the outcomes. As this process continues, Materialize maintains what are known as cluster replicas behind the scenes. |
Slide 98 — 33:40 (watch)
 | A cluster defines the computation you want, while the replicas are the engines that produce the results. |
Slide 99 — 33:48 (watch)
 | You can have any number of replicas, including zero. One is a common choice, and two is also possible. However, having zero is usually a mistake, but we will proceed with that configuration. |
Slide 100 — 34:02 (watch)
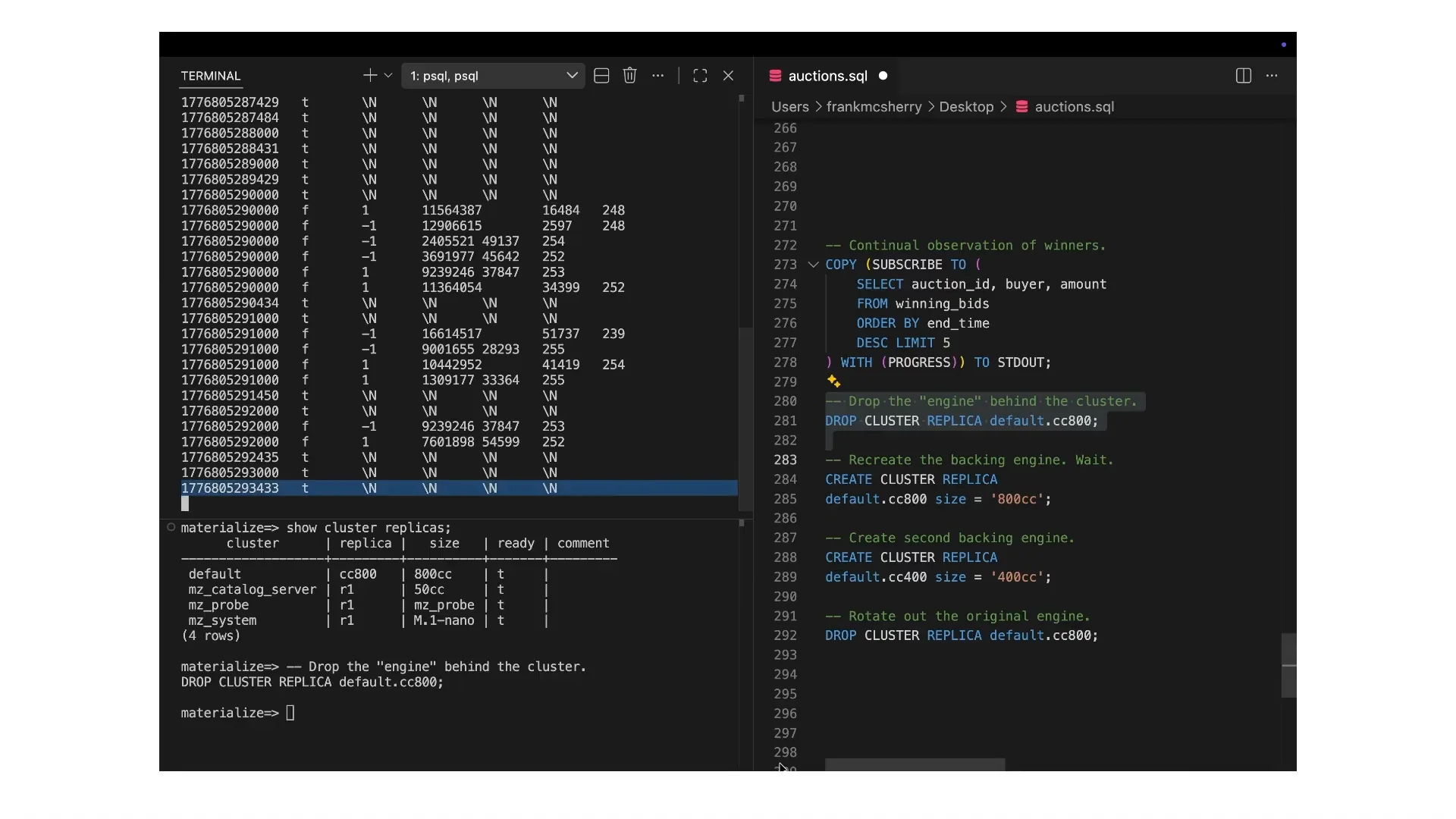 | Here we have the default cluster that this is running on. We just dropped a replica, which has caused the highlighted line to stop changing. This behavior is unexpected. |
Slide 101 — 34:12 (watch)
 | This behavior is exactly what you want in a virtually timed system. We cannot predict what will happen next. |
Slide 102 — 34:18 (watch)
 | In particular, we cannot assume that nothing has changed. While we can't definitively say that this is the wrong answer, we are not yet certain that it is the correct one. |
Slide 103 — 34:22 (watch)
 | We need to pause the feed. |
Slide 104 — 34:28 (watch)
 | It needs to stop, and it's clear that it has. As consumers, we are left wondering what comes next, but the system indicates that it doesn't know. |
Slide 105 — 34:52 (watch)
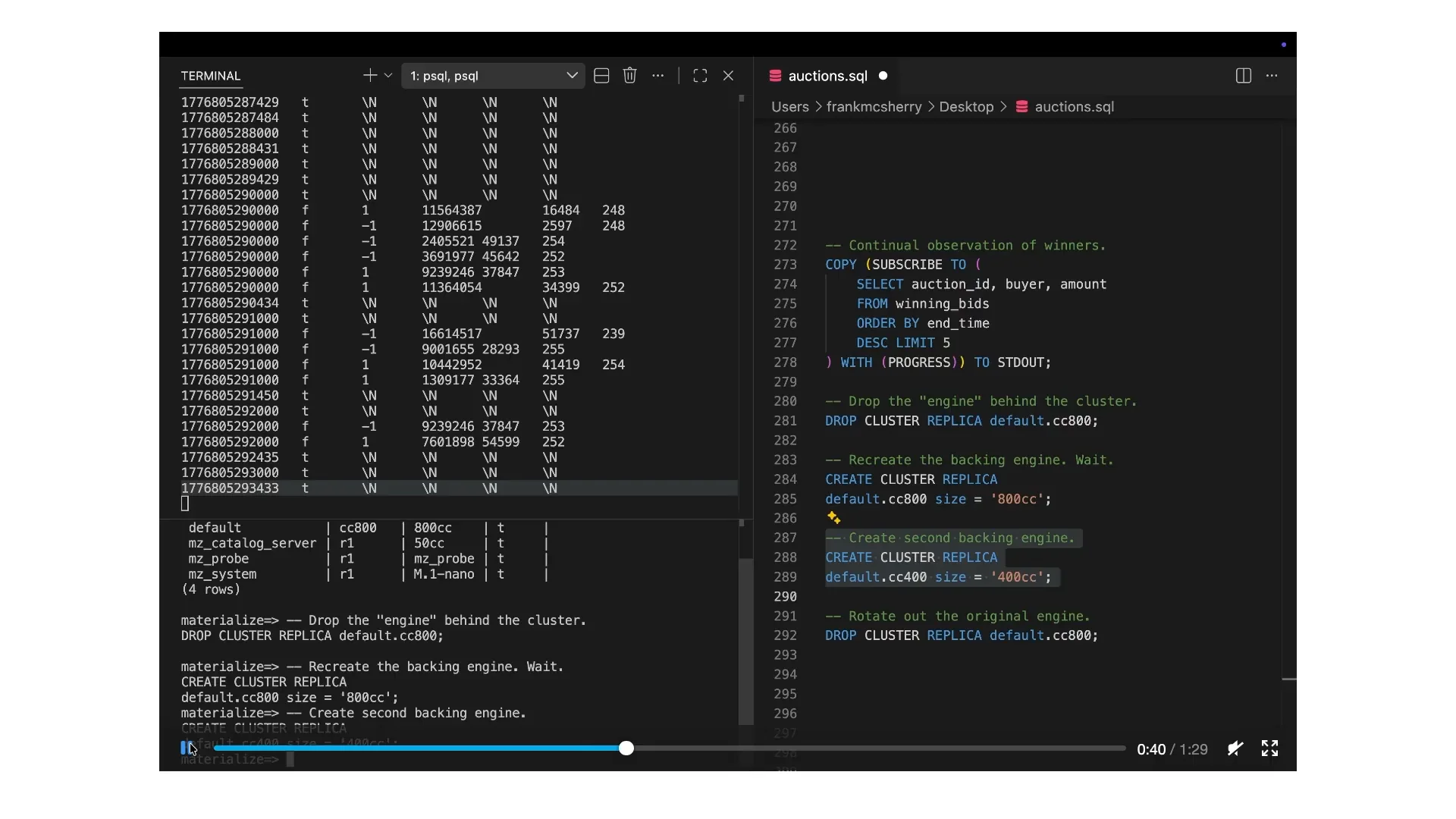 | We are unsure why the system is not responding, but we suspect it may not have the necessary information. Behind the scenes, we are creating new replicas and bringing them back online. I will explain what happens as a replica resumes its operations. Additionally, I am starting a second replica, so I want to give you a heads-up about a subsequent action we will take. Currently, the first replica is coming back online; it needs to rehydrate its data flows and start pulling down the change logs to get back up to speed. Once it does, which just happened, we will pause it for a moment. The highlighted line indicates where we paused. |
Slide 106 — 35:14 (watch)
 | If you look closely at the numbers, you may find them tricky to see, but the change log is essentially uninterrupted. |
Slide 107 — 35:22 (watch)
 | We observed an interruption on our end, but the change log as data remains essentially uninterrupted, as if we had continued running without pause. |
Slide 108 — 35:32 (watch)
 | If we had the same computation running on a different cluster without interruption, we would see the same information in the same order, accounting for the minute-long pause during which no data was processed. |
Slide 109 — 35:58 (watch)
 | We have two replicas running: a 400cc and an 800cc, which are our internal units. The 400cc is half the size of the 800cc. We will drop the 800cc, but this time we have a backup with the 400cc operational. It takes me a moment to gain the confidence to press the button, but once we stop the 800cc, the system continues running. We have successfully performed a live migration from the 800cc to the 400cc without interruption, aside from the brief moment I demonstrated the interruption. This process allows us to reconfigure the physical components of the system and transition from one class of machine to another seamlessly. |
Slide 110 — 36:24 (watch)
 | This approach enables zero downtime physical replication, which is a principle that applies in various other settings as well. |
Slide 111 — 36:40 (watch)
 | Logical reconfiguration allows you to change the business logic of your view. Transitioning from one configuration to another is challenging, but not unexpected. |
Slide 112 — 36:54 (watch)
 | The final point I want to make is brief, as this is the last slide. |
Slide 113 — 37:08 (watch)
 | There are fewer demos in this section, and while "hand wave" might not be the right term, I feel strongly about these concepts. Identifying reasons why technology should work and creating abstractions can be indulgent. It's not necessarily easy, but it is a process that helps build your own confidence. |
Slide 114 — 37:18 (watch)
 | Building confidence involves figuring out how to transfer that confidence to others. Sharing your personal conviction about a technology is interesting, but my focus is on how to communicate that effectively to others. |
Slide 115 — 37:32 (watch)
 | As a user or participant in your technology, I want to understand its value. Convince me, not just yourself. Everyone you interact with should ask the same question: convince me. I want to be involved and understand what’s happening, or know where I don’t need to engage, which is also acceptable. |
Slide 116 — 37:44 (watch)
 | I recommend three key things, and this is not an exhaustive list. |
Slide 117 — 37:58 (watch)
 | Drug footing is crucial. Use the system you are building; if you don't use it, I doubt the validity of anything you say about it. |
Slide 118 — 38:08 (watch)
 | It is easy to realize how wrong your assumptions can be once you start using these systems. You may find that you have completely missed the challenges associated with these technologies. Therefore, use them extensively to test your theories and determine if your reasoning holds true, particularly regarding their potential to simplify processes for everyone downstream. |
Slide 119 — 38:22 (watch)
 | Benchmarking is something I strongly advocate for. |
Slide 120 — 38:30 (watch)
 | I focus on performance-related work, and if that’s not your area, this may be less relevant. However, I encourage you to try to break your system. |
Slide 121 — 38:40 (watch)
 | Everyone involved in structural engineering understands the point at which steel bends. Similarly, if you don't know the limits of your system, I doubt it will withstand significant stress. |
Slide 122 — 39:00 (watch)
 | Challenge yourself by attempting to break things and identify their weaknesses. Avoid relying solely on the easiest benchmarks; instead, engage in tests that may complicate your work. |
Slide 123 — 39:04 (watch)
 | The good news is that if you conduct thorough testing, you'll discover not only the weaknesses in your own system but also in others' systems. |
Slide 124 — 39:16 (watch)
 | This approach is beneficial, especially if your goal is to tell a compelling story. You will create an extensive checklist that prompts questions like, "Can you accomplish this?" or "This seems challenging; I doubt you can do it." If you can succeed, it will certainly pique interest, and others will want to learn how you achieved it. |
Slide 125 — 39:26 (watch)
 | It’s important to thoroughly test systems to identify their weaknesses. Additionally, effective communication is crucial; engage with others about ongoing developments. |
Slide 126 — 39:38 (watch)
 | I have historically written many blog posts, and often, while writing about a fascinating idea, I find myself halfway through realizing that it’s not a good idea at all. |
Slide 127 — 39:54 (watch)
 | I'm trying to explain how good an idea is, but the explanation requires balancing many different elements. Often, I end up deleting the post and going back to improve it. |
Slide 128 — 40:00 (watch)
 | The exercise of trying to communicate and bring others on board is essential. |
Slide 129 — 40:10 (watch)
 | Explaining how simple and easy this process can be is not only valuable work but also informative. It tests the theory that this information is worthwhile and genuinely simplifies people's lives. |
Slide 130 — 40:26 (watch)
 | In conclusion, when we think about building confidence, I encourage everyone to view it as something you provide to others. It's important to understand that confidence is not solely a technical issue; it is not something that a piece of software can solve for you. |
Slide 131 — 40:36 (watch)
 | Building confidence is a process that involves many components working together to achieve a functional outcome. |
Slide 132 — 41:04 (watch)
 | As an example, 20 years ago at Microsoft, I had a colleague in the algorithm space who worked on theoretical computer science, algorithms, and data structures. He suggested to Jim Gray that more people should focus on fundamental algorithms and data structures, emphasizing their importance. Jim Gray responded, conveying that everyone is indeed working on algorithms and data structures; it’s just that my colleague had not yet found a specific purpose for his work. This raises the question: why are you doing it? Are you building confidence for a reason? |
Slide 133 — 41:22 (watch)
 | Is your goal to build confidence for others, or is it for yourself? Are you engaging in a self-indulgent study? |
Slide 134 — 41:32 (watch)
 | Software reliability can easily lead to the misconception that one can create highly reliable systems in the abstract, without considering the true implications of what reliability entails. |
Slide 135 — 41:40 (watch)
 | Reliability has different meanings depending on the context; for example, it differs significantly for a self-driving car compared to a pacemaker. |
Slide 136 — 41:46 (watch)
 | One of these systems should shut down carefully and in a controlled manner, while the other absolutely should not. One of the main reliability questions we haven't addressed is related to performance. |
Slide 137 — 41:54 (watch)
 | With Black Friday approaching, will Materialize remain operational as I conduct business? |
Slide 138 — 42:04 (watch)
 | It's unlikely that the software will crash, but we do encounter glitches that are less about computing the wrong results and more about non-functional requirements. For instance, we might not anticipate that a particular collectible doll would become extremely popular, leading to unexpected issues, such as overheating components. |
Slide 139 — 42:16 (watch)
 | A crucial aspect of reliability involves design bugs rather than pointer access bugs or similar issues. |
Slide 140 — 42:30 (watch)
 | Understanding reliability involves considering its meaning for others beyond yourself. It's essential to adopt a broader perspective on reliability, identify who needs to be convinced, and clarify what you need to convince them of. |
Slide 141 — 42:38 (watch)
 | I'll pause here. We have time for one or two questions. If the questions are particularly challenging, we may have less time to address them. |
Slide 142 — 43:00 (watch)
 | Abstraction is a powerful concept, and the idea of virtual time is a strong example of this. The key point is about monotonicity. How did you develop the virtual time abstraction? Additionally, what tips can you share for creating effective abstractions? What is the process? Those are challenging questions. |
Slide 143 — 43:20 (watch)
 | To be clear, I did not develop the concept of virtual time; that was done by Jefferson in the 1980s. |
Slide 144 — 43:40 (watch)
 | I arrived at the concept primarily through my experiences with streaming, where the idea of event time is prevalent. Unlike databases, streaming systems have a unique property: they allow an external source to dictate the sequence of events. In a streaming system, events arrive with timestamps, indicating when a particular sensor recorded a specific value. |
Slide 145 — 43:54 (watch)
 | I apologize that you didn't hear about it until now, but this is how it actually needs to work. |
Slide 146 — 44:00 (watch)
 | In the background of much of the streaming work, event time has been a key concept. When unpacked, it essentially represents virtual time. This idea was not fundamentally new; it already existed prior to our current discussions. |
Slide 147 — 44:44 (watch)
 | Much of my work has focused on the concept of composability. If a concept only works once and requires precise conditions to function, I find it lacks lasting value. Differential privacy exemplifies this; while there are many definitions of privacy, they often lack composability. When you combine two definitions, they typically lose their properties, which is unfortunate. One appealing aspect of differential privacy is its composability; even non-experts can use it effectively, and it remains functional despite their lack of sophisticated understanding. This serves as an important litmus test for whether a good abstraction has been created. However, it's not a foolproof recipe. If I had a definitive recipe, I wouldn't share it; I would be collaborating with Claude to explore every field of study. There are ways to evaluate abstractions: you can ask why you thought a particular abstraction was effective and why it ultimately failed. Consider whether it addressed the problem people faced or if users struggled to utilize it. These rhetorical questions can help identify where things went wrong. |
Slide 148 — 45:18 (watch)
 | This may take longer than our available time, but the cost paper discusses evaluating distributed systems against poor baselines, specifically a strong single-threaded baseline. We need to consider how to adapt this concept to software correctness. What should developers prioritize before engaging in elaborate testing? Is it a strong type system? What is the baseline in this context? |
Slide 149 — 46:54 (watch)
 | This is a great question, and I don't have a quick answer. I could talk at length about this and likely be wrong repeatedly. However, one thing I see missed often is what formal methods provide: clarity on what the system was supposed to do in the first place. For example, when I saw a statistic that people spend 50% of their time programming and 50% testing, I wondered when the thinking happens. It's crucial to consider what the system is supposed to accomplish and to document that. My experience, and the general wisdom, is that when you engage in formal modeling, you may eventually prove something, but most bugs surface while trying to articulate the specification. This process often reveals gaps in understanding. For me, using Rust has been particularly helpful. Its type system and trait system allow for greater precision. The type system can point out inconsistencies, such as claiming something is a lattice while attempting to perform operations that don’t align with that definition. It’s essential to ensure that the components fit together before diving into complex solutions. There can be a temptation to seek quick fixes, but if you don’t fully understand the problem, it’s better to step back and reassess where things went wrong. Instead of relying on quick solutions, consider using a stronger programming language. Transitioning from C to a more robust language can often resolve many issues, though results may vary. |
Slide 150 — 47:58 (watch)
 | Thank you. |
Slide 151 — 48:14 (watch)
 | Thank you. |